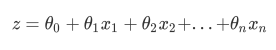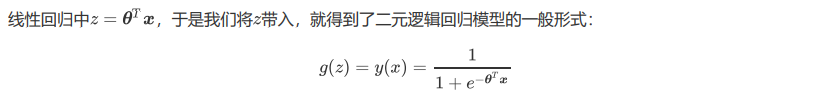为什么需要逻辑回归
1. 逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的 信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提 升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的 统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知 道数据之间的联系是非线性的,千万不要迷信逻辑回归);
2. 逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表示在大型数据上尤其能够看得出区别;
3. 逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字:我们因此可以把逻辑回归返 回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确 定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类 器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口 predict_proba调用就好,但一般来说,正常的决策树没有这个功能)。
另外,逻辑回归还有抗噪能力强的优点。福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,最佳模型 的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的 数据集上,树模型有着更好的表现。
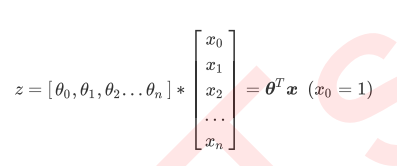
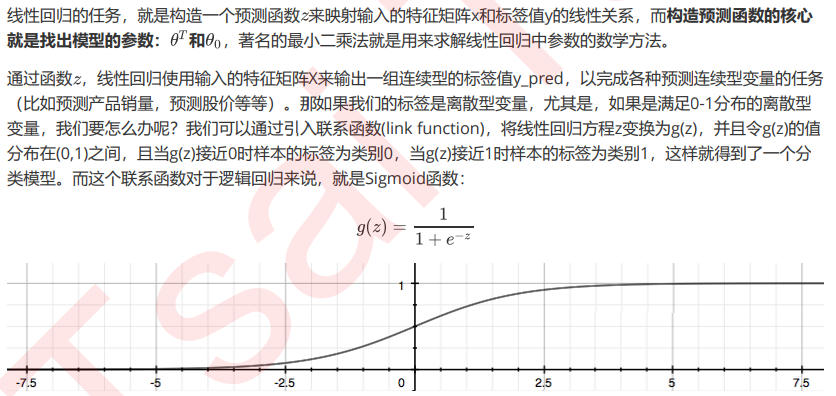
由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应 用在金融领域。其数学目的是求解能够让模型对数据拟合程度最高的参数 的值,以此构建预测函数 ,然后将 特征矩阵输入预测函数来计算出逻辑回归的结果y。注意,虽然我们熟悉的逻辑回归通常被用于处理二分类问题, 但逻辑回归也可以做多分类。