类对象


3454-孙同学-人工智能学科-计算机视觉方向
3454-孙同学-人工智能学科-计算机视觉方向
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
实例方法(从属于实例对象)
def 方法名(self,[形参列表]):
函数体
实例属性:从属于实例对象,也成为实例变量。
(1)实例属性一般在__init__()方法中通过如下代码定义:
self.实例属性名=初始值
(2)在本类的其他实例方法中,也是通过self进行访问:
self.实例属性名
(3)创建实例对象后,通过实例对象进行访问:
obj01=类名() #创建对象,调用__init__()初始化属性
obj01.实例属性名=值 #可以给已有属性赋值,也可以新加属性
构造函数__init__():初始化实例对象的实例属性。
Python对象包含三个部分=id、type、value
只要是类中的方法参数第一个都是self,通过类名()来调用构造函数
对象的进化
面向对象
Python支持面向过程、面向对象、函数式编程等多种编程范式。
LEGB规则
Local:函数或者类的方法内部
nonlocal关键字
nonlocal 用来声明外部的局部变量
global 用来声明全局变量
嵌套函数:在函数内部定义的函数
递归函数:在函数体内直接或者间接的自己调用自己。
(1)终止条件:表示递归什么时候结束,一般用于返回值,不再调用自己。
(2)递归步骤:把第n步的值和第n-1步相关联。
eval()函数
lambda表达式和匿名函数
基本语法:
lambda arg1,arg2,arg3...:<表达式>
可变参数(一个*为元组,**为字典)
强制命名参数(当带星号的“可变参数”后面增加新的参数,必须是强制命名参数)
参数的几种类型
位置参数
默认值参数
命名参数
传递不可变对象:浅拷贝
浅拷贝和深拷贝
浅拷贝:不拷贝子对象的内容,只拷贝子对象的引用。
深拷贝:会连子对象的内存全部拷贝一份,对子对象的修改不会影响源对象。
高效嵌入法embedded
业务选择
说到降维和特征选择,首先要想到的是利用自己的业务能力进行选择,肉眼可见明显和标签有关的特征就是需要留 下的。当然,如果我们并不了解业务,或者有成千上万的特征,那我们也可以使用算法来帮助我们。或者,可以让 算法先帮助我们筛选过一遍特征,然后在少量的特征中,我们再根据业务常识来选择更少量的特征。
PCA和SVD一般不用
逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征X与标签y之间的 关系,而逻辑回归也传承了这个性质,我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关, 因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标 签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
统计方法可以使用,但不是非常必要
逻辑回归对数据的要求低于线性回归,由于我们不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我 们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。
重要参数penatly&C
1、正则化

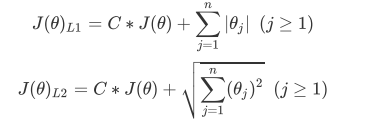

L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小), 参数的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型 有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。L1正 则化越强,参数向量中就越多的参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大 的特征的参数会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但 是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。