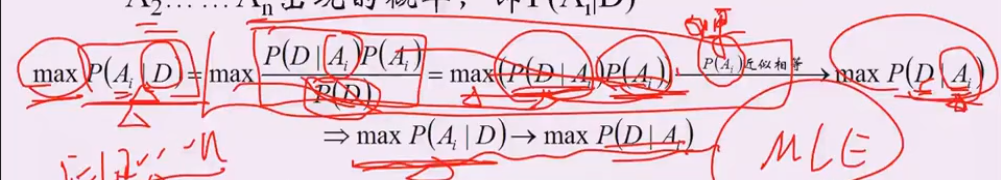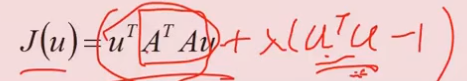- 线性回归
- 极大似然估计解释最小二乘
假设: 误差ξ服从高斯分布(0, δ)

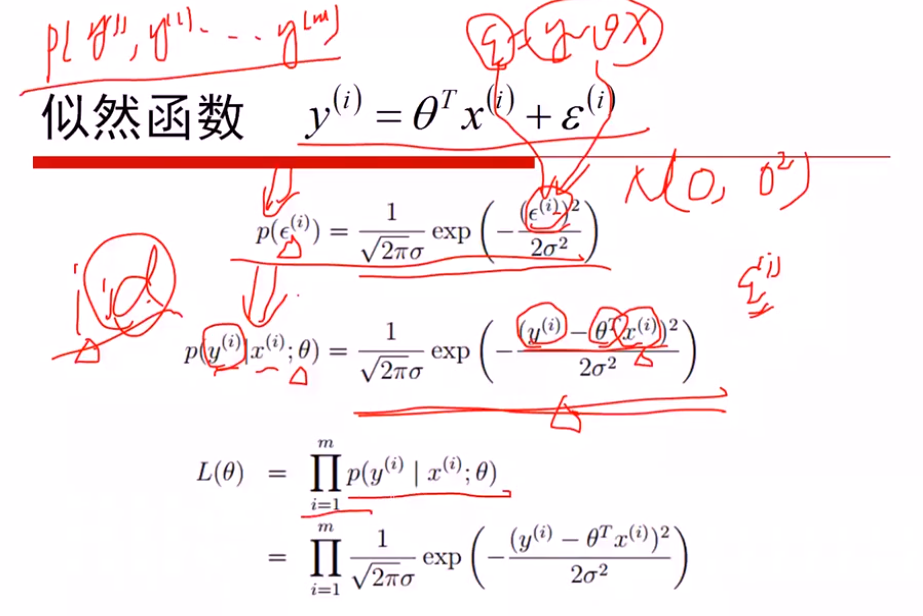

①最大化似然函数,对l(θ)进行简化
max l(θ) 等价于 min(J(θ))
- 1 最小二乘的矩阵推导

注意:
(1)是关于θ的函数,最大化θ参数
(2)J(θ)是一个xTx的凸函数,因为xTx是半正定的,开口向上,xTxθTθ就是关于θ的开口向上的二次函数
- 线性回归复杂度惩罚因子

(1)L2正则,进行对θ惩罚 -- Ridge回归
L1正则, -- Lasso回归
- 解释为什么L1有特征选择能力:
1 拉格朗日角度进行解释
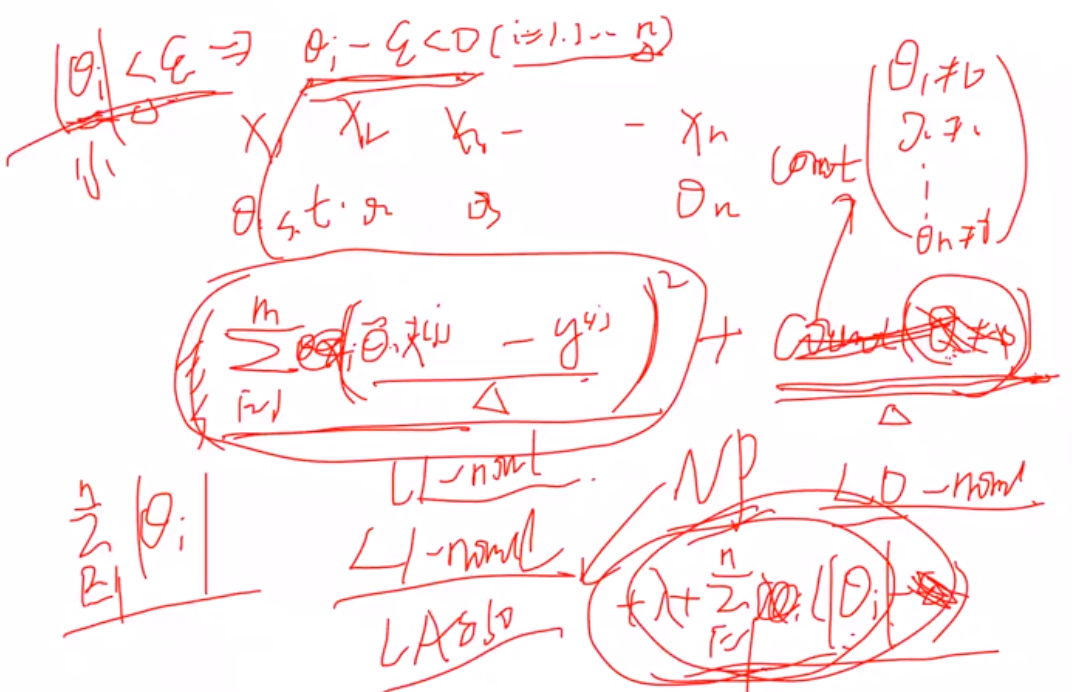
(1) 原本的目标: 希望θ=0就计0,不等于0就计为1,惩罚θ>0时候的数目,但是由于是无解的,因此用L1范数进行近似
推导看手稿:
2 几何解释:

L1约束使得某一个wi是0,稀疏约束
L2使得两个wi都比较小,约束
- L1正则不可导如何解决?
(1)坐标轴下降法
(2)近端梯度近似法... 其余还有很多
- 2 广义逆矩阵求解(伪逆)


(1)当x可逆, θx =y可以直接进行求解,不用进行目标函数最小化求解,因此可以利用SVD进行奇异值分解,求出伪逆矩阵后进行求解
- 3 梯度下降法求解
- Logistics 回归
- 多分类softmax回归
- 技术:
- 梯度下降
- 最大似然估计
- 特征选择