线性回归
一、概述
回归的预测结果是连续型变量
二、多元(多个特征)线性回归LinearRegression
1、linear_model.LinearRegression使用的损失函数:SSE(误差平方和)或RSS(残差平方和)
2、最小二乘法:
1)通过最小化真实值与预测值之间的RSS来求解参数
2)最小二乘法求解线性回归是一种无偏估计的方法,要求标签必须服从正态分布
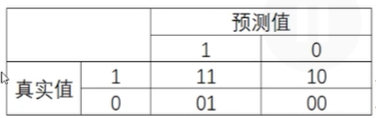
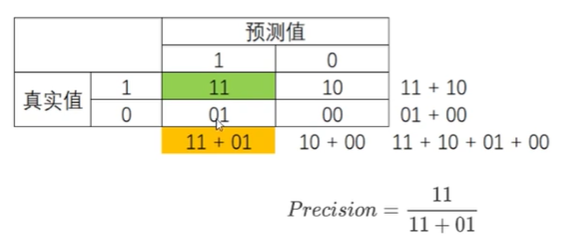
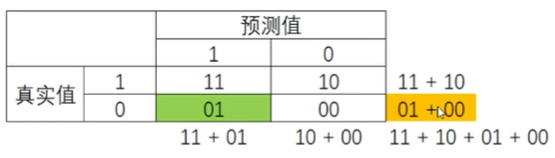
三、回归类的模型评估指标
四、多重共线性:岭回归和Lasso
五、非线性问题:多项式回归
逆矩阵存在的充分必要条件是特征矩阵不存在多重共线性