文本特征抽取:Count
功能:
文本分类
情感分析
默认对于单个英文字母或者单词:没有不统计
词组分类器:jie'ba

 已关闭
已关闭
文本特征抽取:Count
功能:
文本分类
情感分析
默认对于单个英文字母或者单词:没有不统计
词组分类器:jie'ba
format 函数可以接受不限个参数,位置可以不按顺序
感觉补充和对齐要在用的时候查表。。。直接记不太容易。
>>> a = "我是{0},我的存款有{1:.2f}"
>>> a.format("高崎",12414514.12313)
SyntaxError: invalid character ',' (U+FF0C)
>>> a.format("高崎",12414514.12313)
'我是高崎,我的存款有12414514.12'
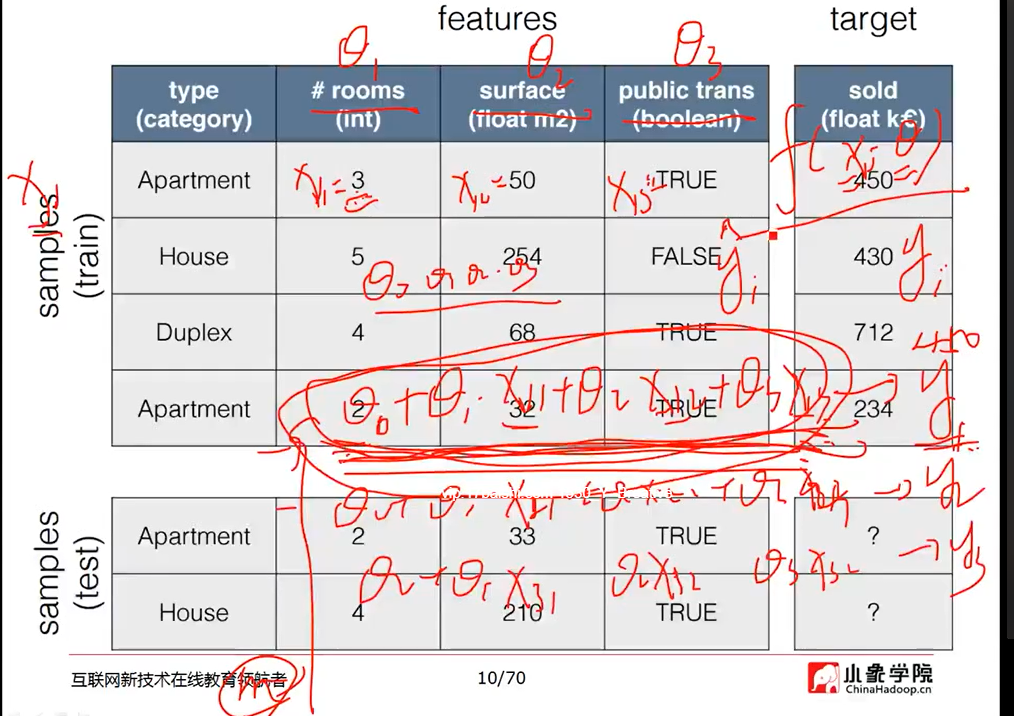
特征抽取:特征值化
字典数据特征抽取:对字典数据进行特征值化
DictVectorizer语法:
字典数据抽取:将字典中的一些类别数据,分别转换成一些数值。
数组形式:有类别的这些特征,先要转换字典数据
pandas数据处理
:缺失值,数据转换,重复值(不用处理)
sklearn:对特征进行处理
特征值(具体特征:身高/体重)->目标值(具体要达到的目的:如区分男女)
深度学习
_.startwith()
在字符串的驻留机制
a,b同时使用一个对象(仅包含字母、数字、_ )
join !!!
拼接合并
ord() 把字符转换成Unicode码
chr() 把。。。。
神经网络和BP算法
为什么会提出神经网络解决问题
神经网络:大量的结构简单、功能相近的神经元节点按一定的体系架构连接成的网状结构——模拟大脑结构
作用:
分类
模式识别
连续值预测
总的来说就是建立一种输入输出的映射关系;
人工神经网络
神经元:输入向量、权重、偏执
一般浅层网络是3~5层
前馈神经网络:
同一层的神经元之间没有相互连接,层间信息的传送只沿着一个方向进行;
学习的过程实际上是对权重的更改
目标:输出和实际输出越接近越好
梯度下降:
随机梯度下降算法:梯度下降
在传入模型的开始,首先要对数据预处理、特征提取、特征选择、再到推理、预测或者识别
布尔值 true false
链式赋值
隐马可夫链,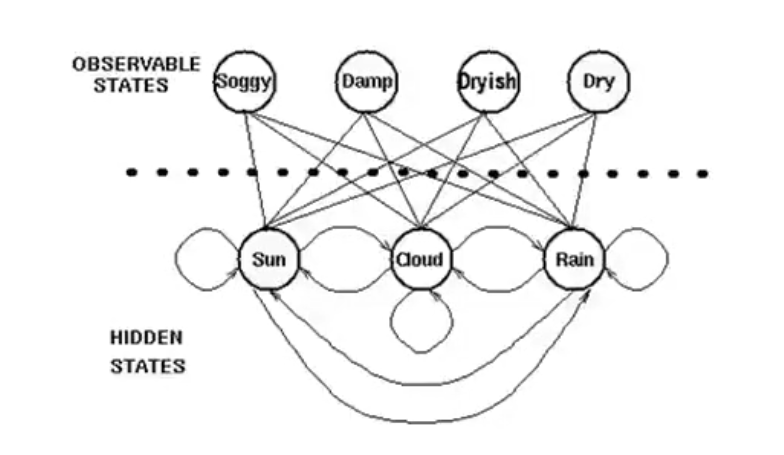
期望不能反映收益,
花了一点时间看完视频,复习了一些基础知识,像turtle函数,平时不用都已经忘记有这个东西了,重新拾起感觉还可以,再是程序的构成、变量的声明之类的,讲的很详细。
print('a')
print('b')
print('c')
代码保存在D盘python_1文件夹内
机器学习:使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。(强调学习 而不是专家系统)
有监督
无监督
强化学习(带反馈)
机器学习:数据清洗/特征选择;确定算法模型/参数优化;结果预测
不能解决:大数据存储/并行计算;做一个机器人
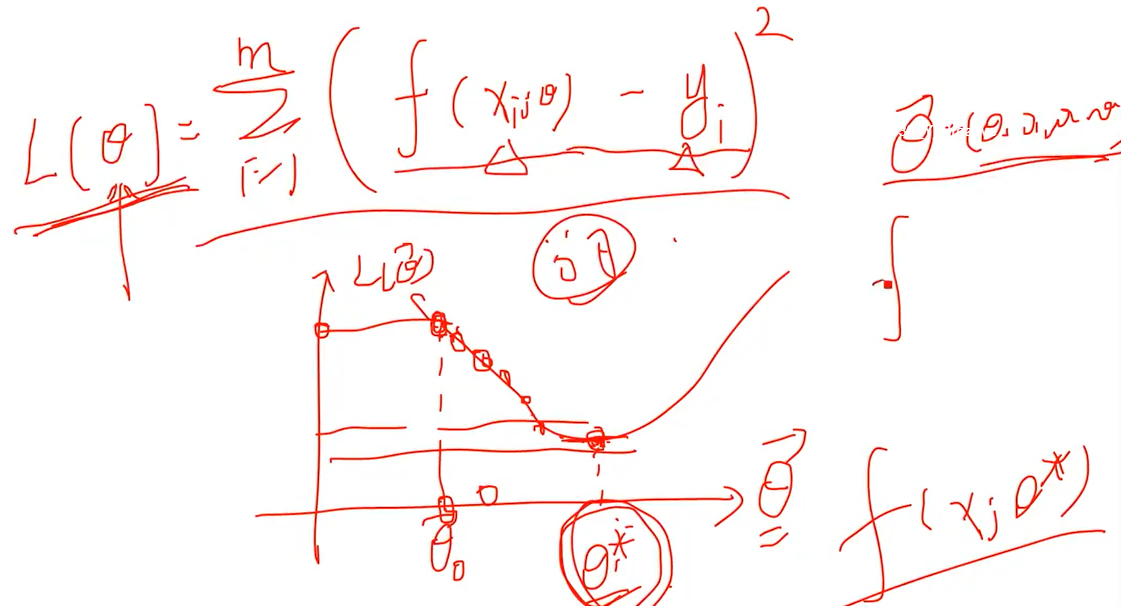
目标函数取最小称 损失函数
数据收集--->数据清洗----->特征工程----->数据建模










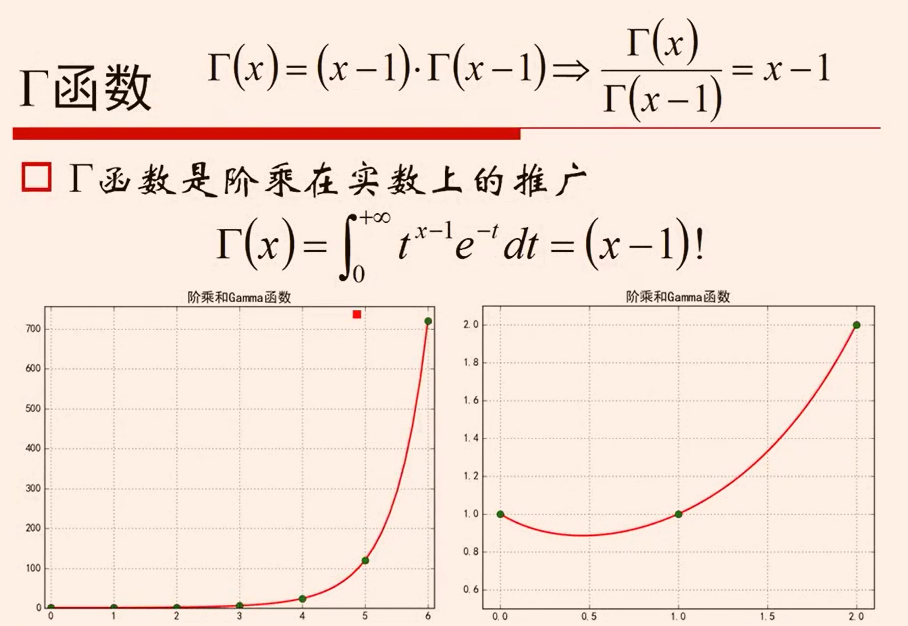


hessian矩阵 对称--》4>0 二阶行列式>0----》正定---->凸函数
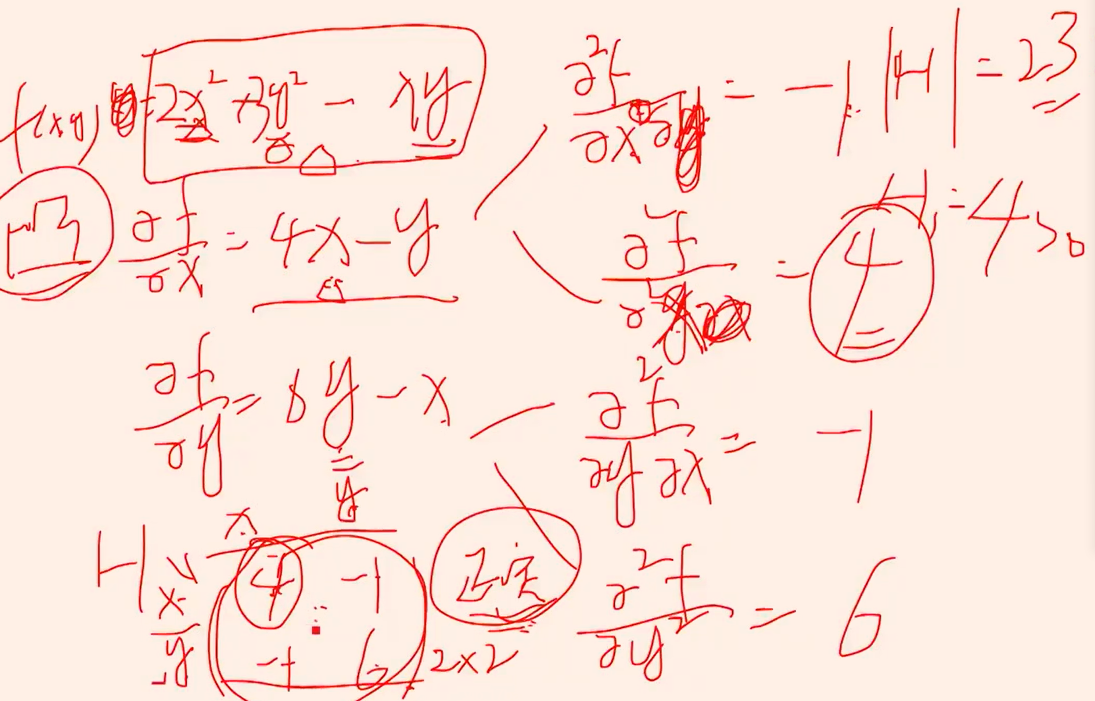
类.mro()显示类的层结构
dir()查看类属性
子类中重写父类他函数
事件:样本点的合集
事件运算:
包含,等价,对立(逆事件)
AUB, A,B事件的并
A∩B=AB,A,B事件的交集
AB=空集, A∪B=A+B 称为和
A-B=AB(逆)
交换律A∪B=B∪A, AB=BA
结合律(A∪B)∪C=A∪(B∪C),ABC=A(BC)
分配律(A∪B)∩C=AC ∩ BC
(A∩B)∪C=(A∪C)∩(B∪C)
德摩根定理:分开反号