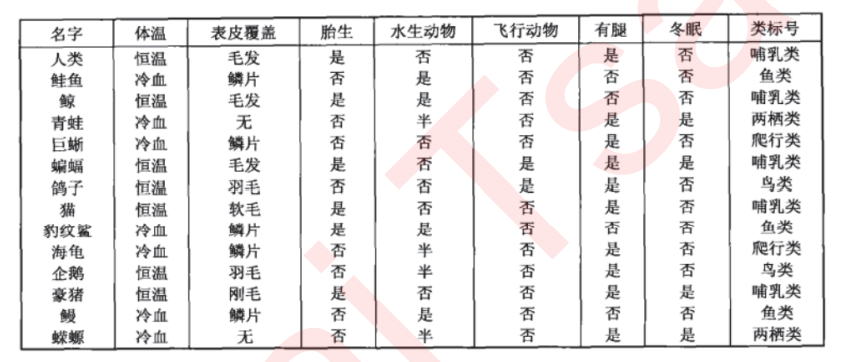
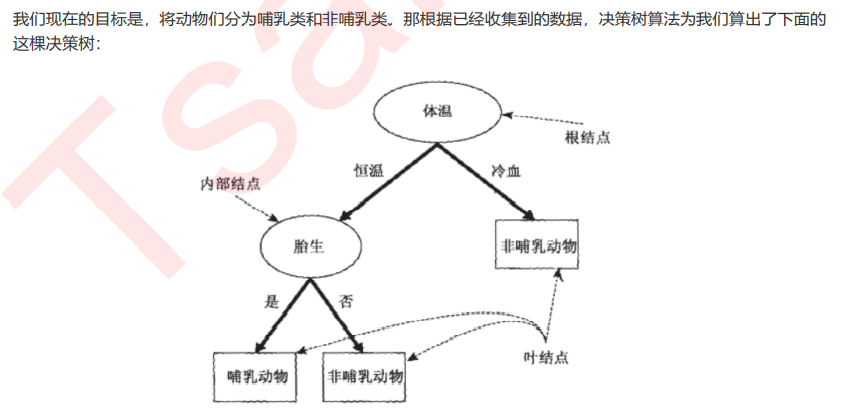
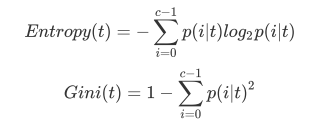max_features & min_impurity_decrease
一般max_depth使用,用作树的”精修“
·max_features
限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃。和max_depth异曲同工,max_features是用来限制高维度数据的过拟合的剪枝参数,但其方法比较暴力,是直接限制可以使用的特征数量 而强行使决策树停下的参数,在不知道决策树中的各个特征的重要性的情况下,强行设定这个参数可能会导致模型 学习不足。如果希望通过降维的方式防止过拟合,建议使用PCA,ICA或者特征选择模块中的降维算法。
·min_impurity_decrease限制信息增益的大小,(信息增益是用父节点的信息熵-子节点的信息熵)信息增益小于设定数值的分枝不会发生。这是在0.19版本中更新的功能,在0.19版本之前时使用min_impurity_split。
剪枝参数可以通过学习曲线来找到最优参数
无论如何,剪枝参数的默认值会让树无尽地生长,这些树在某些数据集上可能非常巨大,对内存的消耗也非常巨 大。所以如果你手中的数据集非常巨大,你已经预测到无论如何你都是要剪枝的,那提前设定这些参数来控制树的 复杂性和大小会比较好。