jre 运行java程序运行环境,运行已有的
要开发java程序,必须安装JDK

 已关闭
已关闭
jre 运行java程序运行环境,运行已有的
要开发java程序,必须安装JDK
字节(Byte):没逢8位是一个字节,这事数据存储最小单位。
1、二进制 逢二进一 1+1+1=11
2、十进制数字转换成二进制 除以2 余数
3、了解原理,可以用计算器计算
Java语言之父 詹姆斯·高斯林 (James Gosling) 。
java5.0 java8.0 版本更新较多。
学习资料下载完成,开始学习
from pyplot as plt 重命名,简化
temperature是气温, 100度很吓人啦 XD
机器学习:使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。(强调学习 而不是专家系统)
有监督
无监督
强化学习(带反馈)
机器学习:数据清洗/特征选择;确定算法模型/参数优化;结果预测
不能解决:大数据存储/并行计算;做一个机器人
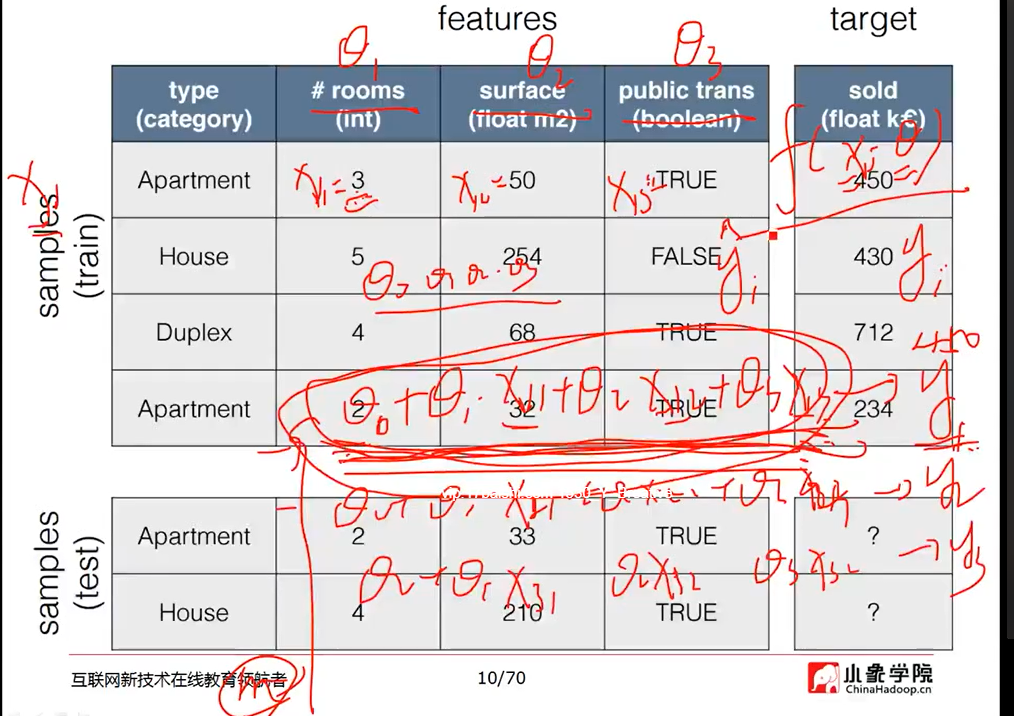
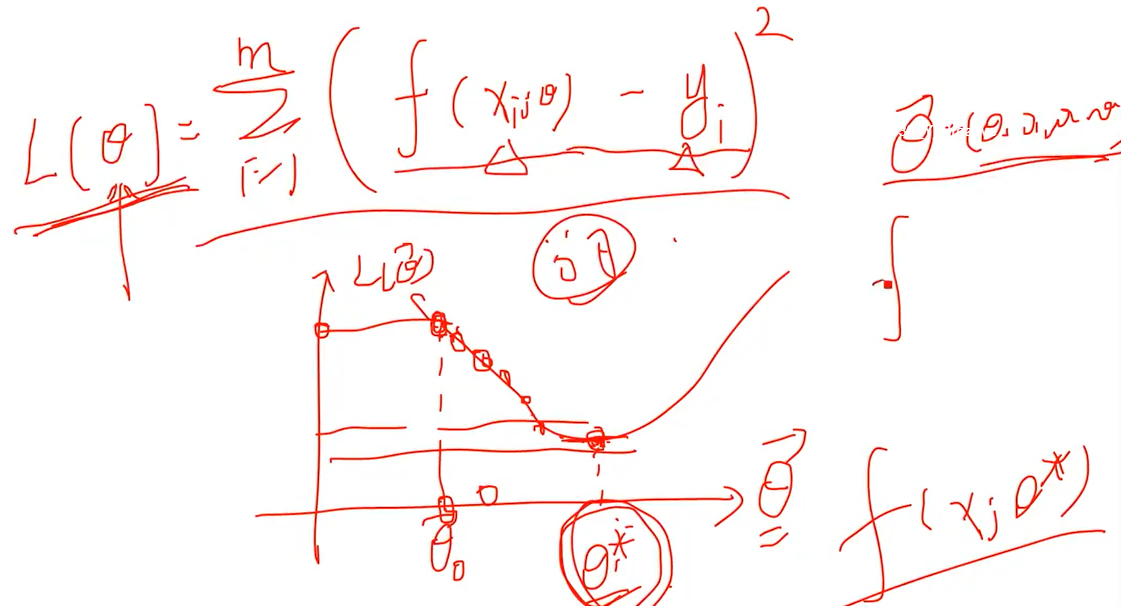
目标函数取最小称 损失函数
数据收集--->数据清洗----->特征工程----->数据建模












hessian矩阵 对称--》4>0 二阶行列式>0----》正定---->凸函数
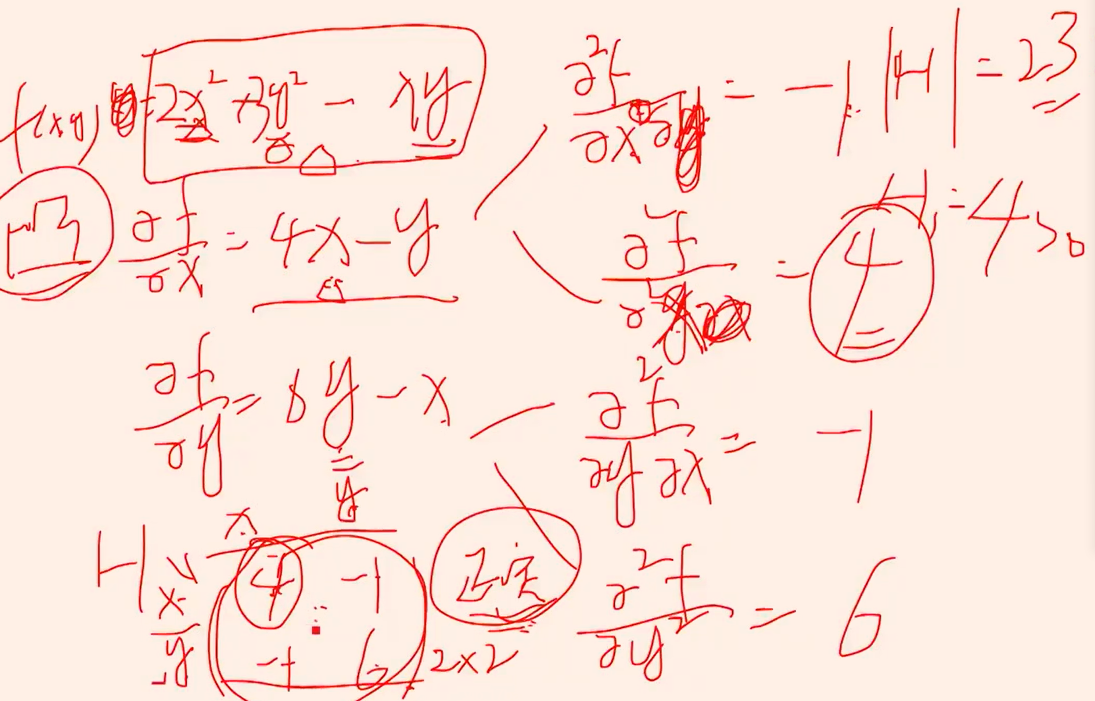
numpy读取数据
np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
转置t.T()
t1.reshape(1,24) #修改数组形状
t1.flatten() #展开 二维降成一维
t1+2 #数组每个值都加2 (广播机制)
0除以0得到nan(不是一个数字),其他数字除以0得到inf(无穷的意思)
t6+t5 #对应位置的数据计算
matplotlib
plt.figure(figsize=(20,8),dpi=80)
plt.savefig('./sig.png')
plt.xticks(x) #x的每个值
plt.xticks((1,26))#调整步长
matplotlib
1.什么是matplotlib
主要做数据可视化,模仿matlab
安装conda install matplotlib
2.matplotlib基本要点
axis轴,指的是x或y轴
from matplotlib import pyplot as plt
x= range(2,26,2)
y=[15,13,14.5,17,20,25,26,26,24,22,18,15]
plt.plot(x,y)
plt.show()
提出问题
准备数据(数据清洗)
分析数据
获得结论
成果可视化
事件:样本点的合集
事件运算:
包含,等价,对立(逆事件)
AUB, A,B事件的并
A∩B=AB,A,B事件的交集
AB=空集, A∪B=A+B 称为和
A-B=AB(逆)
交换律A∪B=B∪A, AB=BA
结合律(A∪B)∪C=A∪(B∪C),ABC=A(BC)
分配律(A∪B)∩C=AC ∩ BC
(A∩B)∪C=(A∪C)∩(B∪C)
德摩根定理:分开反号
pandas时间序列
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
为什么要学习pandas的时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
时间格式化
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
pandas数据重采样
指的是将时间序列从一个频率转化为另一个另一个频率进行处理的过程,将高频率数据转化为低频率为降采样,低频率转化为高频率为升采样
关于索引和复合索引
merge——进行列合并,合并的是相同索引值得列默认的方式是inner,取交集,当没有相同的数的时候取空
思考:对于一组电影数据,如果要对这些数据进行分类,应该如何操作?
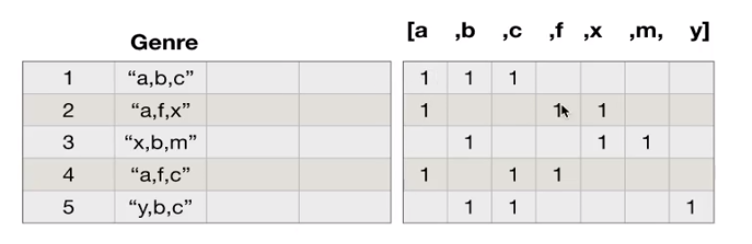
首先,先构一个二维数组,行数等于gener_list的数据量,即取出来genre这一列的数据,通过逗号进行分割,即将每一行数据分割出来一二维数据的形式返回列表中
df["Genre"].str.split(",").tolist()
然后将这个list里面的数据都转换为一维数组且去重
再构建一个新的二维数组,最初的值都为零,行是genre 的数据量,列表是一维数组的数据量,分类最为列索引