loss及其梯度
典型的loss函数 有:
(1)均方差
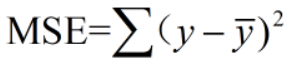
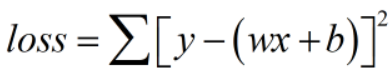
注意:MSE不同于二范数
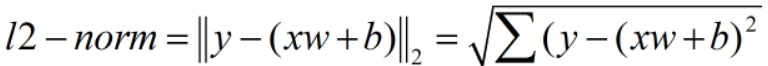
MSE不开根号!
求导
(2)Cross Entropy Loss
可以用于二分类、多分类问题,经常使用softmax激活函数


loss及其梯度
典型的loss函数 有:
(1)均方差
注意:MSE不同于二范数
MSE不开根号!
求导
(2)Cross Entropy Loss
可以用于二分类、多分类问题,经常使用softmax激活函数
激活函数及其梯度
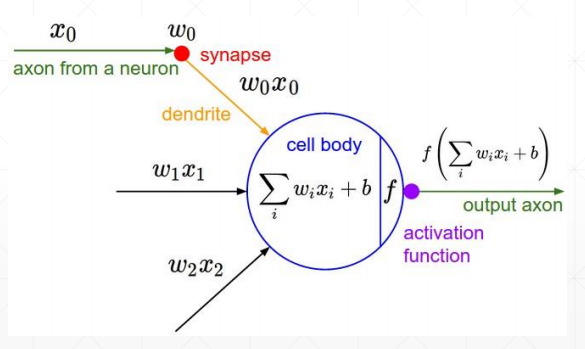
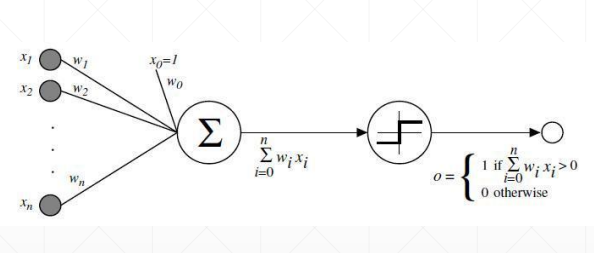
为了解决激活函数不可导的情况,提出了sigmoid/logistic:光滑可导的函数,且把无穷的值域压缩到[0, 1]的范围内

但是会出现梯度离散的情况,参数无法得到更新,因为越往后,导数值与接近于0
sigmoid函数求导之后如下:
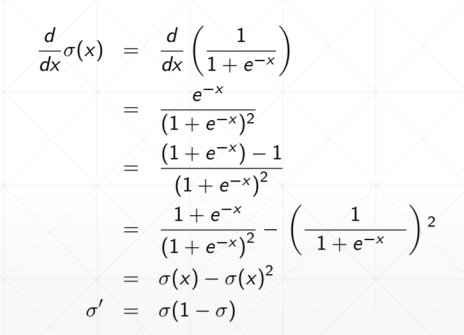
Tanh在RNN里面用得比较多

求导:

Relu使用最多的激活函数
计算导数的时候非常简单,导数为1。不会放大也不会缩小,很大程度上减少了梯度爆炸和梯度离散发生的可能性

递归算法
1.定义递归头
2.递归体
def fact(n):
if n==1:
return n
else:
return n*fact(n-1)
print(fact(5))
import shutil
shutil.make_archive('电影/gg','zip','movie/港台')
import zipfile
z1=zipfile.ZipFile('d:/a.zip','w')
z1.write('1.txt')
z1.write('1_copy.txt')
z.clost()
z2=zipfile.ZipFile('d:/a.zip','r')
z2.extractall('电影')
import shutil
shutil.copyfile('1.txt','1_copy.txt')
shutil.copytree('movie/港台','电影')
import os
path=os.getcwd()
list_files=os.walk(path)
for dirpath,dirnames,filenames in list_files:
for dir in dir names:
print(dir)
import csv
with open('dd.csv','r') as f:
a_csv=csv.reader(f)
print(list(a_csv))
with open('ee.csv','w')as f:
b_csv=csv.writer(f)
b_csv.writerow(['ID','name','age'])
常见函数的梯度

满足上述条件的函数叫做凸函数,不管从哪个方向都能找到全局最优解
容易出现的问题:
(1)有可能会遇到局部最优解
(2)saddle point出现鞍点,在一个自变量上的偏微分取得极大值,在另一个自变量上取极小值
优化梯度下降法来找到全局最优解的因素:
(1)初始状态;
(2)学习率;
(3)momentum——如何逃离局部最小值
什么叫梯度
导数——反映的是随着x的变化,y的变化趋势
偏微分——指定了自变量的方向上,因变量在某个自变量方向上的变化趋势
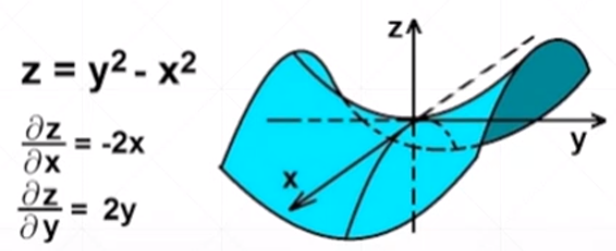
梯度——把所有的偏微分看做向量
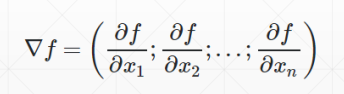
1、行注释:# 这是一行可以编辑中文的备注
2、断注释:三个英文状态下的引号,两行之间可以编辑中文的备注
"""
。。。
。。。
。。。
。。。
"""
1、保存:ctrl+s 随时保存,养成习惯
2、tab键:默认四个空格
3、注释:# 养成习惯,方便自己,方便他人
4、行连接符(代码太长需要分行时用):\
仅仅是分行用的,代码内容没有断
字符串的格式化
format()
填充与对齐
数字格式化
小数f 整数d
常用的查找方法
len
a.startswith('wo')是以wo开头的吗
a.endswith('wo')是以wo结尾的吗
a.find('wo')第一次出现wo的位置
a.rfind('wo')最后一次出现wo的位置
a.count('wo')wo出现了几次
a.isalnum()所有字符全是字母或数字 返回布尔值
去除首尾信息
strip()
大小写转换
a.capitalize()产生新的字符串,首字母大写
a.title()产生新的字符串,每个单词都首字母大写
a.upper()产生新的字符串,所有字符全转成大写
a.lower()产生新的字符串,所有字符全转成小写
a.swapcase()产生新的字符串,所有字母大小写转换
格式排版
center()、ljust()、rjust()
字符串驻留机制
字符串比较
==
!=
is
成员操作符
in
not in
split()分割 join()合并
a.split()把空格作为分隔符
a.split('be')把be最为分隔符
join()
a=['sxt','sxt100','sxt200']列表
'*'.join(a)
'sxt*sxt100*sxt200'
涉及到性能时一般用join(不生成新的对象)
append加元素
字符串切片slice操作
截取字符串
[:]提取整个字符串
[start:]从start-1开始直到最后
[:end]从头又开始直到end-1
包含开头不包含结尾
[start:end:step]
其他操作:
step=-1,从后往前反向提取
str()实现数字转型字符串
使用[]提取字符
replace实现字符串的替换
a=a.replace('c','gao')把c变成gao
转义字符
\续行符
\\反斜杠
\'单引号
\"双引号
\b退格
\n换行
\t横向制表符
\r回车
字符串的拼接
+
b=‘sxt''gaoqi’
形成新的对象
从控制台读取字符串
nyname=input‘请输入你的名字:’
请输入你的名字:
python的字符串是不可变的
字符串的编码:Unicode
ord()字符转换为数字
chr()数字转换为字符
多行 三个单引号
空格
len()查字符串chang'du