SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
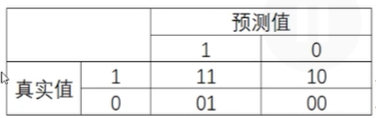
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
6个指标
1、准确率Accuracy

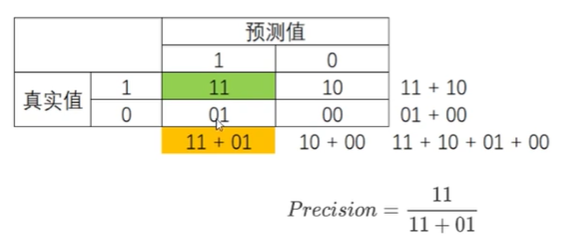
2、精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂


SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
6个指标
1、准确率Accuracy
2、精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂
SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
3)6个指标
准确率Accuracy
SVC模型评估指标
核变换:把数据投影到
1、函数contour([x,y],z,[levels])用来绘制等高线
x,y:平面所有点横纵坐标,必须是二维,选填
z表示x,y对应坐标点的高度,必填
levels:默认显示所有等高线,可不填,填写整数n显示n个数据区间,填写数组或列表(递增顺序)显示对应高度等高线
2、绘制等高线的步骤:
制作网格
SVM支持向量机
一、概述
SVM功能强大,可以进行有监督学习、无监督学习、半监督学习
SVM如何工作?在分布中找到一个超平面(比所在空间小一维,是一个空间的子空间)作为决策边界,使模型的分类误差尽可能小。
支持向量机是一个最优化问题,目的是找出边际最大的决策边界(通过损失函数)。边际(d)是超平面往两边移动,直到碰到最近的样本停下得来的。拥有更大边际的决策边界,在分类中泛化误差更小,边际很小会过拟合。因此,支持向量机又叫做最大边际分类器。
二、sklearn.svm.SVC
1、线性SVM的损失函数
SVM支持向量机
一、概述
SVM功能强大,可以进行有监督学习、无监督学习、半监督学习
SVM如何工作?在分布中找到一个超平面(比所在空间小一维,是一个空间的子空间)作为决策边界,使模型的分类误差尽可能小。
支持向量机是一个最优化问题,目的是找出边际最大的决策边界(通过损失函数)。边际(d)是超平面往两边移动,直到碰到最近的样本停下得来的。拥有更大边际的决策边界,在分类中泛化误差更小,边际很小会过拟合。因此,支持向量机又叫做最大边际分类器。
二、
SVM支持向量机
一、概述
可以进行有监督学习、无监督学习、半监督学习
二、
矢量量化本质是一种降维应用,特征选择降维:选取贡献大的特征;PCA降维:聚合信息;矢量量化降维:同等样本量上(不改变样本和特征数目)压缩信息大小
3)重要参数max_iter&tol:让迭代提前停下来,数据量太大可以使用
max_iter:默认300,单次运行kmeans算法的最大迭代次数
tol:默认1e-4,两个迭代之间inertia下降的量,若小于tol设定的值,迭代就会停下
2)重要参数init&random_state&n_init(初始质心相关)质心选择的好,模型收敛更快,迭代次数更少
init:默认"k-means++",决定初始化方式,通常不改
random_state:控制每次初始质心的位置相同,不设置则会在每个随机数种子下运行多次,选择结果最好的随机数种子
n_init:默认为10,每个随机数种子运行次数,希望更精确则增大
重要属性n_iter_:迭代次数
三、聚类算模型的评估指标
思路:由于KMeans目标是簇内差异小,簇外差异大,因此可以通过衡量簇内差异来衡量聚类效果
1、标签y已知(最好用分类)
互信息分、V-measure、调整兰德系数,三者都是越高越好,前两个取值[0,1],最后一个取值[-1,1]
2、标签y未知:
1)轮廓系数
1)评价簇内稠密程度、簇间离散程度。样本与所在簇内其他样本相似度为a,其他簇内样本相似度为b,用平均距离计算。a越小,b越大,越好。
2)轮廓系数是对每一个样本进行计算,公式为s=(b-a)/max(a,b),范围:(-1,1)
轮廓系数处于(0,1):聚类好,越接近1越好
处于(-1,0):聚类不好
3)使用sklearn.metrics中的silhouette_score计算,返回所有轮廓系数的均值,silhouette_samples返回每个样本的轮廓系数
from sklearn.metrics import silhouette_score
silhouette_score(x,y_pred)
2)卡林斯基-哈拉巴斯指数CHI
from sklearn.metrics import calinski_harabasz_score
越高越好,比轮廓系数快,数据量大时使用
3)戴维斯-布尔丁指数
4)权变矩阵
三、聚类算模型的评估指标
思路:由于KMeans目标是簇内差异小,簇外差异大,因此可以通过衡量簇内差异来衡量聚类效果
1、标签y已知(最好用分类)
互信息分、V-measure、调整兰德系数,三者都是越高越好,前两个取值[0,1],最后一个取值[-1,1]
2、标签y未知:轮廓系数
1)评价簇内稠密程度、簇间离散程度。样本与所在簇内其他样本相似度为a,其他簇内样本相似度为b,用平均距离计算。a越小,b越大,越好。
2)轮廓系数是对每一个样本进行计算,公式为s=(b-a)/max(a,b),范围:(-1,1)
轮廓系数处于(0,1):聚类好,越接近1越好
处于(-1,0):聚类不好
3)使用sklearn.metrics中的silhouette_score计算,返回所有轮廓系数的均值,silhouette_samples返回每个样本的轮廓系数
from sklearn.metrics import silhouette_score
silhouette_score(x,y_pred)
三、聚类算模型的评估指标
思路:由于KMeans目标是簇内差异小,簇外差异大,因此可以通过衡量簇内差异来衡量聚类效果
1、标签y已知(最好用分类)
互信息分、V-measure、调整兰德系数,三者都是越高越好,前两个取值[0,1],最后一个取值[-1,1]
2、标签y未知:轮廓系数
1)评价簇内稠密程度、簇间离散程度。样本与所在簇内其他样本相似度为a,其他簇内样本相似度为b,用平均距离计算。a越小,b越大,越好。
2)轮廓系数是对每一个样本进行计算,公式为s=(b-a)/max(a,b),范围:(-1,1)
轮廓系数处于(0,1):聚类好,越接近1越好
处于(-1,0):聚类不好
一、概述
1、无监督学习:训练时只需要一个特征矩阵x,不需要标签y,例如PCA
2、聚类(无监督分类)VS 分类
1)在已经知晓的类别上,给未知的样本标上标签(分类);在完全不知道标签的情况下,探索分布上的分类(聚类)
2)分类结果确定,聚类结果不确定
3、sklearn中的聚类算法(类和函数两种表现形式)输入数据可以是标准特征矩阵,也可以是相似性矩阵(行和列都是n_samples),可以使用sklearn.metric.pairwise模块中函数获取相似性矩阵
4、簇中所有数据坐标均值为这个簇的质心坐标,簇k是一个超参数,kmeans追求的是能让簇内平方和inertia最小的质心(最优化问题,逻辑回归也是最优化问题)
5、KMeans算法时间复杂度为O(k*n*T),k为簇数,n为样本数,T为迭代次数,但这种算法很慢,但是最快的聚类算法,
二、sklearn.cluster.KMeans
1、重要参数
1)n_clusters:分几个簇,可以通过画图确定分几个
2、重要属性
1)labels_,查看聚好的类别,每个样本对应的类
2)cluster_centers_。查看质心
3)inertia_,查看总距离平方和。分的簇越多,inertia越低,可以降低至0。k值一定的情况下,inertia越低,聚类效果越好。
3、接口fit_predict(x):fit后使用,将x分到已经聚好的类中
1)cluster=KMeans(n_clusters=3,random_state=0).fit(x)
cluster.labels_
cluster=KMeans(n_clusters=3,random_state=0).fit(x)
cluster.fit_predict(x)
结果相同
2)为什么需要fit_predict(x)?数据量太大时,可以先切出一点数据训练,找质心,其它数据用这个接口预测,减少计算量,结果不一样但可以接近。
cluster_smallsub=KMeans(n_clusters=3,random_state=0).fit(x[:200])
y_pred_=cluster_smallsub.predict(x[200:])
有一些算法天生没有损失函数(衡量拟合效果)
聚类算法不需要调用接口transform(),.fit(x)后求出质心,聚类已经完成,但之后可以用
RFM模型,漏斗分析,AARRR模型
一、概述
1、无监督学习:训练时只需要一个特征矩阵x,不需要标签y,例如PCA
2、聚类(无监督分类)VS 分类
1)在已经知晓的类别上,给未知的样本标上标签(分类);在完全不知道标签的情况下,探索分布上的分类(聚类)
2)分类结果确定,聚类结果不确定
3、sklearn中的聚类算法(类和函数两种表现形式)输入数据可以是标准特征矩阵,也可以是相似性矩阵(行和列都是n_samples),可以使用sklearn.metric.pairwise模块中函数获取相似性矩阵
4、簇中所有数据坐标均值为这个簇的质心坐标,簇k是一个超参数,kmeans追求的是能让簇内平方和inertia最小的质心(最优化问题,逻辑回归也是最优化问题)
5、KMeans算法时间复杂度为O(k*n*T),k为簇数,n为样本数,T为迭代次数,但这种算法很慢,但是最快的聚类算法,
有一些算法天生没有损失函数(衡量拟合效果)
RFM模型,漏斗分析,AARRR模型
一、概述
1、无监督学习:训练时只需要一个特征矩阵x,不需要标签y,例如PCA
2、聚类(无监督分类)VS 分类
1)在已经知晓的类别上,给未知的样本标上标签(分类);在完全不知道标签的情况下,探索分布上的分类(聚类)
2)分类结果确定,聚类结果不确定
3、sklearn中的聚类算法(类和函数两种表现形式)输入数据可以是标准特征矩阵,也可以是相似性矩阵(行和列都是n_samples),可以使用sklearn.metric.pairwise模块中函数获取相似性矩阵
4、簇中所有数据均值为这个簇的质心,簇k是一个超参数
RFM模型,漏斗分析,AARRR模型
一、概述
1、无监督学习:训练时只需要一个特征矩阵x,不需要标签y,例如PCA
2、聚类(无监督分类)VS 分类
1)在已经知晓的类别上,给未知的样本标上标签(分类);在完全不知道标签的情况下,探索分布上的分类(聚类)
2)分类结果确定,聚类结果不确定
3、sklearn中的聚类算法(类和函数两种表现形式)输入数据可以是相似性矩阵(行和列都是n_samples),可以使用sklearn.metric.pairwise模块中函数获取相似性矩阵
RFM模型,漏斗分析,AARRR模型
一、概述
1、无监督学习:训练时只需要一个特征矩阵x,不需要标签y,例如PCA
2、聚类(无监督分类)VS 分类
1)在已经知晓的类别上,给未知的样本标上标签(分类);在完全不知道标签的情况下,探索分布上的分类(聚类)
2)分类结果确定,聚类结果不确定
RFM模型,漏斗分析,AARRR模型