切片slice操作
[起始偏移量 start:终止偏移量 end[:步长 step]]
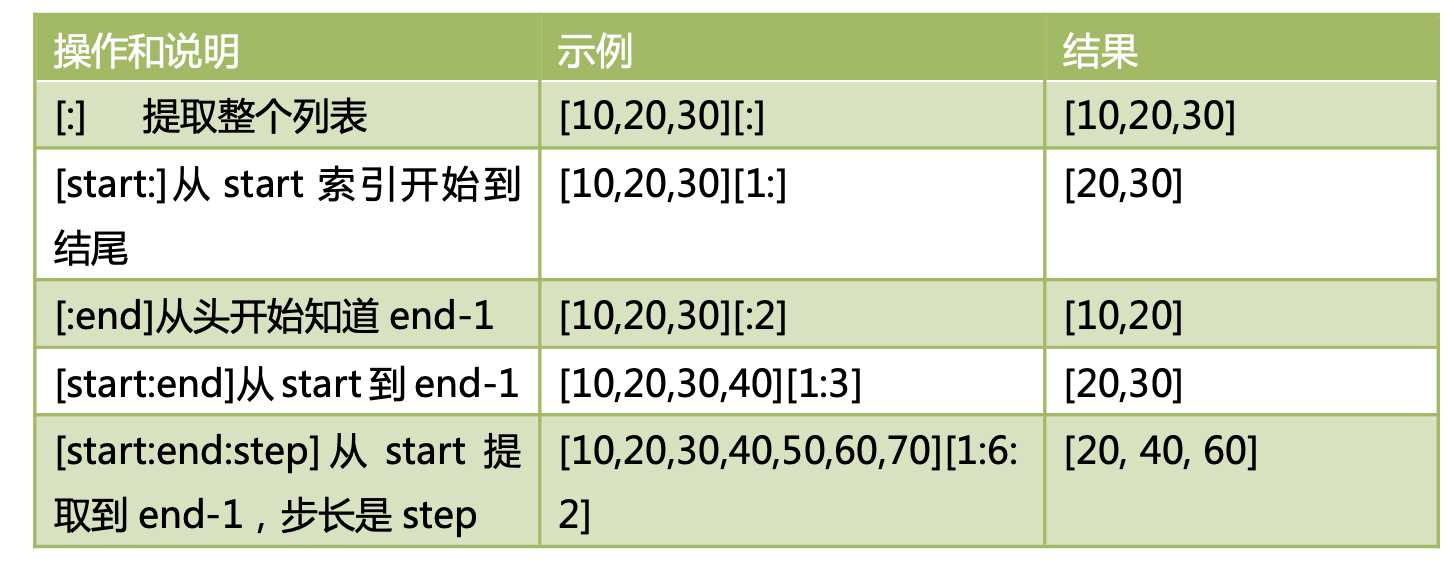
⚠️ end-1(索引)
⚠️如果只有如:[1:3]、[-5:-3],则包头不包尾
⚠️使用负数,反着数
列表的遍历
for obj in listObj:
print(obj)


切片slice操作
[起始偏移量 start:终止偏移量 end[:步长 step]]
⚠️ end-1(索引)
⚠️如果只有如:[1:3]、[-5:-3],则包头不包尾
⚠️使用负数,反着数
列表的遍历
for obj in listObj:
print(obj)
列表元素访问和计数
1、索引访问
索引区间[0,列表长度-1],超范围会报异常
2、index() 元素在列表中(首次)出现的索引
index(value,[start,[end]])
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.index(20)
1
>>> a.index(20,3) #从索引位置 3 开始往后搜索的第一个 20
5
>>> a.index(30,5,7)
6
3、count() 计数
4、len() 长度=元素个数
5、成员资格判断
in
count() 返回0就不在
列表元素的删除
1、del() 本质是数组拷贝
被删元素后面的依次向前拷贝

2、pop() 方法
删除并返回指定位置元素
3、remove() 方法
删除首次出现的指定元素,若不存在报异常
列表的增加与删除
1、append() 尾部加,推荐
2、+运算,拼接,会产生新列表对象,id变
3、extend() 原地扩展,id不变
4、insert() 插入元素之一,涉及数组移动
5、乘法扩展
列表的创建
可存储任何数据,索引下表获取值
range()创建整数列表
range([start,] end [,step])
start参数:可选,起始
end参数:必选,结尾
step参数:可选,步长
循环创建多个元素
a = [ x*2 for x in range(5)]
>>>a
[0,2,4,6,8]
if过滤元素
a = [ x*2 for x in range(100) if x%9==0]
>>>a
[0,18,36,54,72,.......,198]
python的序列
数据存储方法:字符串、列表、元组、字典、集合
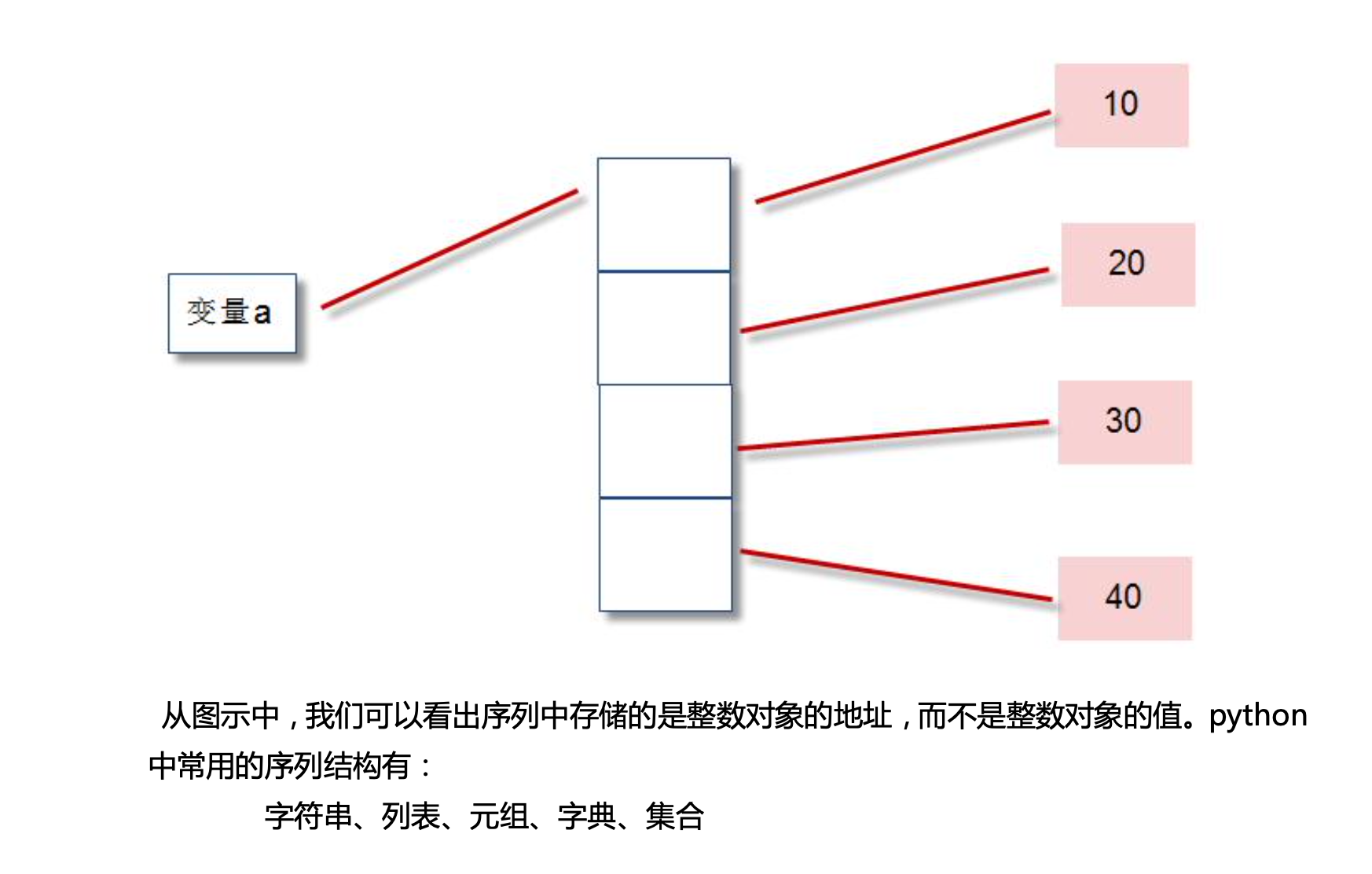
存地址、轻量级
列表大小可变
Python基础课
一、可变字符串
字符串定义以后是不可变的,不能原地修改吗,
连续[2:5,1:4]跳跃[[2,1],[3,5]]
分解问题
确认坐标系0点
按照思路敲代码
"报错的文字里总有认识的单词”
搜索“CMD"
输入“python”

SST (总方差)= SSE() + SSR (残差平方和)
只有无偏估计下成立,否则 SST≥SSE+ SSR
局部加权
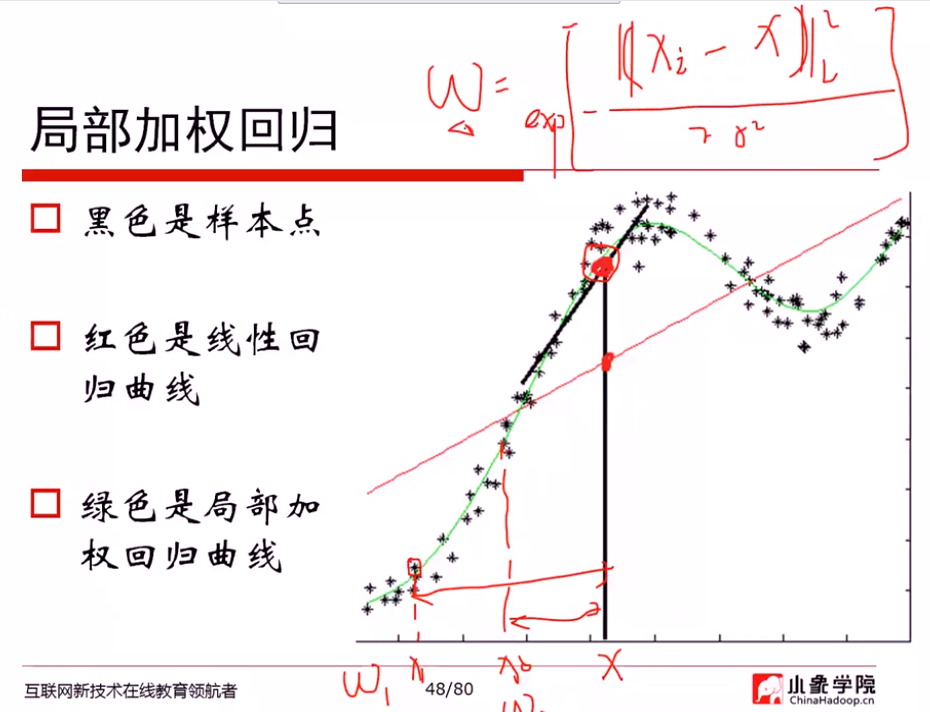

最重要的问题: 如何度量权重
Logistic回归

p(y|x:θ) y=0, y=1时,写成上述密度函数形式
解法1: 从mle求解

极大似然估计的梯度上升算法,本质与梯度下降无区别,梯度上升取正梯度方向,同样设置步长a;梯度下降选取负梯度方向,

线性回归: 假定服从高斯分布,通过MLE进行估计
logistics回归: 假定服从二项分布,通过MLE进行估计
如果都进行梯度下降法估计,会发现求解的方式都是一样的
广义线性模型的定义: 因变量不服从正态分布,且因变量与自变量不存在线性关系;广义就是要找一个非线性的关系f,使得转换后更接近因变量的分布
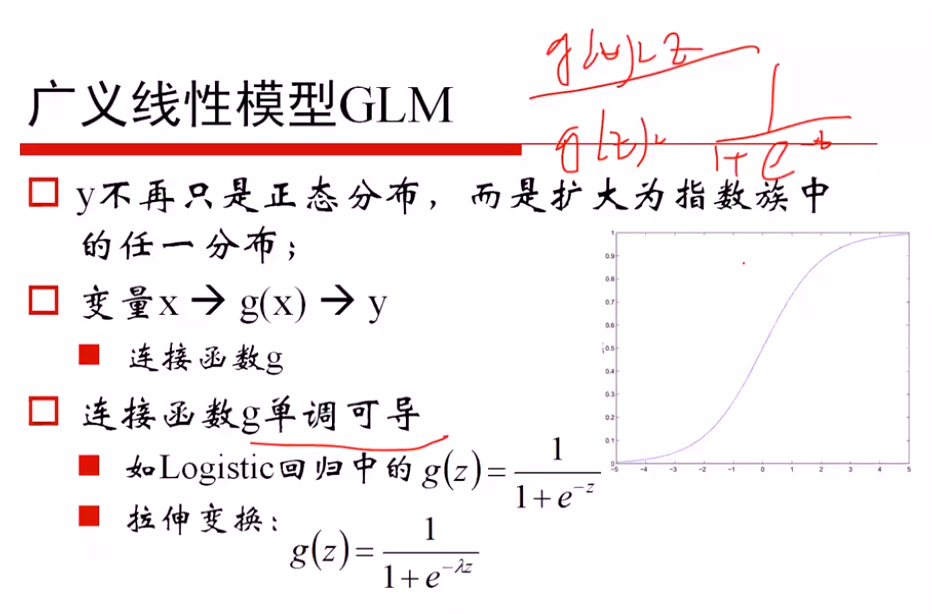
证明是一个广义的线性模型:
对数线性模型:

从对数模型理解 logistics函数
一方面: 从 ln(p/(1-p)) = θx 推导出 p = logistics函数,说明希望对数模型是线性的,从而推导出概率可以用logistics函数表示
另一方面: 从 p=logistics函数 + ln(p/(1-p))对数模型,推导出对数模型是线性的θTx
广义线性模型 → 相似的梯度下降方法
解法2: 从损失函数进行求解

(1)对 -1, 1转换为0, 1 进行(yi+1)/2...
softmax回归

鸢尾花数据
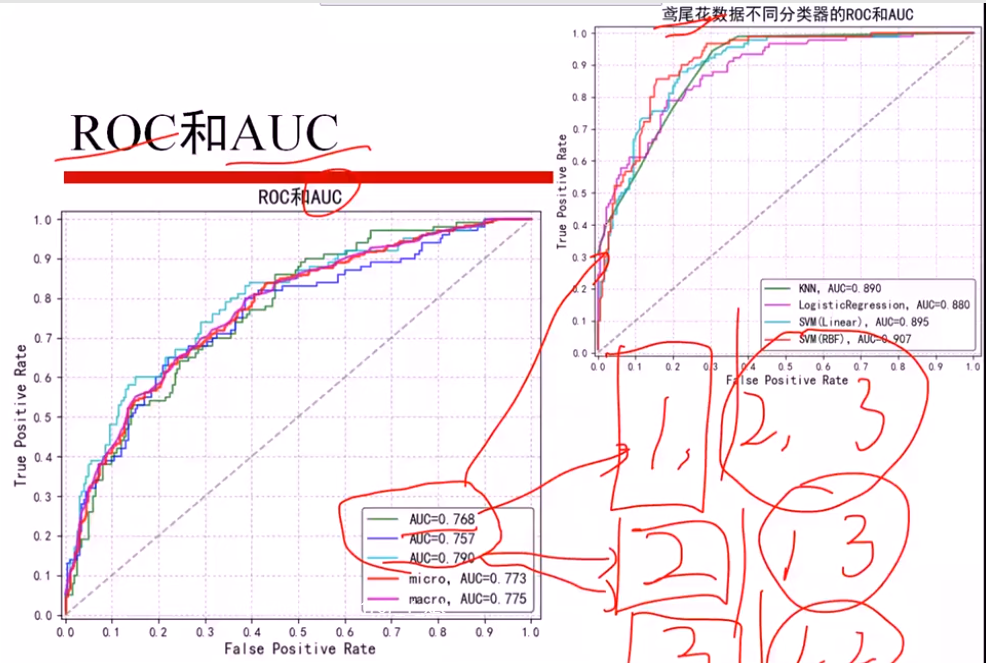
分为三个 二分类问题,算出三个AUCi值
micro: 直接算三个平均AUCi,得出AUC
macro: 总体加和,当作一个AUC计算
假设: 误差ξ服从高斯分布(0, δ)

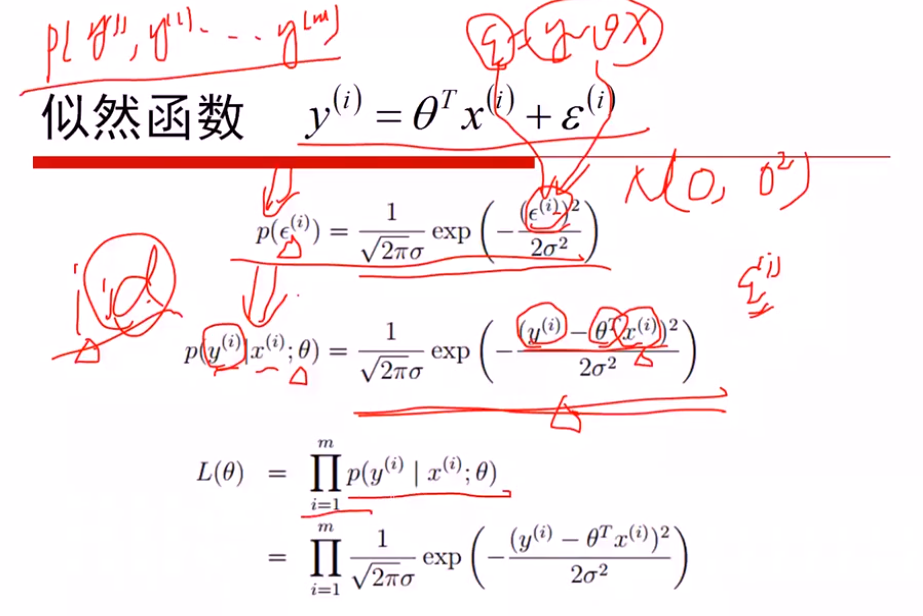

①最大化似然函数,对l(θ)进行简化
max l(θ) 等价于 min(J(θ))

注意:
(1)是关于θ的函数,最大化θ参数
(2)J(θ)是一个xTx的凸函数,因为xTx是半正定的,开口向上,xTxθTθ就是关于θ的开口向上的二次函数

(1)L2正则,进行对θ惩罚 -- Ridge回归
L1正则, -- Lasso回归
1 拉格朗日角度进行解释
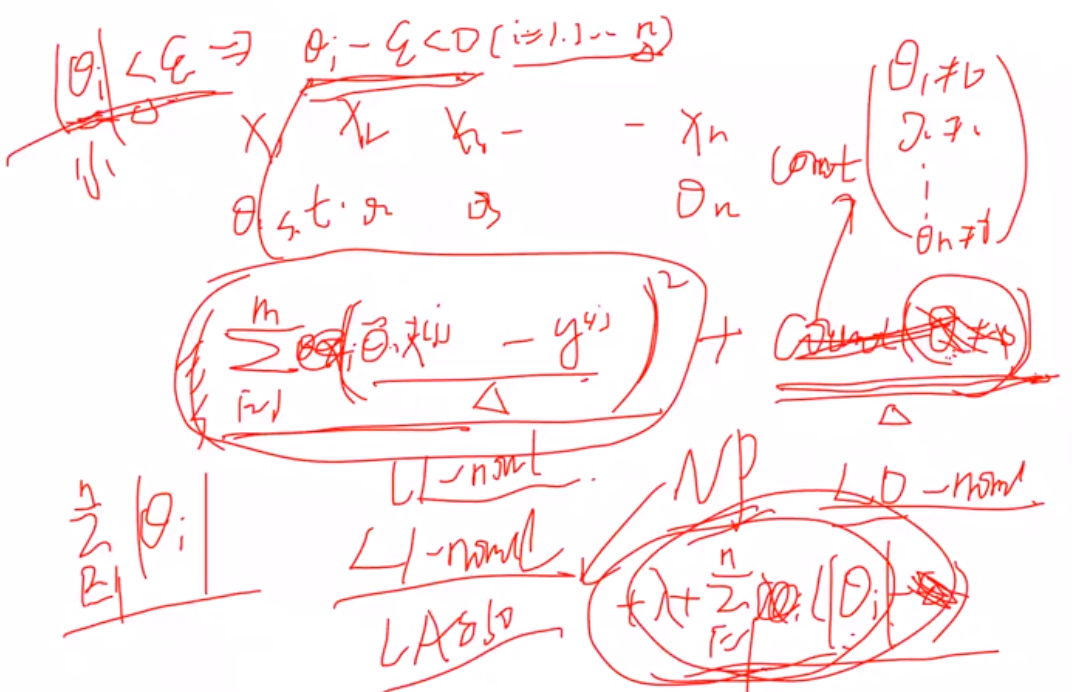
(1) 原本的目标: 希望θ=0就计0,不等于0就计为1,惩罚θ>0时候的数目,但是由于是无解的,因此用L1范数进行近似
推导看手稿:
2 几何解释:

L1约束使得某一个wi是0,稀疏约束
L2使得两个wi都比较小,约束
(1)坐标轴下降法
(2)近端梯度近似法... 其余还有很多


(1)当x可逆, θx =y可以直接进行求解,不用进行目标函数最小化求解,因此可以利用SVD进行奇异值分解,求出伪逆矩阵后进行求解
假设1:p(Ai) 概率相似
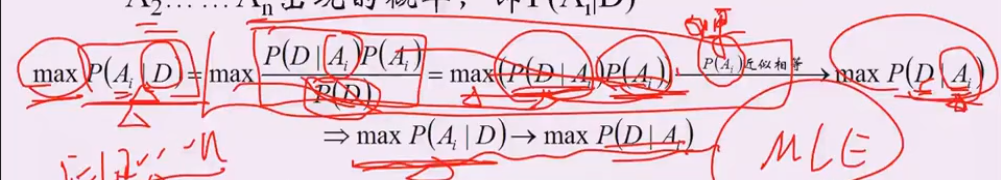
P(D|Ai): 给定结论Ai下, 这个数据以多大的概率产生。 可以理解为x1..xn是未知的数据参数,θi是已知的参数,能够使 p(x1..xn|θi)最大的参数θi,就是我们想要估计的参数, 这里xi对应D,Ai对应参数θ
公平赔率; y = 1/p y是赔率,p是赢的概率
赔率公式 y =a/p
计算庄家盈亏:

10.5% = 0.21 a / 2a
2 PCA
2.1 原理
①求协方差矩阵
② 特征值排序
③ 方差最大的就认为是主要的方向,其中特征向量相互垂直,每一个特征向量就是一个方向,Aμi的方差最大,就认为是最主要的投影方向


①假定样本已经作了中心化,所以忽略均值E
Q 为什么特征值最大 等价于 求方差最大?
PCA中希望投影的方差最大,认为得到的信息最多。
目标函数: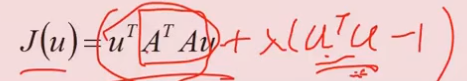
加上等式约束 μTμ=1, 根据拉格朗日求解,
aJ/aμ = 2ATAμ +2λμ = 0 ,求得λ就是 ATA的特征值。
因此,方差最大 等价于 最大特征值
2.2 过拟合问题
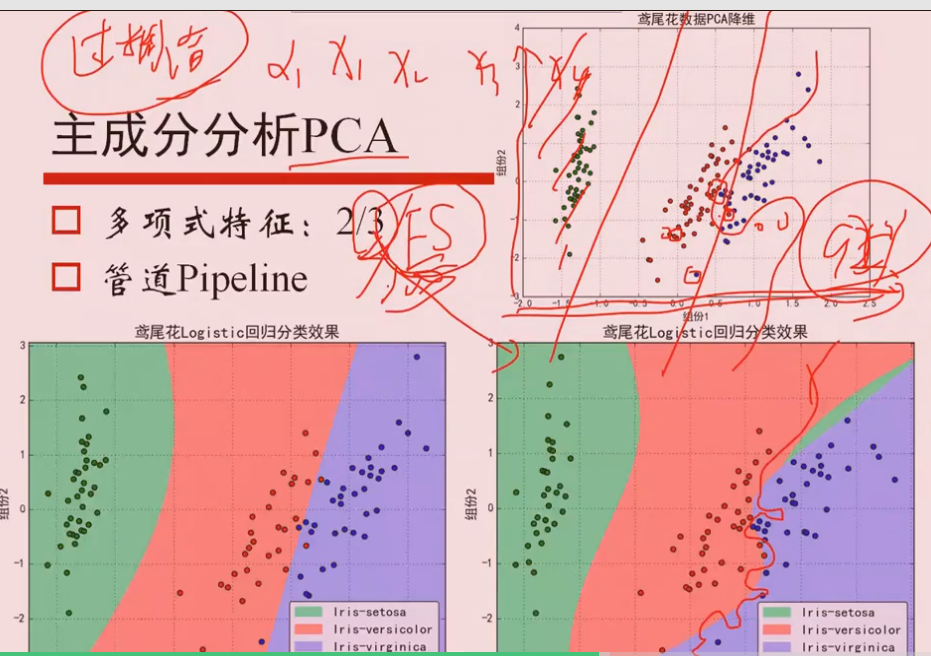
使用高阶的特征x1^2, x2^2...,特征过多,虽然会得到弯曲的曲线进行分离,但是很有可能产生过拟合问题
决策树不需要做one-hot编码
6.1 Prime
计算素数:
fliter(函数, x): 把数字放入x中,结果输出
类方法,实例方法
类属性,实例属性
类方式和静态方法中不能调用实例变量,实例方法
实例防范从属于实例对象
类在进行实例话时,先调用new()函数创建对象,然后再把地址引用给变量
is适用于比较地址,即判断是否为同一个对象,==是判断值的大小是否相同
类产生对象
浅拷贝与深拷贝
栈帧