split()分割和join()合并
split()可以基于指定分隔符将字符串分隔为多个子字符串,如果不指定分隔符,则默认使用空白字符。
join()用于将一系列子字符串拼接


split()分割和join()合并
split()可以基于指定分隔符将字符串分隔为多个子字符串,如果不指定分隔符,则默认使用空白字符。
join()用于将一系列子字符串拼接
回归树:参数、属性和接口
criterion
回归树衡量分枝质量的指标,支持的标准有三种: 1)输入"mse"使用均方误差mean squared error(MSE),父节点和叶子节点之间的均方误差的差额将被用来作为 特征选择的标准,这种方法通过使用叶子节点的均值来最小化L2损失
2)输入“friedman_mse”使用费尔德曼均方误差,这种指标使用弗里德曼针对潜在分枝中的问题改进后的均方误差
3)输入"mae"使用绝对平均误差MAE(mean absolute error),这种指标使用叶节点的中值来最小化L1损失 属性中最重要的依然是feature_importances_,接口依然是apply, fit, predict, score最核心。
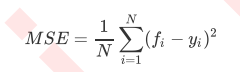
在回归树中,MSE不只是我们的分枝质量衡量指标,也是我们最常用的衡 量回归树回归质量的指标,当我们在使用交叉验证,或者其他方式获取回归树的结果时,我们往往选择均方误差作 为我们的评估(在分类树中这个指标是score代表的预测准确率)。在回归中,我们追求的是,MSE越小越好。然而,回归树的接口score返回的是R平方,并不是MSE。
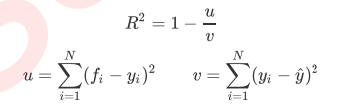
y尖儿是标签的平均值。虽然均方误差永远为正,但是sklearn当中使用均方误差作为评判标准时,却是计算”负均方误 差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均 方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss),因此在sklearn当中,都以负数表示。真正的 均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
(1)字符串切片slice操作:截取字符串
标准格式为:[起始偏移量:终止偏移量:步长]包头不包尾
[:]提取整个字符串
目标权重参数
class_weight & min_weight_fraction_leaf
在银行要 判断“一个办了信用卡的人是否会违约”,就是是vs否(1%:99%)的比例。这种分类状况下,即便模型什么也不 做,全把结果预测成“否”,正确率也能有99%。因此我们要使用class_weight参数对样本标签进行一定的均衡,给 少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。
有了权重之后,样本量就不再是单纯地记录数目,而是受输入的权重影响了,因此这时候剪枝,就需要搭配min_ weight_fraction_leaf这个基于权重的剪枝参数来使用。另请注意,基于权重的剪枝参数(例如min_weight_ fraction_leaf)将比不知道样本权重的标准(比如min_samples_leaf)更少偏向主导类。如果样本是加权的,则使 用基于权重的预修剪标准来更容易优化树结构,这确保叶节点至少包含样本权重的总和的一小部分。
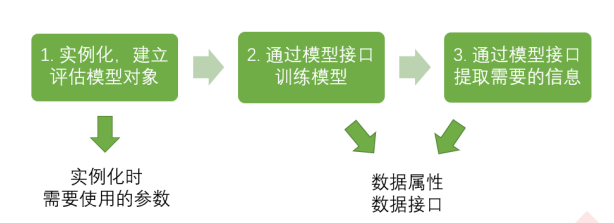
重要的属性和接口
sklearn中许多算法的接口都是相似的,比如说我们之前已经用到的fit和score,几乎对每个算法都可以使用。除了 这两个接口之外,决策树最常用的接口还有apply和predict。

如果你的数据的确只有一个特征,那必须用reshape(-1,1)来给 矩阵增维;如果你的数据只有一个特征和一个样本,使用reshape(1,-1)来给你的数据增维。
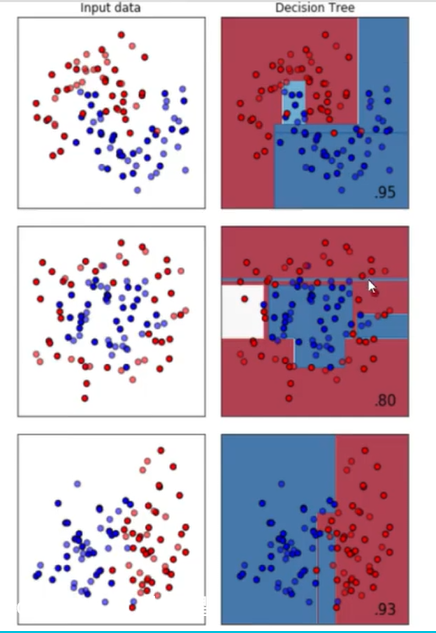
决策树模型天生对环形数据没有良好的训练效果。
第一个是月亮型数据集、第二个是环形数据集、第三个是对半分数据集。分类树天生不擅长环形数据。每个模型都有自己的决策上限,所以一个怎样调整都无法提升 表现的可能性也是有的。当一个模型怎么调整都不行的时候,我们可以选择换其他的模型使用,不要在一棵树上吊 死。顺便一说,最擅长月亮型数据的是最近邻算法,RBF支持向量机和高斯过程;最擅长环形数据的是最近邻算法和高斯过程;最擅长对半分的数据的是朴素贝叶斯,神经网络和随机森林。
max_features & min_impurity_decrease
一般max_depth使用,用作树的”精修“
·max_features
限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工,max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量 而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型 学习不足。如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
·min_impurity_decrease限制信息增益的大小,(信息增益是用父节点的信息熵-子节点的信息熵)信息增益小于设定数值的分枝不会发生。这是在0.19版本中更新的功能,在0.19版本之前时使用min_impurity_split。
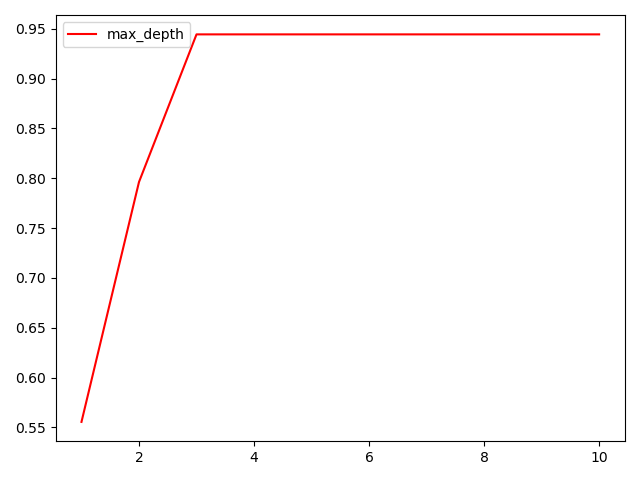
剪枝参数可以通过学习曲线来找到最优参数
无论如何,剪枝参数的默认值会让树无尽地生长,这些树在某些数据集上可能非常巨大,对内存的消耗也非常巨 大。所以如果你手中的数据集非常巨大,你已经预测到无论如何你都是要剪枝的,那提前设定这些参数来控制树的 复杂性和大小会比较好。
剪枝参数
在不加限制的情况下,一棵决策树会生长到衡量不纯度的指标最优,或者没有更多的特征可用为止。这样的决策树 往往会过拟合,这就是说,它会在训练集上表现很好,在测试集上却表现糟糕。
为了让决策树有更好的泛化性,我们要对决策树进行剪枝。剪枝策略对决策树的影响巨大,正确的剪枝策略是优化 决策树算法的核心。
·max_depth
限制树的最大深度,超过设定深度的树枝全部剪掉 这是用得最广泛的剪枝参数,在高维度低样本量时非常有效。决策树多生长一层,对样本量的需求会增加一倍,所 以限制树深度能够有效地限制过拟合。实际使用时,建议从=3开始尝试,看看拟合的效 果再决定是否增加设定深度。
·min_samples_leaf & min_samples_split min_samples_leaf
限定,一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分 枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。
一般搭配max_depth使用,在回归树中有神奇的效果,可以让模型变得更加平滑。这个参数的数量设置得太小会引 起过拟合,设置得太大就会阻止模型学习数据。一般来说,建议从=5开始使用。
min_samples_split限定,一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则 分枝就不会发生。
建一棵树
train_test_split
训练集和测试集划分每次都是随机的喔,所以实验结果每次都不同
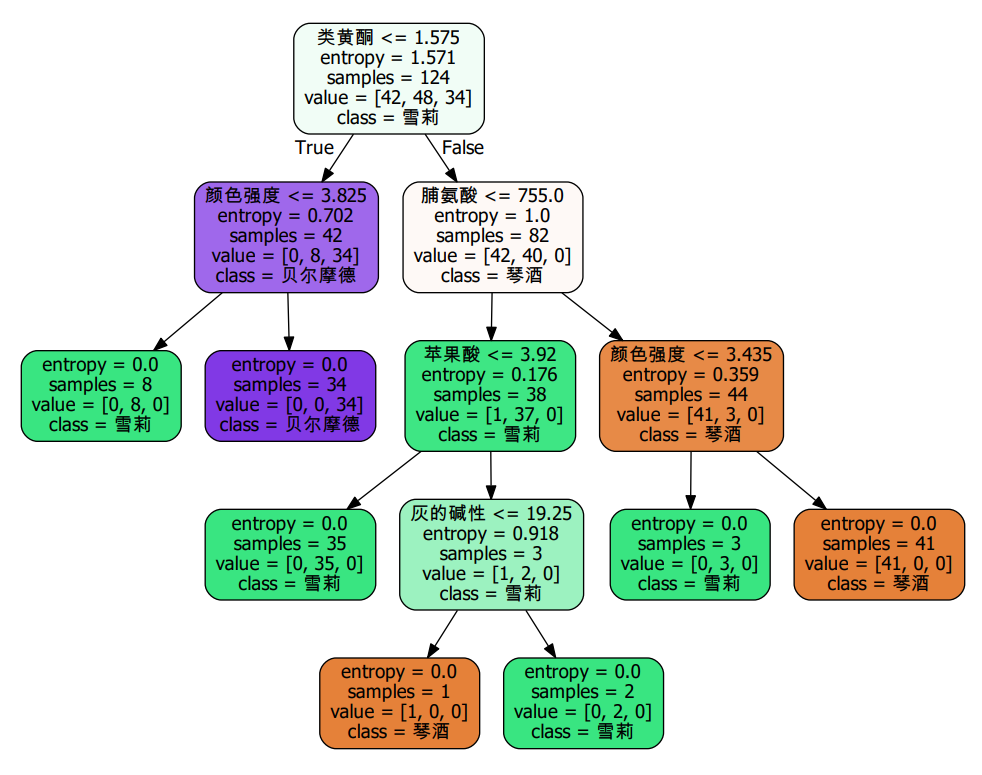
决策树在形成时,分支的时候是通过计算每个节点的不纯度来选取节点,是通过优化每个节点来形成的,但是最优的节点不一定能形成最优的树。
每次建树的时候都是通过选取不同的特征值来形成不同的树。但是每次返回的最优的树都不同。
所以可以通过固定一个种子数来固定最优树模型。
random_state用来设置分枝中的随机模式的参数,默认None,在高维度时随机性会表现更明显,低维度的数据 (比如鸢尾花数据集),随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项的,有两种输入值,输入”best",决策树在分枝时虽然随机,但是还是会 优先选择更重要的特征进行分枝(重要性可以通过属性feature_importances_查看),输入“random",决策树在 分枝时会更加随机,树会因为含有更多的不必要信息而更深更大,并因这些不必要信息而降低对训练集的拟合。
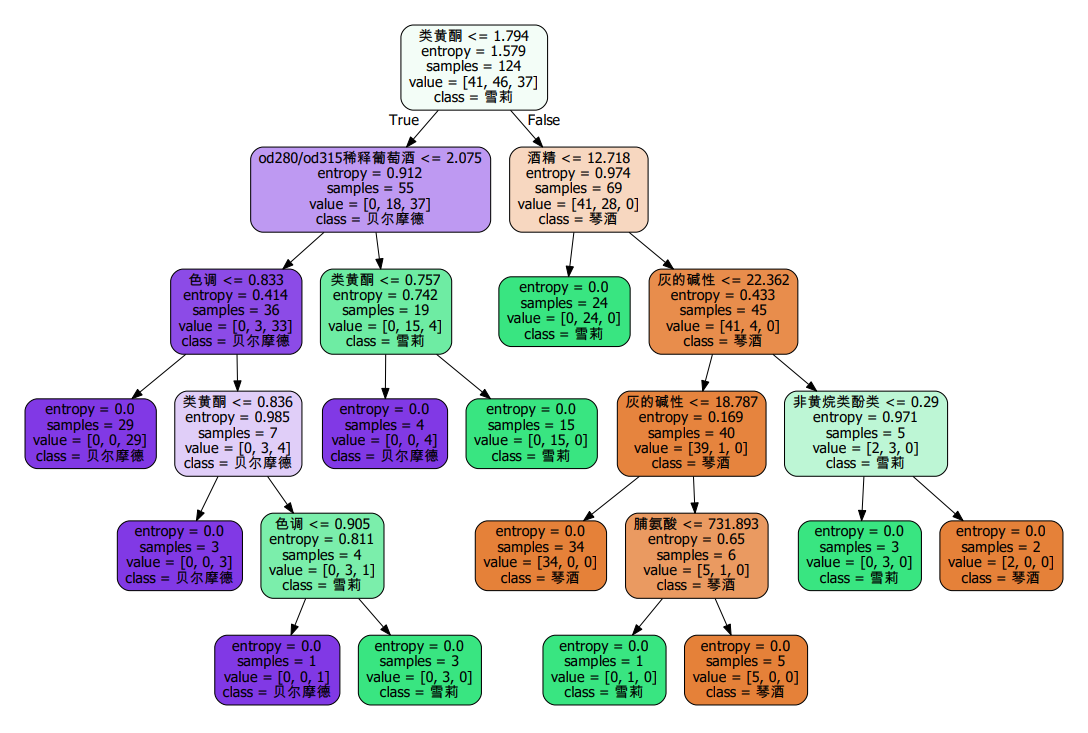
加入splitter=‘random’以后会发现树变得更大更宽了,因为特征值选取更加随机了
默认是best
重要参数
criterion
为了要将表格转化为一棵树,决策树需要找出最佳节点和最佳的分枝方法,对分类树来说,衡量这个“最佳”的指标 叫做“不纯度”。通常来说,不纯度越低,决策树对训练集的拟合越好。
不纯度基于节点来计算,树中的每个节点都会有一个不纯度,并且子节点的不纯度一定是低于父节点的,也就是 说,在同一棵决策树上,叶子节点的不纯度一定是最低的。
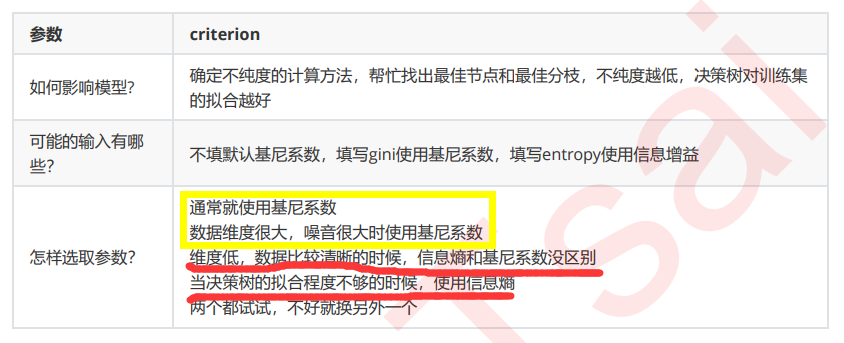
Criterion这个参数正是用来决定不纯度的计算方法的。sklearn提供了两种选择:
1)输入”entropy“,使用信息熵(Entropy) 2)输入”gini“,使用基尼系数(Gini Impurity)
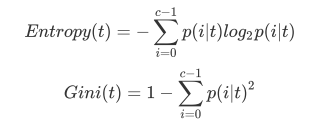

当使用信息熵 时,sklearn实际计算的是基于信息熵的信息增益(Information Gain),即父节点的信息熵和子节点的信息熵之差。
比起基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。但是在实际使用中,信息熵和基尼系数的效果基 本相同。信息熵的计算比基尼系数缓慢一些,因为基尼系数的计算不涉及对数。另外,因为信息熵对不纯度更加敏 感,所以信息熵作为指标时,决策树的生长会更加“精细”,因此对于高维数据或者噪音很多的数据,信息熵很容易 过拟合,基尼系数在这种情况下效果往往比较好。当模型拟合程度不足的时候,即当模型在训练集和测试集上都表 现不太好的时候,使用信息熵。当然,这些不是绝对的
决策树
1、概述
决策树是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,以解决分类和回归问题。
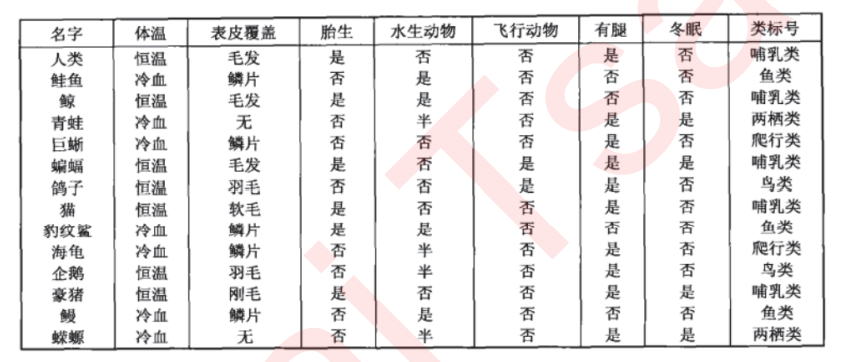
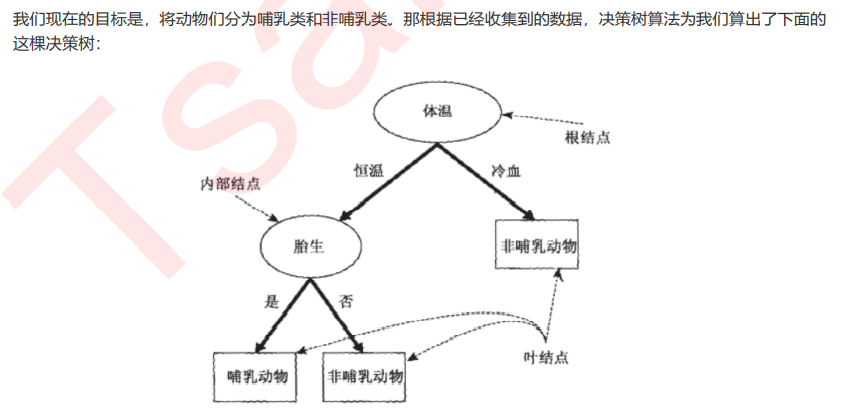
2、关键概念:节点
根节点:没有进边,有出边。包含最初的,针对特征的提问。
中间节点:既有进边也有出边,进边只有一条,出边可以有很多条。都是针对特征的提问。
叶子节点:有进边,没有出边,每个叶子节点都是一个类别标签。
子节点和父节点:在两个相连的节点中,更接近根节点的是父节点,另一个是子节点。/3、
3、决策树算法的核心是要解决两个问题:
1)如何从数据表中找出最佳节点和最佳分枝? 2)如何让决策树停止生长,防止过拟合?
4、模块sklearn.tree的使用


1.str()实现数字转型字符串
print(str(1)) #1 print(str(34.5)) #34.5
2.使用[]提取字符
字符串的本质就是字符序列,可以通过在字符串后面添加[]里面指定偏移量,可以提取该位置的单个字符。
正顺序从0,1顺序标号,负顺序从-1,-2倒数标号。
a="abcdefdhigklmnopqrstuvwxyz" print(a[1]) #b print(a[-1]) #z
3.replace()实现字符串“改变”
字符串不可改变,调用replace()生成新字符串,原字符串并没有变化。
a="abcdefdhigklmnopqrstuvwxyz"
print(a.replace('c','付')) #ab付defdhigklmnopqrstuvwxyz
print(a) #abcdefdhigklmnopqrstuvwxyz 原字符串的值不更改
a=a.replace('c','付') #a指向新的字符串
print(a) #ab付defdhigklmnopqrstuvwxyz a的值被更改
什么是sklearn?
sklearn是一个开源的基于python语言的机器学习工具包,它通过numpy、scipy和matplotlib等python数值计算的库实现高效的算法应用,涵盖了几乎所有主流机器学习算法。
转义字符:使用"\+特殊字符",实现某些难以用字符表示的效果。如换行等。
续行符:\
a='aaa\ bbb' print(a) #aaabbb
字符串拼接
+两边都是字符串 或者直接放到一起实现拼接
a='aaa'+'bbb' print(a) #aaabbb b='aaa''bbb''ccc' print(b) #aaabbbccc
字符串复制
a='aaa'*3 print(a) #aaaaaaaaa
不换行打印
print("aaa")
print("bbb")
print("ccc")
'''
aaa
bbb
ccc
'''
print("aaa",end="*") #以星号结尾并且不换行
print("bbb",end="\t")
print("ccc") #aaa*bbb cccc
从控制台读取字符串:使用input()从控制台读取键盘输入的内容。
myname=input("请输入名字:")
同一运算符:用于比较两个对象的储存单元,实际比较的是对象的地址。
is:判断两个变量引用对象是否为同一个,即比较对象的地址。
==:用于判断引用变量引用对象的值是否相等。
布尔值:True(1),False(0)
比较运算符:
==等于
!=不等于
逻辑运算符:
or(或)、and(与)、not
import time
a=int(time.time())
print(a)
totleminite=a//60
print(totleminite)
totlehour=tl=totleminite//60
print(totlehour)
totleday=totlehour//24
print(totleday)
totleyear=totleday//365
print(totleyear) #51
时间的表示
浮点数:小数float
类型转换和四舍五入:float()
round(value)可以返回四舍五入的值:不会改变原有的值,但是会产生新的值。
增强型赋值运算符:
+=:a+=2等价于a=a+2
类似的有:-=、*=、/=
整数:0b二进制,0o八进制,0x十六进制
用int()实现类型转换:
print(int(3.99)) #3 print(int(True)) #1 print(int(False)) #0
自动转型:
a=3+3.5 print(a) #6.5
最基本内置数据类型介绍
(1)整型
(2)浮点型:小数
(3)布尔型:True、False
(4)字符串型:"abc"、"sxt"
(5)特殊一点的运算符:
/:浮点数除法
//:整数除法
%:取余
**:幂
使用divmod()函数同时得到商和余数
变量的声明和赋值
1.变量在使用前必须被初始化。
2.变量使用后可以被删除。
标识符:用于变量、函数、类、模块等的名称。
规则:
1.区分大小写。
2.必须以字母、下划线作为开头。其后的只能用字母、数字、下划线
3.不能使用关键字
4.不要以双下划线开头或者结尾
模块和包名:全小写,尽量简单,多个单词之间用下划线。
函数名:全小写,多个单词之间用下划线。
类名:首字母大写,采用驼峰原则。
常量名:全大写,多个单词之间使用下划线隔开。