返回值
return 返回值要点:
1. 如果函数体中包含return 语句,则结束函数执行并返回值;
2. 如果函数体中不包含return 语句,则返回None 值。
3. 要返回多个返回值,使用列表、元组、字典、集合将多个值“存起来”即可。
def my_avg(a,b):
return (a+b)/2
def test(x,y,z)
return [x*10,y*10,z*10]
print(test(1,2,3))


返回值
return 返回值要点:
1. 如果函数体中包含return 语句,则结束函数执行并返回值;
2. 如果函数体中不包含return 语句,则返回None 值。
3. 要返回多个返回值,使用列表、元组、字典、集合将多个值“存起来”即可。
def my_avg(a,b):
return (a+b)/2
def test(x,y,z)
return [x*10,y*10,z*10]
print(test(1,2,3))
形参和实参
def printMax(a,b):
'''实现两个数的比较,并返回较大的值'''
if a>b:
print(a,'较大值')
else:
print(b,'较大值')
printMax(10,20)
printMax(30,5)
执行结果:
20 较大值
30 较大值
上面的printMax 函数中,在定义时写的printMax(a,b)。a 和b 称为“形式参数”,
简称“形参”。也就是说,形式参数是在定义函数时使用的。形式参数的命名只要符合“标
识符”命名规则即可。
在调用函数时,传递的参数称为“实际参数”,简称“实参”。上面代码中,
printMax(10,20),10 和20 就是实际参数。
文档字符串(函数的注释)
我们通过三个单引号或者三个双引号来实现,
def print_star(n):
'''根据传入的n,打印多个星号'''
print("*"*n)
help(print_star)
我们调用help(函数名.__doc__)可以打印输出函数的文档字符串。执行结果如下:
Help on function print_star in module __main__:
print_star(n)
根据传入的n,打印多个星号
Python 函数的分类
Python 中函数分为如下几类:
1. 内置函数
我们前面使用的str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。
2. 标准库函数
我们可以通过import 语句导入库,然后使用其中定义的函数
3. 第三方库函数
Python 社区也提供了很多高质量的库。下载安装这些库后,也是通过import 语句导
入,然后可以使用这些第三方库的函数
4. 用户自定义函数
用户自己定义的函数,显然也是开发中适应用户自身需求定义的函数。今天我们学习的
就是如何自定义函数。
函数的定义和调用
def 函数名([参数列表]) :
'''文档字符串'''
函数体/若干语句
要点:
1. 我们使用def 来定义函数,然后就是一个空格和函数名称;
(1) Python 执行def 时,会创建一个函数对象,并绑定到函数名变量上。

2. 参数列表
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应
3. return 返回值
(1) 如果函数体中包含return 语句,则结束函数执行并返回值;
(2) 如果函数体中不包含return 语句,则返回None 值。
4. 调用函数之前,必须要先定义函数,即先调用def 创建函数对象
(1) 内置函数对象会自动创建
(2) 标准库和第三方库函数,通过import 导入模块时,会执行模块中的def 语句
我们通过实际定义函数来学习函数的定义方式。
推导式创建序列
推导式是从一个或者多个迭代器快速创建序列的一种方法。它可以将循环和条件判断结合,
从而避免冗长的代码。
列表推导式
列表推导式生成列表对象,语法如下:
[表达式for item in 可迭代对象]
或者:{表达式for item in 可迭代对象if 条件判断}
>>> [x*2 for x in range(1,20) if x%5==0 ]
[10, 20, 30]
>>> [a for a in "abcdefg"]
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> cells = [(row,col) for row in range(1,10) for col in range(1,10)]
字典推导式
{key_expression : value_expression for 表达式in 可迭代对象}
类似于列表推导式,字典推导也可以增加if 条件判断、多个for 循环。
>>> my_text = ' i love you, i love sxt, i love gaoqi'
>>> char_count = {c:my_text.count(c) for c in my_text}
>>> char_count
{' ': 9, 'i': 4, 'l': 3, 'o': 5, 'v': 3, 'e': 3, 'y': 1, 'u': 1, ',': 2, 's': 1, 'x': 1, 't': 1, 'g': 1, 'a': 1, 'q': 1}
集合推导式
集合推导式生成集合,和列表推导式的语法格式类似:
{表达式for item in 可迭代对象}
或者:{表达式for item in 可迭代对象if 条件判断}
>>> {x for x in range(1,100) if x%9==0}
{99, 36, 72, 9, 45, 81, 18, 54, 90, 27, 63}
生成器推导式(生成元组)
很多同学可能会问:“都有推导式,元组有没有?”,能不能用小括号呢?
>>> (x for x in range(1,100) if x%9==0)
<generator object <genexpr> at 0x0000000002BD3048>
我们发现提示的是“一个生成器对象”。显然,元组是没有推导式的。
一个生成器只能运行一次。第一次迭代可以得到数据,第二次迭代发现数据已经没有了。
>>> gnt = (x for x in range(1,100) if x%9==0)
>>> for x in gnt: #生成器是可迭代对象
print(x,end=' ')
9 18 27 36 45 54 63 72 81 90 99
>>> for x in gnt:
print(x,end=' ')
>>>
使用zip()并行迭代
zip()函数对多个序列进行并行迭代,zip()函数在最短序列“用完”时就会停止。
names = ("高淇","高老二","高老三","高老四")
ages = (18,16,20,25)
jobs = ("老师","程序员","公务员")
for name,age,job in zip(names,ages,jobs):
print("{0}--{1}--{2}".format(name,age,job))
执行结果:
高淇--18--老师
高老二--16--程序员
高老三--20--公务员
#或者直接
for i in range(3) print("{0}-{1}- {2}".format(names[i],ages[i],jobs[i]))
循环代码优化
1. 尽量减少循环内部不必要的计算
2. 嵌套循环中,尽量减少内层循环的计算,尽可能向外提。
3. 局部变量查询较快,尽量使用局部变量
(尽量减少循环)
#循环代码优化测试
import time
start = time.time()
for i in range(1000):
result = []
for m in range(10000):
result.append(i*1000+m*100)
end = time.time()
print("耗时:{0}".format((end-start)))
start2 = time.time()
for i in range(1000):
result = []
c = i*1000
for m in range(10000):
result.append(c+m*100)
end2 = time.time()
print("耗时:{0}".format((end2-start2)))
#提升30%
其他优化手段
1. 连接多个字符串,使用join()而不使用+
2. 列表进行元素插入和删除,尽量在列表尾部操作
else 语句
while 条件表达式:
循环体
else:
语句块
#如果没有被break 语句结束,则会执行else 子句
for 变量in 可迭代对象:
循环体
else:
语句块
salarySum= 0
salarys = []
for i in range(4):
s = input("请输入一共4 名员工的薪资(按Q 或q 中途结束)")
if s.upper()=='Q':
print("录入完成,退出")
break
if float(s)<0:
continue
salarys.append(float(s))
salarySum += float(s)
else:
print("您已经全部录入4 名员工的薪资")
print("录入薪资:",salarys)
print("平均薪资{0}".format(salarySum/4))
continue 语句
continue 语句用于结束本次循环,继续下一次。多个循环嵌套时,continue 也是应用于最
近的一层循环。
empNum = 0
salarySum= 0
salarys = []
while True:
s = input("请输入员工的薪资(按Q 或q 结束)")
if s.upper()=='Q':
print("录入完成,退出")
break
if float(s)<0:
continue
empNum +=1
salarys.append(float(s))
salarySum += float(s)
print("员工数{0}".format(empNum))
print("录入薪资:",salarys)
print("平均薪资{0}".format(salarySum/empNum))
执行结果:
请输入员工的薪资(按Q 或q 结束)2000
请输入员工的薪资(按Q 或q 结束)3000
请输入员工的薪资(按Q 或q 结束)4000
请输入员工的薪资(按Q 或q 结束)5000
请输入员工的薪资(按Q 或q 结束)Q
录入完成,退出
员工数4
录入薪资: [2000.0, 3000.0, 4000.0, 5000.0]
平均薪资3500.0
break 语句
break 语句可用于while 和for 循环,用来结束整个循环。当有嵌套循环时,break 语句只
能跳出最近一层的循环。
while True:
a = input("请输入一个字符(输入Q 或q 结束)")
if a.upper()=='Q':
print("循环结束,退出")
break
else:
print(a)
continue 语句
continue 语句用于结束本次循环,继续下一次。多个循环嵌套时,continue 也是应用于最
近的一层循环。
for m in range(1,10):
for n in range(1,m+1):
print("{0}*{1}={2}".format(m,n,(m*n)),end="\t")
print()
执行结果:
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
.....
r1 = dict(name="高小一",age=18,salary=30000,city="北京")
r2 = dict(name="高小二",age=19,salary=20000,city="上海")
r3 = dict(name="高小三",age=20,salary=10000,city="深圳")
tb = [r1,r2,r3]
for x in tb:
if x.get("salary")>15000:
print(x)
0 0 0 0 0
1 1 1 1 1
2 2 2 2 2
3 3 3 3 3
4 4 4 4 4
for x in range(5):
for y in range(5): #5次
print(x,end="\t")
print() #仅用于换行
for m in range(1,10):
for n in range(1,m+1):
print("{0}*{1}={2}".format(m,n,(m*n)),end="\t")
print()
执行结果:
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
......
for 循环和可迭代对象遍历
for 变量in 可迭代对象:
循环体语句
#遍历一个元组或列表
for x in (20,30,40):
print(x*3)
可迭代对象
Python 包含以下几种可迭代对象:
1. 序列。包含:字符串、列表、元组
2. 字典
3. 迭代器对象(iterator)
4. 生成器函数(generator)
5. 文件对象
我们已经在前面学习了序列、字典等知识,迭代器对象和生成器函数将在后面进行详解。接
下来,我们通过循环来遍历这几种类型的数据:
#遍历字符串中的字符
for x in "sxt001":
print(x)
#遍历字典
d = {'name':'gaoqi','age':18,'address':'西三旗001 号楼'}
for x in d: #遍历字典所有的key
print(x)
for x in d.keys():#遍历字典所有的key
print(x)
for x in d.values():#遍历字典所有的value
print(x)
for x in d.items():#遍历字典所有的"键值对"
print(x)
range 对象
range 对象是一个迭代器对象,用来产生指定范围的数字序列。
range(start, end [,step])
从start 开始到end-1 结束。默认从0
for i in range(10) ----->0 1 2 3 4 5 6 7 8 9
for i in range(3,10)------>3 4 5 6 7 8 9
for i in range(3,10,2) ----->3 5 7 9
sum_all = 0 #1-100 所有数的累加和
sum_even = 0 #1-100 偶数的累加和
sum_odd = 0 #1-100 奇数的累加和
for num in range(101): #0-100
sum_all += num
if num%2==0: sum_even += num
else: sum_odd += num
print("1-100 累加总和{0},奇数和{1},偶数和{2}".format(sum_all,sum_odd,sum_even))
while 循环
while 条件表达式:
循环体语句
num = 0
while num<=10:
print(num)
num += 1
#计算1-100 之间偶数的累加和,计算1-100 之间奇数的累加和。
num = 0
sum_all = 0 #1-100 所有数的累加和
sum_even = 0 #1-100 偶数的累加和
sum_odd = 0 #1-100 奇数的累加和
while num<=100:
sum_all += num
if num%2==0:
sum_even += num
else:
sum_odd += num
num += 1 #迭代,改变条件表达式,使循环趋于结束
print("1-100 所有数的累加和",sum_all)
print("1-100 偶数的累加和",sum_even)
print("1-100 奇数的累加和",sum_odd)
选择结构嵌套
使用时一定要注意控制好不同级别代码块的缩进量,因为缩进量决定了代码的从属关系。
if 表达式1:
语句块1
if 表达式2:
语句块2
else:
语句块3
else:
if 表达式4:
语句块4
if score>100 or score<0:
score = int(input("输入错误!请重新输入一个在0-100 之间的数字:"))
else:
if score>=90:
grade = "A"
elif score>=80:
grade = 'B'
elif score>=70:
grade = 'C'
elif score>=60:
grade = 'D'
else:
grade = 'E'
print("分{0},等{1}".format(score,grade))
score = int(input("请输入一个在0-100 之间的数字:"))
degree = "ABCDE"
num = 0
if score>100 or score<0:
score = int(input("输入错误!请重新输入一个在0-100 之间的数字:"))
else:
num = score//10
if num<6: num=5
print("{0},{1}".format(score,degree[9- num]))
多分支选择结构
if 条件表达式1 :
语句1/语句块1
elif 条件表达式2:
语句2/语句块2
.
.
elif 条件表达式n :
语句n/语句块n
[else:
语句n+1/语句块n+1
]
score = int(input("请输入分数"))
grade = ''
if(score<60):
grade = "不及格"
elif(score<80): #按逻辑写 别写反
grade = "及格"
elif(score<90):
grade = "良好"
else:
grade = "优秀"
print("分数{0},等级{1}".format(score,grade))
双分支选择结构
if 条件表达式:
语句1/语句块1
else:
语句2/语句块2
num = input("输入一个数字:")
if int(num)<10:
print(num)
else:
print("数字太大")
***三元条件运算符
用来在某些简单双分支赋值情况。
条件为真时的值 if (条件表达式) else 条件为假时的值
num = input("请输入一个数字")
print( num if int(num)<10 else "数字太大")
单分支
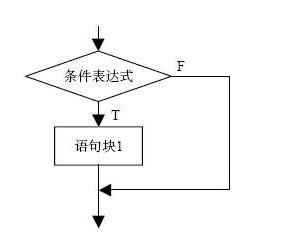
if 条件表达式:
语句/语句块
其中:
1 .条件表达式:可以是逻辑表达式、关系表达式、算术表达式等等。
2 .语句/语句块:可以是一条语句,也可以是多条语句。多条语句,缩进必须对齐一致。
num = input("输入一个数字:") #注意输入是字符串
if int(num)<10:
print(num)
在选择和循环结构中,条件表达式的值为False 的情况如下:
False、0、0.0、空值None、空序列对象(空列表、空元祖、空集合、空字典、空字
符串)、空range 对象、空迭代对象。
其他情况,均为True。Python 所有的合法表达式都可以看做条件表达式,甚至包括函数调用的表达式。
s = "False" #非空字符串,是True
if 3<c<20:
print("3<c<20")
#条件表达式中,不能有赋值操作符“=”
if 3<c and (c=20):
print("赋值符不能出现在条件表达式中")
集合
集合是无序可变,元素不能重复。实际上,集合底层是字典实现,集合的所有元素都是字典
中的“键对象”,因此是不能重复的且唯一的。
集合创建和删除
1. 使用{}创建集合对象,并使用add()方法添加元素
>>> a = {3,5,7}
>>> a
{3, 5, 7}
>>> a.add(9)
>>> a
{9, 3, 5, 7}
2. 使用set(),将列表、元组等可迭代对象转成集合。如果原来数据存在重复数据,则只保
留一个。
>>> a = ['a','b','c','b']
>>> b = set(a)
>>> b
{'b', 'a', 'c'}
3. remove()删除指定元素;clear()清空整个集合
>>> a = {10,20,30,40,50}
>>> a.remove(20)
>>> a
{10, 50, 30}
集合相关操作
像数学中概念一样,Python 对集合也提供了并集、交集、差集等运算。我们给出示例:
>>> a = {1,3,'sxt'}
>>> b = {'he','it','sxt'}
>>> a|b #并集 也就是或
{1, 3, 'sxt', 'he', 'it'}
>>> a&b #交集
{'sxt'}
>>> a-b #差集
{1, 3}
>>> a.union(b) #并集
{1, 3, 'sxt', 'he', 'it'}
>>> a.intersection(b) #交集
{'sxt'}
>>> a.difference(b) #差集
{1, 3}
根据键查找“键值对”的底层过程
当我们调用a.get(“name”),就是根据键“name”查找到“键值对”,从而找到值
对象“gaoqi”。
1.计算“name”对象的散列值:
>>> bin(hash("name"))
'-0b1010111101001110110101100100101'
2.假设数组长度为8
3.拿计算出的散列值的最右边3 位数字作为偏移量,即“101”,十进制是数字5
4.我们查看偏移量5,对应的bucket 是否为空。如果为空,则返回None。如果不为空,则将这个bucket 的键对象计算对应散列值,和我们的散列值进行比较,如果相等。则将对应“值对象”返回。如果不相等,则再依次取其他几位数字,重新计算偏移量。
5.依次取完后,仍然没有找到。则返回None。
用法总结:
1. 键必须可散列
(1) 数字、字符串、元组,都是可散列的。
(2) 自定义对象需要支持下面三点:
1 支持hash()函数
2 支持通过__eq__()方法检测相等性。
3 若a==b 为真,则hash(a)==hash(b)也为真。
2. 字典在内存中开销巨大,典型的空间换时间。
3. 键查询速度很快
4. 往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字
典的同时进行字典的修改。(建议先遍历,取出需要修改的,再修改)
字典核心底层原理(重要)
字典对象的核心是散列表。(稀疏数组(总是有空白元素的数组),数组的每个单元叫做bucket。)每个bucket 有两部分:一个是键对象的引用,一个是值对象的引用。
由于,所有bucket 结构和大小一致,我们可以通过偏移量来读取指定bucket。

将一个键值对放进字典的底层过程
假设字典a 对象创建完后,数组长度为8:

1.首先计算键”name”的散列值。Python 中可以通过hash()来计算。
>>> bin(hash("name"))
'-0b1010111101001110110101100100101'
2.数组长度为8(三位),
3.拿散列值的最右边3 位数字作为偏移量,即
“101”,十进制是数字5。
4.我们查看偏移量5,对应的bucket 是否为空。如果为空,则将键值对放进去。如果不为空,则依次取右边3 位作为偏移量,即“100”直到找到为空的bucket 将键值对放进去。
5.数组放满不够就扩容