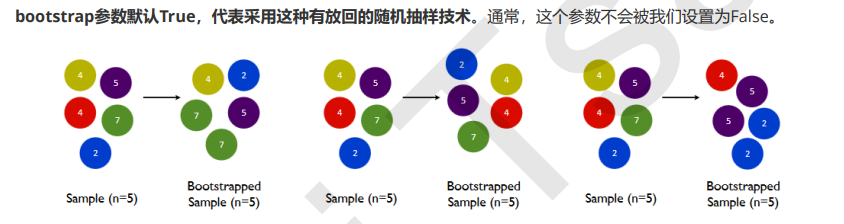
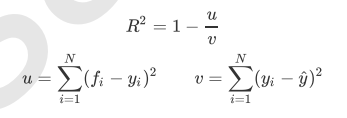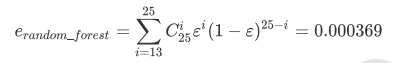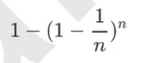Embedded嵌入法
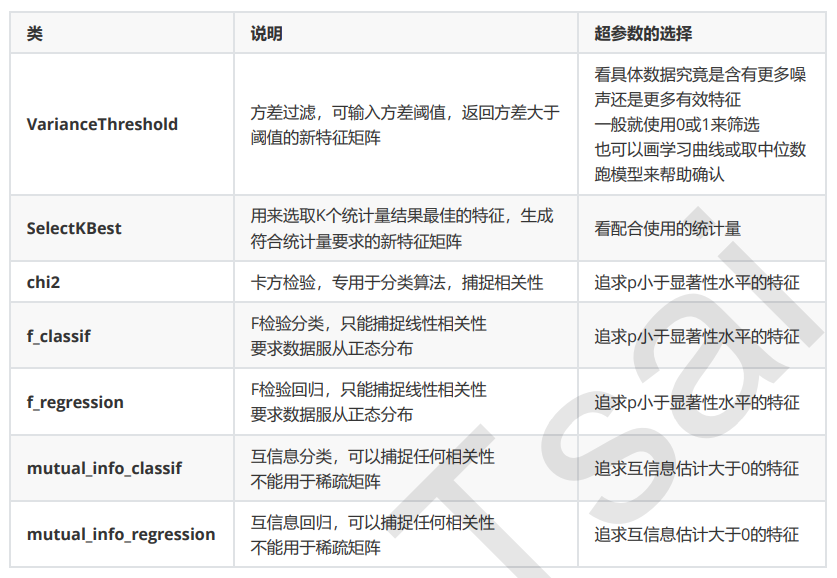
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使 用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和树的集成模型中的feature_importances_属性,可以列出各个特征对树的建立的贡献,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。
过滤法中使用的统计量可以使用统计知识和常识来查找范围(如p值应当低于显著性水平0.05),而嵌入法中使用 的权值系数却没有这样的范围可找——我们可以说,权值系数为0的特征对模型丝毫没有作用,但当大量特征都对 模型有贡献且贡献不一时,我们就很难去界定一个有效的临界值。
嵌入法引入了算法来挑选特征,因此其计算速度也会和应用的算法有很大的关系。如果采用计算量很大,计 算缓慢的算法,嵌入法本身也会非常耗时耗力。并且,在选择完毕之后,我们还是需要自己来评估模型。