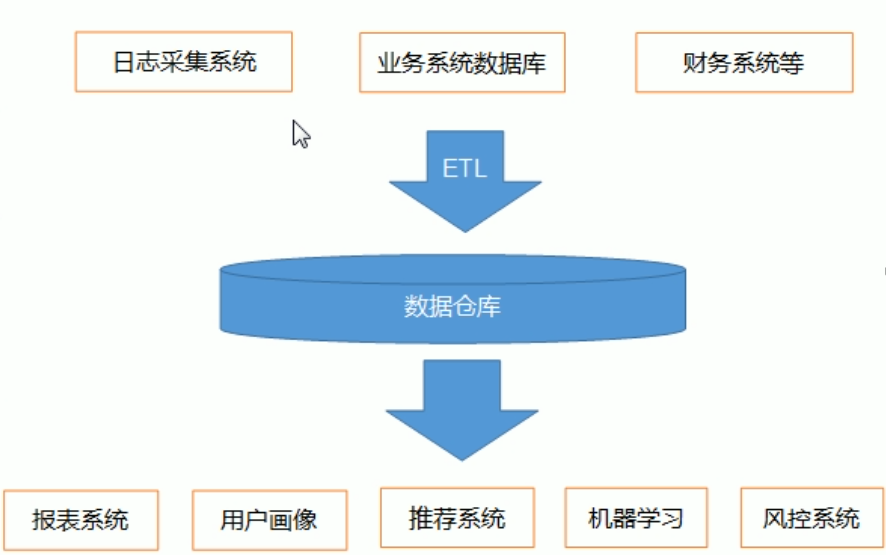
数据仓库,是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
对数据的处理爆发阔:清洗、转义、分类、重组合并、拆分、统计等
hadoop集群的常见端口号:50070、50090、9000、8088、19888
核心配置文件:core.site
两个必备条件:Java、ssh

 已关闭
已关闭
数据仓库,是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
对数据的处理爆发阔:清洗、转义、分类、重组合并、拆分、统计等
hadoop集群的常见端口号:50070、50090、9000、8088、19888
核心配置文件:core.site
两个必备条件:Java、ssh
断点续传:记录
json格式化解析工具
数据生成:
对字段必须熟悉
埋点用户行为数据:
用户在使用产品过程中,与客户端产品交互过程中产生的数据,比如页面浏览、点击、停留、评论、点赞、收藏等
业务交互数据:
业务流程中产生的登录、订单、用户、商品、支付等相关的数据,通常存储在DB找那个,包括MySQL、orcale等。
Nginx:主要负责负载均衡
flume:
三个组件,两个事务
拦截器
监控器ganglia
flume默认内存1GB,在企业中会调整至4GB左右
1.实时采集埋点的用户行为数据
2.实现数据仓库的分层搭建
3.每天定时导入业务数据
4.根据数据仓库中的数据进行报表分析
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
报表系统、用户画像、推荐系统、机器学习、风控系统
redis:内存数据库,存取速度都比较快
数据类型:
string
hash
list
set
zset
运行模式
单机版
主从模式
哨兵模式
redis集群
数据持久化:
RDB:每隔多长时间有多少个key发送变化,就将数据dump到磁盘里面保存,默认开启
AOF:记录操作日志,将客户端操作的日志都记录下来,默认关闭
实际工作两种方式都打开
缓存雪崩:redis数据全部失效
缓存击穿:没有命中缓存当中数据
HBASE nosql数据库
大数据领域里面一个分布式的nosql数据库
rowkey
列族
列
时间戳
多版本
一张HBASE表,有多个region
一个region由两部分组成:一个Hlog+多个store模块
一个store模块:一个memoryStore+多个StoreFile
flush:数据从memoryStory到storeFile
compact:数据从storeFile到Hfile
split:大的Hfile达到10GB的时候,就会进行分裂,region也会一分为二
HBASE的数据读写流程:元数据记录表,HBASE:meta表
ELK:elasticse全文检索框架,也是类似于一个数据库
index
type
document
field
shard
replicat
mappings
settings
聚合查询
kafka:消息队列
作用:解耦,异步,并行
一般用于数据的统一的管理平台
软件框架之间的依赖关系
1.zookeeper依赖jdk
2.hadoop
ha模式:依赖zk
3.hive:依赖hadoop和MySQL
4.flume没有依赖
5.sqoop没有依赖
6.azkaban没有依赖
7.impala依赖hive,必须启动hive,Metastore服务
8.oozie依赖于hadoop
9.hue没有依赖
10.redis依赖C程序,yum -y install gcc-c++
11.HBASE依赖于zookeeper和hadoop
12.elk没有依赖
13.kafka依赖zookeeper
框架总结:
1.zookeeper大数据领域里面一个分布式服务协调框架,主要是帮助其他的框架正常运行
永久节点:
普通永久节点
序列化永久节点
临时节点:客户端一旦断开连接,节点消失
普通临时节点
序列化临时节点
watch机制:类似于监听器
2.hadoop
hdfs:分布式文件存储系统
namenode:主节点,主要用于管理元数据信息
fsimgae:一份比较完整的元数据信息
edits:最近一段时间客户端的操作日志,操作次数达到100w次,还有时间限制1小时
secondarynamenode:主要进行合并fsimage以及edist文件
datanode:数据存储,以block块为单位来进行存储,默认block128M
读取数据的过程:必须掌握
写入数据的过程:必须掌握
第一步:客户端请求namenode上传数据
第二步:namenode校验客户端是否有权限,文件是否存在,校验通过,直接告诉客户端允许上传
第三步:客户端请求namenode第一个文件block块地址
第四步:namenode寻找对应的block块地址返回给客户端
就近原则
心跳比较活跃
磁盘比较空闲
第五步:客户端直接与对应的datanode进行通信,将数据写入到datanode对应的block块里面去,数据以packet为单位进行传输,packet默认是64kb,datanode反向的进行数据校验
MapReduce:
三个key,value对
八个步骤:
第一步:读取文件,解析成key,value对
第二步:自定义map逻辑,接收k1,v1转换成为k2,v2
第三步:分区,相同key的数据发送到同一个reduce里面去,key合并,value形成一个集合
第四步:排序,对数据key2进行排序
第五步:规约,combiner,调优步骤,可选项,比如求平均值不能使用
第六步:分组,key2合并,value形成一个集合
第七步:自定义reduce逻辑,接收k2,v2转换成新的k3,v3输出
第八步:输出k3,v3进行保存
yarn:资源调度管理平台
资源调度方式:
FIFO:先进先出
fair scheduler:公平调度Apache版本使用
capacity scheduler:容量调度器,cdh使用的调度方式
自定义capacity scheduler:配置实现,不同用户提交不同的任务
hive:
数据仓库基本概念:数据仓库主要就是面向数据分析
将hive的元数据信息保存在MySQL里面
独立表模型:
外部表:external,外部表删除表的时候,不会删除hdfs的数据
内部表:删除表的时候,会删除hdfs的数据
分区表:一般与外部表或者内部表搭配使用,分文件夹
partition by
分桶表:一般与外部表或者内部表搭配使用,分文件
cluster by into xxx buckets
hive基本语法
group by
自定义函数
爆炸函数explode
例如lateral view 主要与
分析函数(开窗函数)分组求topN
row_number over
rank over
dens_rank over(partition by xxx order by xxx)
select * ,row_number() over(partition by s_id order by score) from user;
数据存储格式、压缩、调优
数据存储格式:行式存储以及列式存储
行式存储:textFile,sequenceFile
列式存储:orc,parquet
在ods层:使用textFile
在dw层:使用orc存储格式,配合snappy压缩,数据压缩比6:1
原始文件100GB,使用orc格式配合sanppy之后数据大概剩下100/6
hive调优:尽量多掌握几个
map端join
合并小文件
控制map个数以及reduce个数
表的优化
本地模式
推测执行
flume:数据采集工具
离线分析:将数据保存到hdfs里面去,hdfsSink:文件滚动的时长,文件event数据量,文件大小
文件夹滚动策略:多长时间在hdfs上面滚动生成一次文件夹
flume怎么配置将数据发送到hdfs上面去(一般接近128M)
多长时间发送一次数据到hdfs上面去
hdfs.rollInterval
hdfs.rollSize
hdfs.rollSize
多长时间在hdfs上面生成一个文件夹
hdfs.round
hdfs.roundValue
hdfs.roundUnit
实时处理:将数据发送到kafka里面去
sqoop:数据导入导出工具
增量数据怎么解决
减量数据怎么解决:做拉链表
更新数据怎么解决:做拉链表
启动了多少个maptask -m
每天数据库数据量大概有多大
azkaban:任务调度工具
oozie:完全替代azkaban
impala:完全替代hive,比较消耗内存,官方建议内存128GB起步
hue:管理工具,主要与其他的各种框架进行整合
JsonObject.parseObject(value,PaymentInfo.class)
多维分析:举例
1.平台维度
平台销售金额
平台商品销售数量
每个商品销售金额
2.商家维度
商品销售金额
商品销售数量
商铺每个商品销售金额
3.商品维度
每个商品销售金额
每个商品销售数量
尽量不要直接到数据库当中去求取,可以通过实时计算的方法,每来一条数据就进行累加,将最终的结果累加到一起,显示到大屏上面去
kafka主要是应用于大数据平台,做到数据的统一的接入管理
redis内存数据库,存取速度快
CAP理论:
三口锅,但是只有两个锅盖,永远有一口锅盖不住
Consistency:一致性
Availability:可用性
Partition tolerance:分区容错性
在分布式系统中,这三个指标不可能同时做到。最多只能同时满足其中两个条件
kafka满足的是CAP当中的CA:一致性和可用性
不满足partition tolerence,kafka使用ISR尽量避免分区容错
数据采集工具:flume,sqoop
sqoop:增量数据导入
使用ID来做增量导入数据:第一个问题就是导入数据不准确,数据最后一个id没法记录
如果使用增量导入,最好的方式是根据时间点导入
such as:
bin/sqoop import \
--connect \ jdbc://192.168.211.104:3306/userdb \
--username root
--password 123456 \
--table emp \
--incremental append \
--where "create_time > '2018-06-17 00:00:00' \
and create_time < '2018-06-17 23:59:59'"
\
--target-dir /sqoop/increment \
--check-column id \
--m 1
tips:
建表的时候:
creat_time默认值是当前的创建时间
update——time最开始默认值也是当前创建时间,一旦数据更新,就会变为更新的时间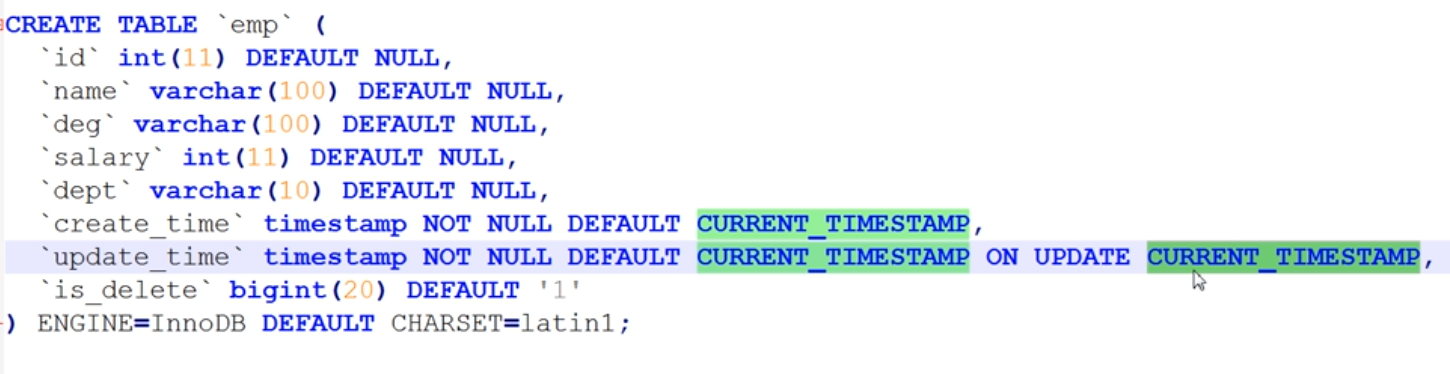
减量数据如何处理:
实际工作中,删除一般都是做假删除处理
删除其实是另一种更新操作,比如设置is_delete列,需要删除时更改状态即可
如果同一条已经导入的数据在某一时刻需要更新状态,需要引入拉链表操作
拉链表:按照时间序列对数据进行排序
按照时间序列的排序,可以看到一条数据的整个过程
kafka当中配置文件说明:
server.properties服务端配置文件
consumer.properties消费者配置文件
producer.properties生产者配置文件
#日志清理是否打开
log.cleaner.enable=true
#用来恢复和清理data数据的线程数量
num.recovery.threads.per.data.dir=1
#日志数据保存的时间 168小时 7天
log.retention.hours=168
kafka当红已经消费掉的数据,没有存在的必要,可以对其进行删除,默认是168小时之后就将过期的segment进行删除
课程回顾:
1.消息队列的基本介绍
消息:在两个应用系统之间传递的数据
消息队列:应用系统之间的通信方式,发送消息之后可以马上进行返回
消息的生产者以及消息的消费者,都是无感知对方存在,可以实现解耦的功能
2、常用的消息队列介绍:
同一类消息队列:基于pub/sub模型
rabbitMQ
activeMQ
rocketMQ
kafka消息队列:基于push/poll,不算是一个标准的消息队列
3.kafka消息队列对比:
面试题:kafka的吞吐量是多大:
kafka的benchmark测试,即压力测试,吞吐量一般在每秒钟处理1-3w条数据左右
4.消息队列应用场景:
应用解耦
异步处理
限流削峰
5.消息队列两种模式:
点对点:两个人之间私聊
发布与订阅:群聊,一个人发消息,所有人都能看到
6.kafka的基本介绍以及kafka的架构图
producer:生产者,主要用于生产数据
consumer:消费者,主要用于消费数据
broker:kafka节点,服务器
topic:虚拟主题,归结于某一类消息的抽象
partition:分区的概念,数据存储于一个个partition中
segment:文件段,每个partition有多个segment断对方,默认达到1GB后就会生成新的segment段
.log:真实数据都是保存在.log文件中
.index:索引数据,对.log文件里面的数据进行索引
offset:偏移量,每条数据都有对应的唯一的偏移量
consumerGroup:消费者组,任意时刻,一个分区里面的数据,只能被同一个组里面的一个线程消费
7.kafka集群操作
8.kafka的JavaAPI
生产者:KafkaProducer
生产数据的分区问题:
第一种分区策略:既没有指定数据key,也没有指定分区号,使用轮询的方式来发送数据;
第二种分区策略:指定数据key,使用key的hashcode来进行数据分区,但一定注意,数据key要是变化的;
第三种分区策略:制定分区号来进行分区;
第四种分区策略:自定义分区,implements Partitioner
面试题:kafka当中数据不均衡,可以使用分区策略进行解决
consumer API:KafkaConsumer
提交offset方式:
第一种:自动提交offset,不可靠
第二种:手动提交offset,等到kafka数据处理完成之后手动提交,(enable.auto.commit false)
第三种:消费完一个分区提交一次offset
第四种:指定分区里面的数据进行消费
数据重复消费以及数据丢失
exactly once:消费且仅消费一次
at least once:至少消费一次
at most once:至多消费一次
kafka等到S他热爱mAPI(了解)
kafka当中log的存储机制以及log的查询机制
重点:log的查找机制:二分查找法
第一步:先确定数据的offset落在哪一个segment段里面
原因:一个partition当中有多个segment段,下一个segment文件命名是上一个segment文件最后一条数据的offset
第二步:查找.index文件,通过二分查找,找出offset对应哪一条数据,或者offset最近的一个offset值是多少
kafka当中数据不丢失机制:
生产者:ack机制
1:主分区以及副本分区都保存好了
0:主分区保存好了(一般使用0)
-1:没有确认机制,不用管数据是否保存好了
消费者:依靠offset来进行保证
broker:使用副本机制来复制数据到副本分区里面去
面试题:数据的存储,都是存储在磁盘里面:磁盘文件为什么能够做到速度这么快?
第一个原因:使用pageCache页缓存技术
第二个原因:顺序的读写磁盘,顺序的读写磁盘的速度比操作内存更快
总结:
1.消息队列介绍(了解)
2.常见消息队列系统
3.消息队列应用场景:
异步处理:
应用解耦
限流削峰
4.消息队列的两种模式
点对点:两个人之间相互通信,都是点对点这种模型
pub/sub::发布与订阅
kafka:push/pull
5.kafka架构:
producer:消息生产者,生产数据,push到kafka的topic里面去
consumer:消息消费者,主要用于消费数据,同一时刻,一个分区里面的数据,只能被一个消费组里面的一个消费者消费
增加分区的个数:可以提高消费的并行度
broker:服务器
topic:虚拟的概念,某一类消息的主题,某一类消息都是存放在某一个topic当中
partition:分区,一个topic可以有多个partition,每个partition里面的数据都是有序的
segment:一个partition里面有多个segment段,一个segment段包含两个文件,
.log:存放用户真实的产生的数据
.index:存放.log文件的索引数据
kafka当中如何保证数据不丢失
1.生产者如何保证数据不丢失
2.消费者如何保证数据不丢失
3.broker如何保证数据不丢失
如何保证producer发送的数据不会丢失?
producer发送数据有两种方式:
同步发送:producer发送一条,topic里面保存一条,保存好了,继续发送下一条
缺点:效率太低
异步发送:你发你的,我收我的
缺点:容易造成数据丢失
通过一次发送一批数据(5000条或者10000条),
使用ack机制(发送消息之前请求应答),消息确认机制,ack的值可以设置为
1:主分区以及所有的副本分区都保存好了
0:主分区保存好了即可,副本恩分区不管
-1:没有任何保证机制,发送完了就不管了
如何阶段broker不会宕机的问题,使用副本机制来同步主分区当中的数据
消费者:优先选择主分区当中的数据进行消费,主分区当中的数据是最完整的
kafka会维护一个ISR分区列表,用于在主分区宕机之后,从ISR列表当中选择一个作为主分区
如何记录消费到了哪一条避免重复消费或者数据丢失?
通过offset来进行记录,可以将offset保存到redis或者HBASE里面去,下次消费的时候就将offset取出来
kafka:的日志寻址机制:
一个topic由多个partition组成
一个partition里面有多个segment文件段
一个segment里面有两个文件
.log文件:存放日志数据的文件
.index文件:索引文件
每当.log文件达到1GB的时候,就会产生一个新的segment
*下一个segment的文件名字,是上一个segment文件最后一条数据的offset值
那么可以使使用二分查找法来查找数据的offset究竟在哪一个segment段里面
如果确定了数据的offset在第一个segment里面,怎么继续快速找到是哪一行数据
.index文件里面存放了一些数据索引值,不会将.log文件里面每一条数据都进行索引,每过一段就索引一次,减少索引文件大小
kafka的log的寻址机制(掌握)
1.第一步:使用折半查找,找数据属于哪一个segment段
2.第二步:通过.index文件来查找数据究竟对应哪一条数据
segment段的命名规则:
下一个segment起始的数据name值,,是上一个segment文件最后一条数据的offset值
问:
1.写入HBASE成功,但是offset提交失败:重复消费
2.写入hbase失败,但是offset提交成功:数据丢失
kafka当中如何保证exactly once机制
3.写入HBASE成功,提交offset成功:正常消费情况
4.写入HBASE失败,提交offset失败:重新进行消费
如果保证
kafka的数据消费模型:
exactly once:消费且仅消费一次
at least once:最少消费一次,可能出现数据重复消费的问题
at most once:至多消费一次,可能出现数据丢失的问题
数据重复消费或者数据丢失的原因造成:offset没有管理好
将offset的值保存到rerdis里面去或者HBASE里面去
默认的offset保存位置:
可以保存到zk里面去,
key保存到kafka自带的一个topic里面去,_consumer_offsets
数据消费:
高阶API,high level API 将offset的值,保存到zk当中,早期kafka版本默认使用high level api进行消费
低阶API,将offset的值保存到kafka的默认topic里面,新的版本都是使用low level API进行消费,将数据的offset保存到一个topic里面去
kafka-stream API开发:kafka新版本的一个流式计算的模块,主要用于流式计算,实时计算
使用kafka-stream API