n_estimators基评估器数量,该值越大,越好。
到达一定程度后,精确性会开始波动。


n_estimators基评估器数量,该值越大,越好。
到达一定程度后,精确性会开始波动。
集成算法:在数据上构建多个模型,集成所有模型的建模结果。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果。
集成评估器:基评估器,装袋法,提升法,stacking
sklearn中的ensemble,集成算法有一半以上都是树的模型。决策树用于分类和回归问题。通过有特征和标签的表格中,通过对特定特征进行提问,总结出决策规则。
如何找到正确的特征去提问,定义衡量分支质量的指标不纯度。
列表对象的创建
可变字符串
字符串格式化
format
填充与 对齐
字符串的驻留机制
字符串切割 split()
作用:基于指定字符串将字符串分隔成多个子字符串
a.spilt()
字符串拼接
字符串切片 slice
作用::截取子字符串。包头不包尾

字符串
str()函数
定义:将其他类型转为字符串
[]提取字符
replace
创建一个的字符串,
a.relace('c','高')
字母、数字、下划线组成,必须以字母或下划线开头
a = 3
将3的存储地址赋值给变量a。引用a
切片操作包头不包尾
变量的删除操作:
a=3
del a
此时a就被删除了。
一· 认识python
1.特点:
可读性强
简洁
面向对象
免费和开源
可移植和跨平台
2.
.开头是隐藏文件l
排序算法的稳定性:将原有相等键值的记录维持相对次序。
二维列表
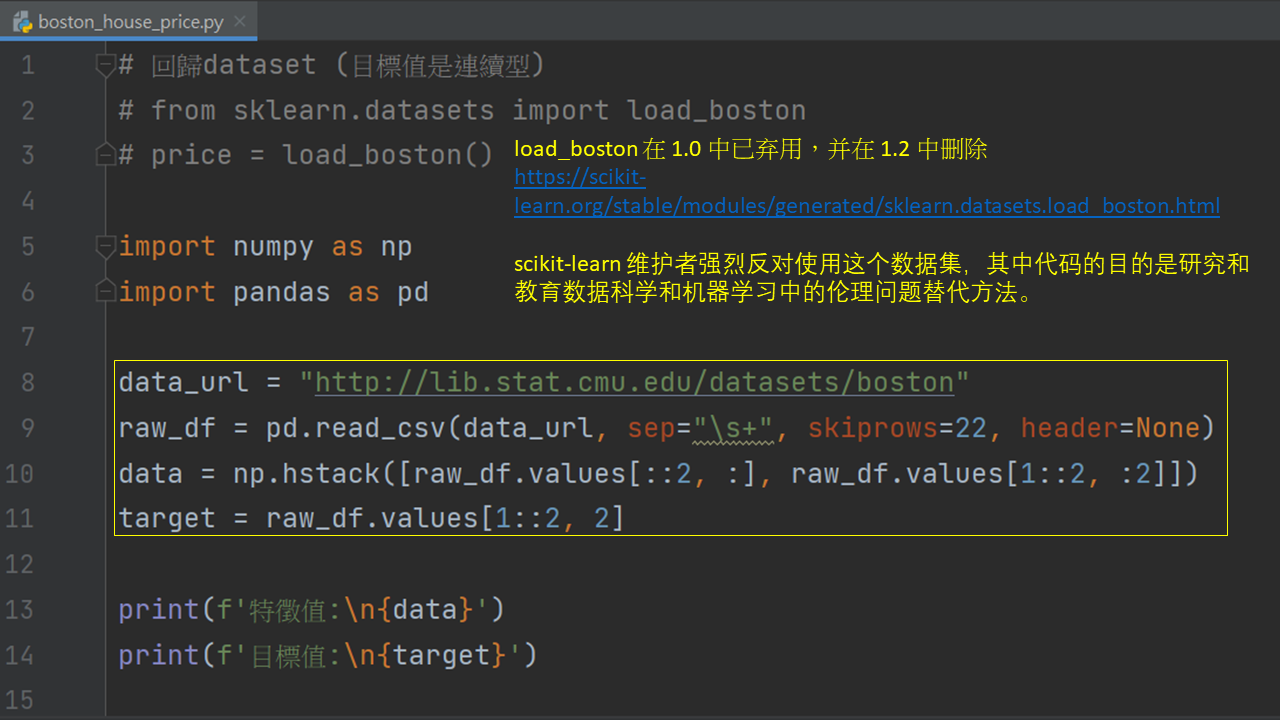
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)