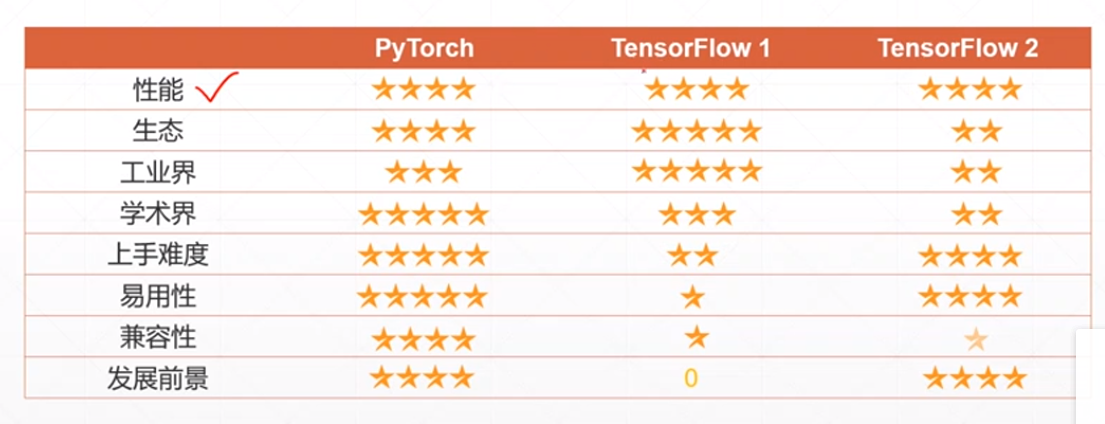
pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层



pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层

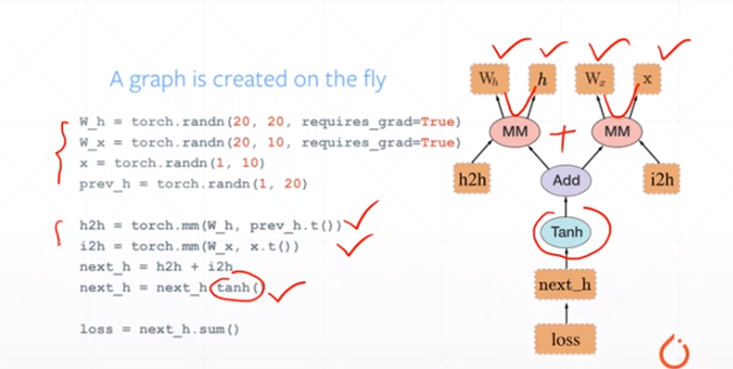
静态图:
define——>run
在最开始就需要定义好公式,给定输入值,得到输出值,而且在运行的过程中无法进行调整

动态图:
可以随时调整公式
linear Regression——我们要估计连续函数的值;
logistic Regression——在上述linear regression的基础上增加了一个激活函数,把y的空间压缩到0-1的范围,0-1可以表示一个概率
classification——所有的可能性概率之和为1
梯度下降法

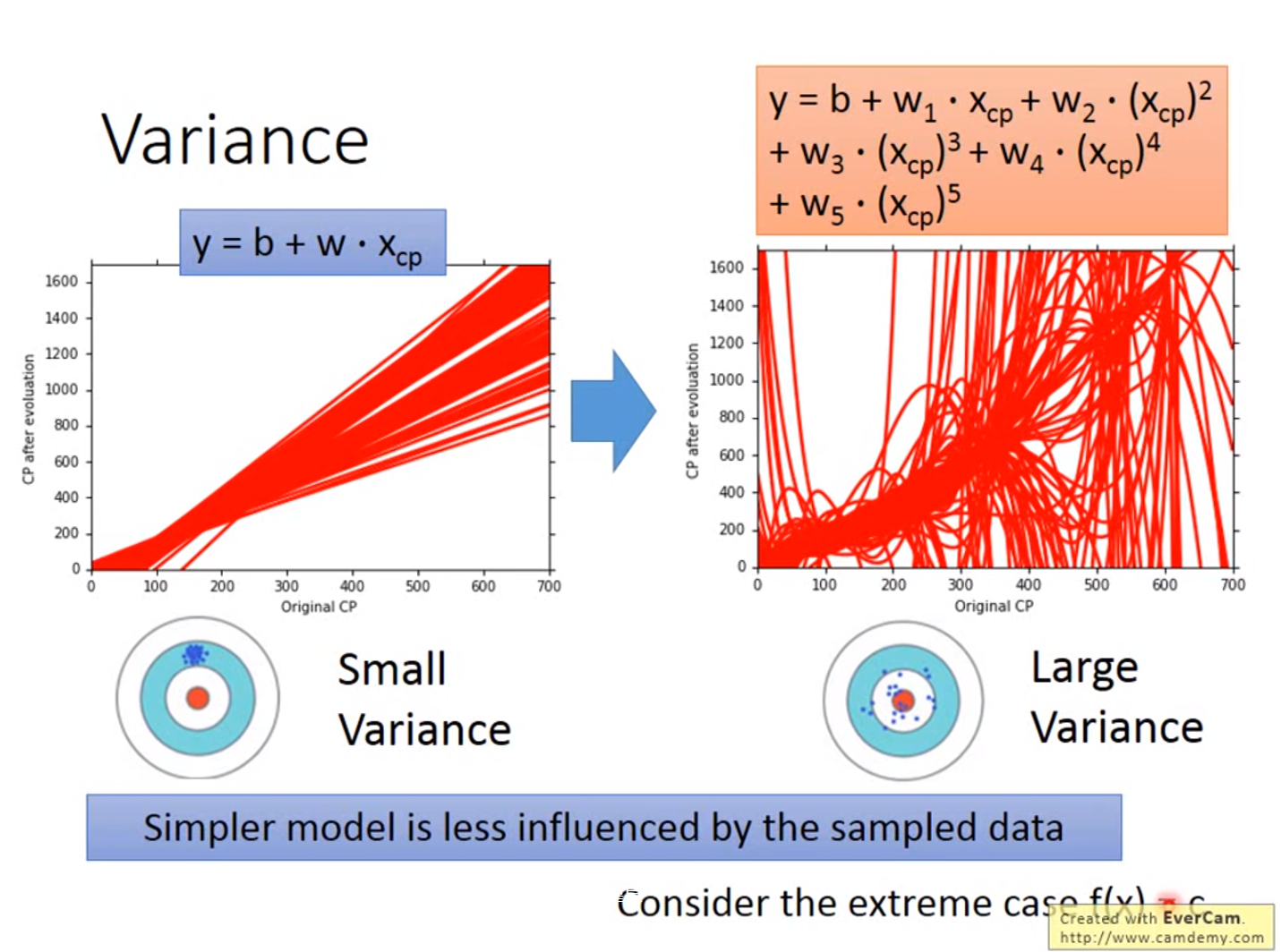
误差来源于两个——一个是bias,还有一个是variance。出现bias是由于开始就没有瞄准靶心;出现vaiance是由于瞄准了靶心,但是发射的时候出现了偏离。我们的目标是低bias和低variance。
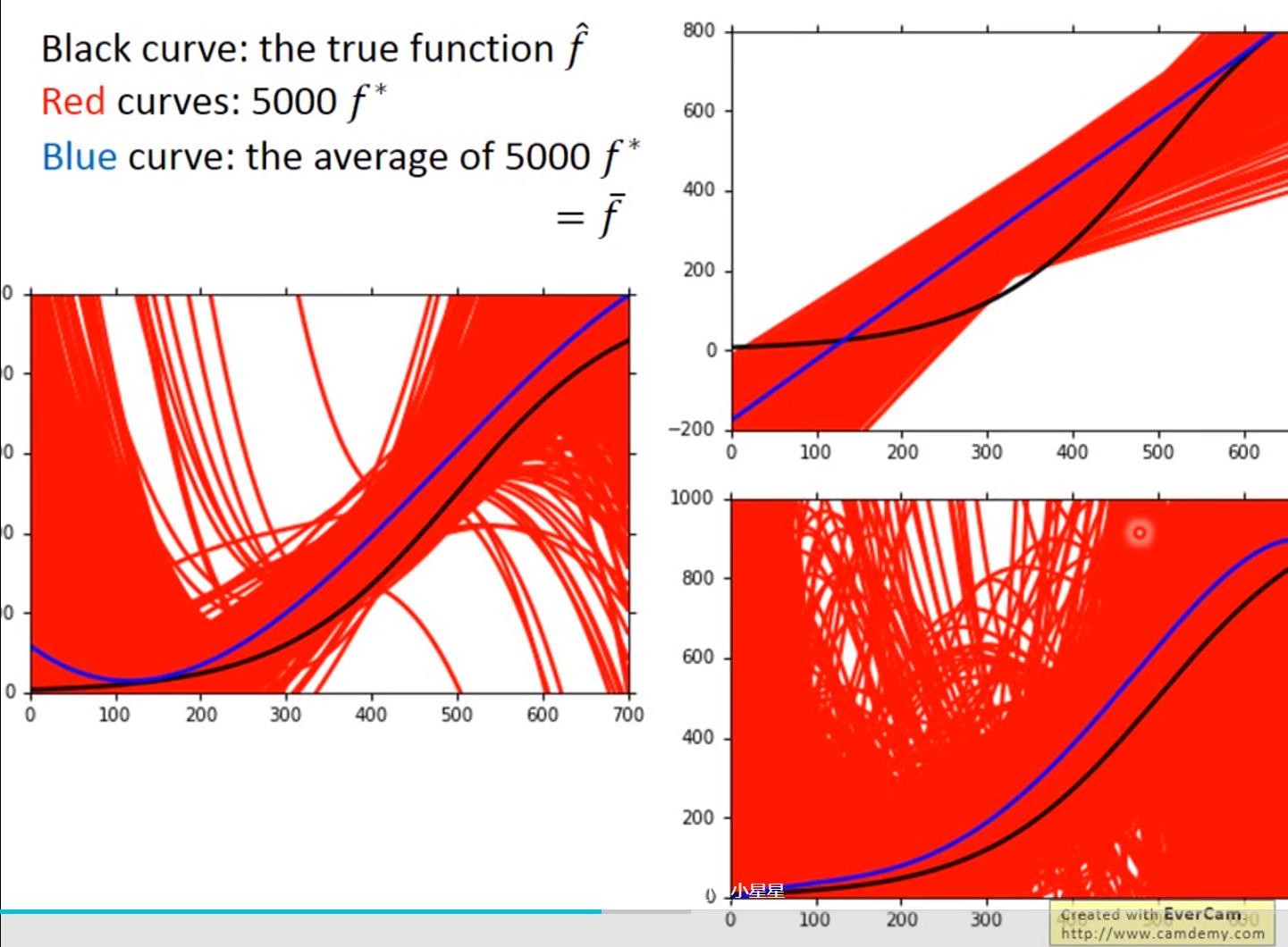
红色的部分是分别在考虑输入值一次方、三次方和五次方函数进行5000次实验的结果,蓝色的线条是将5000次实验结果进行平均即结果
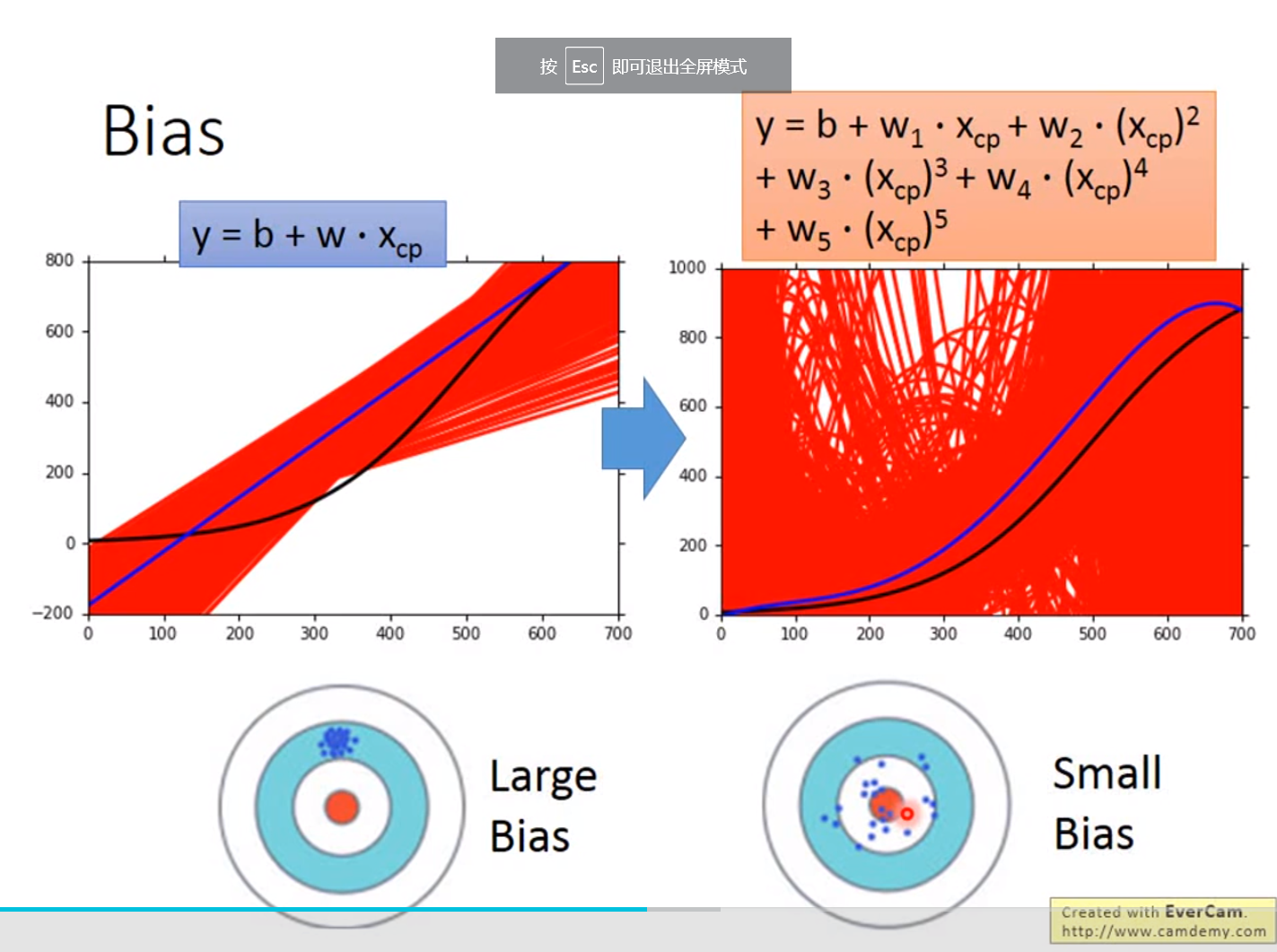

越简单的模型,bias越大,variance比较小;反之,模型越复杂,variance越大,但是平均值却比较接近于期望值
bias较大的情况,问题出现在underfitting;
variance较大的情况,问题出现在overfitting
Diagnosis:
(1)当模型不能拟合训练集时,我们有较大的bias;
(2)当模型可以集合训练集,但是在测试集上出现了较大的损失值,则很大可能上有较大的variance
for bias, redesign模型:
(1)add more feature as input
(2)a more complex model
for variance
(1)more data(增加每次实验的样本量)
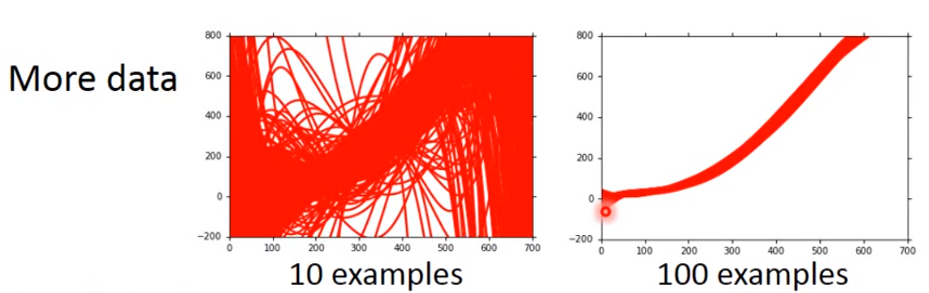
(2)Regularization我们希望曲线越平缓越好

伤害:只包含了比较平滑的曲线,在取值上产生了较大的bias
model selection:
我们想要找到尽可能小的bias和variance来得到最小的损失值
Regression回归
1、应用场景
(1)Stock Market Forecast
(2)Self-driving Car
(3)Recommendation
2、步骤
(1)给一个Model
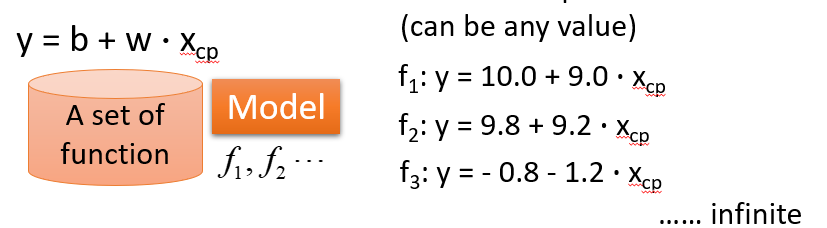
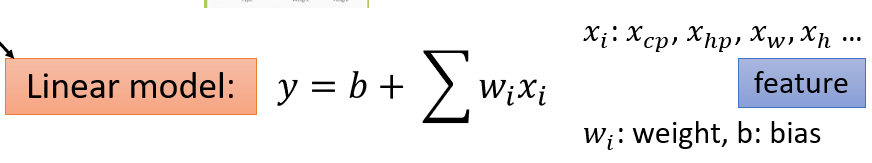
(2)Goodness of Function(函数优度)
输入:a function一个函数
输出:loss funchtion——how bad it is
 Pick the “Best”Function
Pick the “Best”Function
(3)Gradient Descent
梯度下降:初试化w和b这两个参数,不断迭代更新,知道找到最优解,也就是使损失值达到最小的参数值

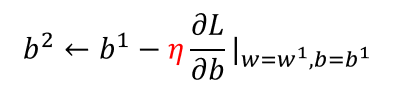
在线性回归里,是不需要担心找不到全局最优解的,因为其三维图形是一圈一圈的等高线,不管从哪个方向都可以找到最优解
how's the results?
训练的目的是损失值最小,但是通过训练集得到的损失值是比测试集得到的损失值小的,为了减少误差,我们需要改进模型——引入了二次方、三侧方和四次方的函数
overfitting——更复杂的模型会得到更不好的结果,所以模型并不是越复杂越好。
what are the hidden factors——pokemon的物种会影响他们值


根据不同的输入值,对不同的物种设置不同 的权重,此时仅设置了输入值的一次方,还可以考虑输入值的二次方函数
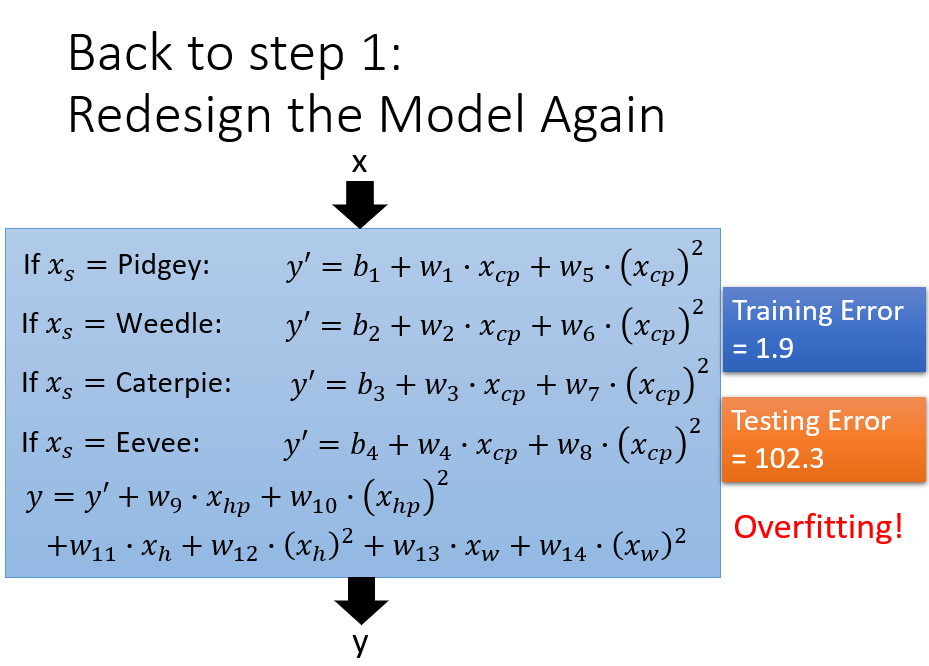
产生了过拟合的结果

设置较为平缓的曲线,由于w的值大于零小于1,当其越接近于0,结果是越为平缓的,前面的系数越大,代表我们越考虑smooth,越可以较多得关注参数w本身的值
pandas时间序列
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
为什么要学习pandas的时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
时间格式化
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
pandas数据重采样
指的是将时间序列从一个频率转化为另一个另一个频率进行处理的过程,将高频率数据转化为低频率为降采样,低频率转化为高频率为升采样
关于索引和复合索引
merge——进行列合并,合并的是相同索引值得列默认的方式是inner,取交集,当没有相同的数的时候取空
思考:对于一组电影数据,如果要对这些数据进行分类,应该如何操作?
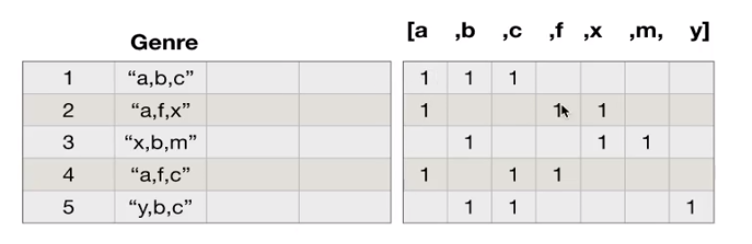
首先,先构一个二维数组,行数等于gener_list的数据量,即取出来genre这一列的数据,通过逗号进行分割,即将每一行数据分割出来一二维数据的形式返回列表中
df["Genre"].str.split(",").tolist()
然后将这个list里面的数据都转换为一维数组且去重
再构建一个新的二维数组,最初的值都为零,行是genre 的数据量,列表是一维数组的数据量,分类最为列索引
字符串的方法

pandas里面计算mean()时,可以直接跳过nan,来返回其他值得平均数
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
pandas的索引
DataFrame的基本属性
为什么要学习pandas?
numpy处理数值型数据;pandas用来处理字符串和时间序列等
pandas的常用数据类型
(1)series——一维、带标签的数组
(2)DataFrame——二维数组

生成随机数的方法
ndarray缺失值填充均值