列表元素的增加和删除
append()方法
+运算符操作
extend()方法
insert()插入元素
乘法扩展


列表元素的增加和删除
append()方法
+运算符操作
extend()方法
insert()插入元素
乘法扩展
序列
是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个值的连续的内存空间。
基本运算符


运算符的优先级
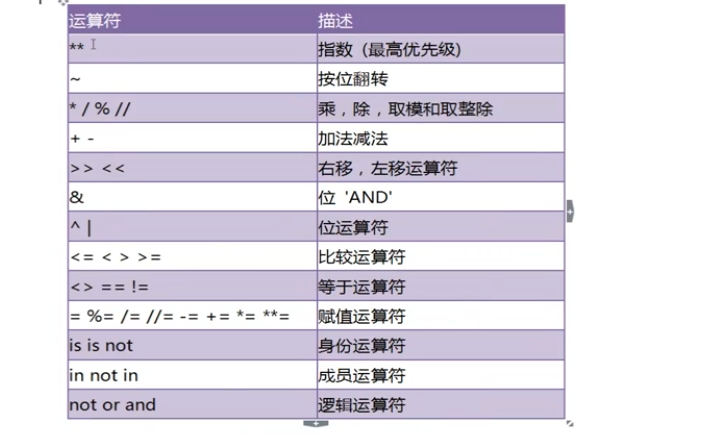
实际使用中,记住如下简单的规则即可,复杂的表达式一定要使用小括号组织。
1.乘除优先加减
2.位运算和算术运算>比较运算符>赋值运算符>逻辑运算符
可变字符串
可以使用io。stringI()对象或array模块。
format()基本用法
新增一个格式化字符串的函数str.format()
基本语法是通过{}和:来代替以前的%
spilt()可以基于指定分隔符将字符串分割成多个子字符串(存储到列表中)。如果不指定分割符,则默认使用空白字符(换行符/空格符/制表符)。
join()的作用和spilt()作用刚好相反,用于将一系列字符串连接
str()实现数字转换字符串
replace()实现字符串替换
字符串拼接:
如果+两边都是字符串,则拼接
如果+两边都是数字,则加法运算
如果+两边类型不同。则抛出异常
字符串复制:
使用*可以实现字符串复制
不换行打印:
end="任意字符串"
从控制台读取字符串:
使用input()从控制台读取键盘输入的内容
字符串的编码:
使用内置函数ord()可以把字符串转换成对应得Unicode码。
使用内置函数char()可以把十进制数字转化成对应得字符
同一运算符
is 是判断两个标识符是不是引用的同一个对象
is not 是判断两个标识符是不是引用的不同的对象
== 是表示引用变量引用对象的值是否相等
程序基本格式
1.恰当的空格,缩进问题
(1)逻辑行首的空白(空格和制表符)用来决定逻辑行的缩进层次,从而用来决定语句的分组。
(2)语句从新行的第一列开始。
(3)缩进风格统一:
1)每个缩进层次使用单个制表符或4个空格(IDE会自动将制表符设置成4个空格)
2)python用缩进而不是{}表示程序块
2.Python区分大小写
3注释
(1)行注释:每行注释前加#号。当解释器看到#,则忽略这一行#后面的内容
(2)段注释:使用连续的三个单引号(''')。当解释看到''',则会扫描到下一个''',然后忽略他们之间的内容。
去除首尾信息
通过strip()去除字符串首尾指定信息。通过lstripe()去除左字符串指定信息,rstripe去除字符串右边信息。
格式排版
center()、ljust()、rjust()这三个函数用于对字符串实现排版。
isalnum()是否为字母和数字
isalpha()检测字符串是否只由字母组成(含汉字)
isdigit()检测字符串是否只由数字组成
isspace()检测是否为空白页
isupper()是否为大写字母
islower()是否为小写字母
字符串切片slice操作:
【起始偏移量start,终止偏移量end,步长step 】
同时调整多个参数,模型运行非常慢。更换数据预处理的方式。
调参可以画学习曲线,或者进行网格搜索。模型调参,第一步找目标。
泛化误差:当模型在未知数据表现很差时,表明模型泛化能力不够。模型太简单和太复杂泛化误差都会很大。
偏差-方差困境。n_estimator增加,不影响单个模型的复杂度。调参方向:降低模型复杂度。
max_deph有增无减,模型复杂度增加。
当复杂度无法再降低时,就可以不用再tiaozhnegle
[*矩阵]查看列的索引。需要Ytest所带的索引,
使用随机森林填补缺失值。n个数据,特征T有缺失值,把特征T当作标签,作为训练集。遍历所有特征,缺失值最少的特征进行填补,因为一开始需要的缺失值最少。当进行到最后一行时,那么在弥补缺失值最多的数据时,就有足够多的准确数据了。
随机森林填补获取数据集时的缺失值。
sklearn.impute.SimpleImputer轻松填补数据缺失值。
随机森林的回归。
分类树与回归树,MSE均方误差。
回归树衡量指标mse、firedman_mse与MAE
sklearn使用负值的均方误差作为衡量指标,因为表示的是损失。
load_boston是一个标签连续型数据集。
regressor是模型
boston.data完整的矩阵、boston.target是标签。来回验证十次,scoring选择指标进行打分。
一半以上的决策树判断错误,才会导致随机森林才会判断错误。
comb是求和。
相同的训练集与参数,随机森林中的树会有不同的判断结果,选择重要的特征进行提问。
estimators,查看森林中树的参数或属性。每棵树中的random_state不一样,导致每棵树都不一样。
random_state固定,随机森林中的树是固定的,但随机挑选的特征,导致树是不一样。随机性越大,效果越好。
bootstrap用于控制抽样技术的参数。
自主集:从原始训练集中进行n次有放回抽样,得到的数据集。自主集会包含63%的原始数据集元素。剩下37%数据可以作为测试模型的数据,称为袋外数据。
wine.target为wine的标签。
一个自助集里,样本A永远不被抽到的概率:(1-1/n)^n
oob_score训练分数。
apply返回所在叶子节点的索引
predict_proba返回每个样本对应类别的标签的概率。