一个topic有多个partition;
一个partition里面有多个segment文件段;
每个segment文件段里面包含了两个文件:
.index文件,存放的是.log文件数据的索引值,
.log文件,存放的是真实的数据,一旦.log文件达到1GB的时候,就会产生一个新的segment
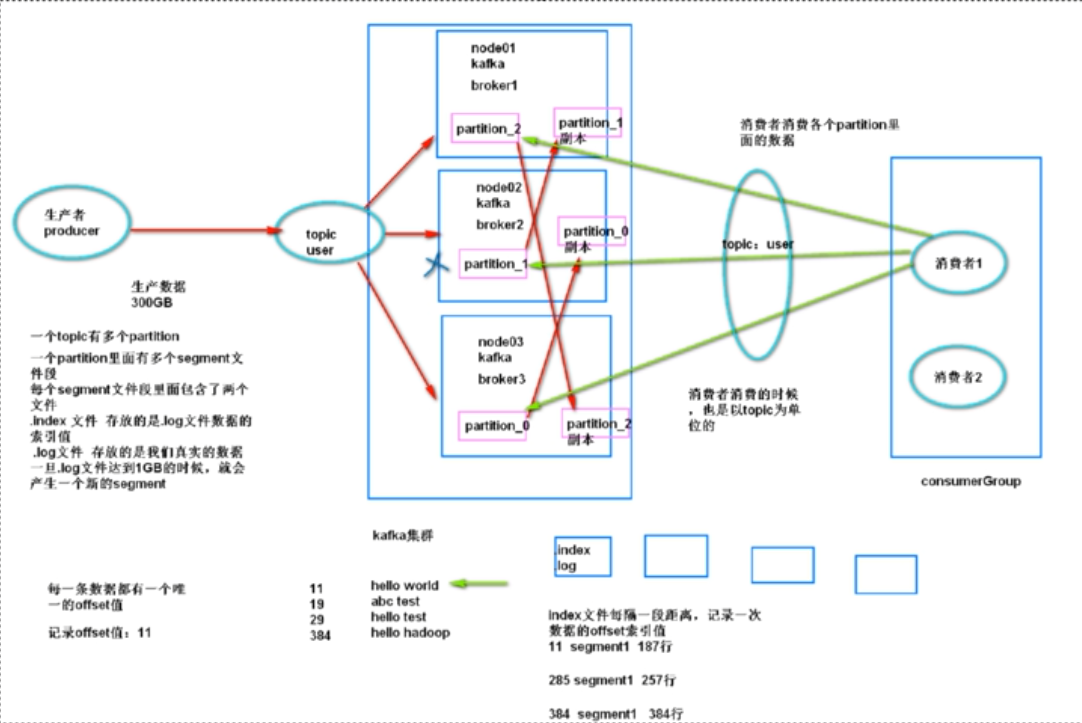
kafka的基本架构:
生产者:producer主要负责生产数据到topic里面去
topic:虚拟的概念,某一类消息的主题,某一类消息都是存放在某一个topic当中
一个topic有多个partition:一个partition里面有多个segment段,每个segment默认1GB
一个segment:一个.index文件 + 一个.log文件
.log:存放用户真实的产生的数据
.index:存放的是.log文件的索引数据
消费者:consumer,主要就是消费topic里面的数据
consumer消费到哪一条数据需要进行记录:offset来进行记录,数据的偏移量,每条数据都有唯一的
kafka需要依赖zk保存一些节点信息,kafka紧耦合zookeeper
kafka当中数据消费的时候,消费者都需要指定属于哪一个消费组
任意时刻,一个分区里面的数据,只能被一个消费组里面的一个线程进行消费
如果调大分区的个数,可以增加分区数据的并行消费的粒度
问:kafka当中的数据消费出现延迟:
加大消费者线程数量,加大分区的个数
partition的个数与线程的个数:
partition个数=线程的个数,刚刚好,一个线程消费一个分区;
partition个数>线程的个数,有线程需要去消费多个分区里面的数据
partition<线程的个数,有线程闲置
kafka当中副本的策略:使用isr这种策略来维护一个副本列表
is synchronize replication:同步完成的副本列表
主分区:可以有多个副本,为了最大程度的同步完成数据,使用多个副本,每个副本都启动线程去复制主分区的数据,尽量保证副本当中的数据与主分区当中的数据一致
如果副本分区当中的数据与主分区当中的数据差别太大,将副本分区移除ISR列表;
如果副本分区的心跳时间比较久远,也会将副本分区移除ISR列表。

