这课程讲的就和拿着稿子照本宣科一样


3681-邹同学-Python学科-数据分析
3681-邹同学-Python学科-数据分析
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
如果要计算某个维度下的用户数,不要直接count()
#apply返回每个测试样本所在叶子节点的索引
clf.apply(xtext)
#predict返回每个测试样本的分类、回归结果
clf.predict(xtest)
#决策树 # from sklearn import tree#导入需要的模块 # clf=tree.DecisionTreeClassifier()#实例化 # clf=clf.fit(x_train,y_train)#用训练集数据训练模型 # result=clf.score(x_test,y_test)#导入测试集,从接口中调用需要的信息进行打分
citerion:不纯度,不纯的越低,训练集拟合越好
机器学习
全列插入:
insert into 表名 values( ‘数据1’, ‘数据2’, ‘数据3’……)
部分插入:
insert into 表名 (字段1,字段2 ……)values( ‘数据1’, ‘数据2’, ……),( ‘数据1’, ‘数据2’, ……)
电信日志分析:
描述:
- 以什么为基础计算:电信用户上网所产生的数据
- 数据主要来源:访问日志和安全日志
- 目的:异常IP的检测、关键词的过滤、违规违法用户的处理
- 方法:通过Hadoop大数据平台完成日志的入库、处理、查询、实时分析、上报等功能实现
- 数据量:1T-20T左右
- 集群数量:10台-100台
项目架构分析:
- 数据采集层(千兆网卡以上):
- 用户访问日志数据:数据格式;
数据采集的方式:ftp
数据上传时间
小文件合并:shell(JNotify) - 用户安全日志数据:
触发上传要求
数据采集方式:socket--C++完成数据采集,缓存到内存磁盘
数据格式:加密码加密形式
- 用户访问日志数据:数据格式;
- 数据储存层:HDFS分布式文件系统
- 数据分析层:
- MapReduce:数据清洗
- HIVE
- hbase:固定条件查询
- impala:实时性较高的要求
- SPARK:解决单一数据源多指标在内存中的计算
- OOZIE:任务调度
- mysol:HIVE和oozie元数据存放
- 机器学习层:在大数据的存储和计算基础上,通过构建机器学习构建机器学习模型,对事实作出预判
项目优化:HDFS+SPARK一站式分析平台
机器学习模型=数据+算法
统计学习=模型+策略+算法
模型:规律 y=ax+b
损失函数=误差函数=目标函数
算法:如何高效找到最优参数
决策函数 或 条件概率分布
半监督学习:一部分有类别标签,一部分没有类别标签
主动学习:依赖于人工打标签
聚类的假设:将有标记的样本和无标记的样本混合在一起,通过特征间的相似性,将样本分成若干个组或若干个簇;使得组内的相似性较大,组间的相异性较大,将样本点都进行分组,;此时分组点的样本点即包含了有类别标签的也包含了没有类别标签的,根据有类别标签的样本,按照少数服从多数的原则对没有加标记的样本添加标记。至此,所有未标记的数据都可以加以分配标记。
半监督学习转化为监督学习。
强化学习:解决连续决策问题。
为其可以是一个强化学习问题,需要学习在各种局势下如何走出最好的招法
迁移学习:小数据集:两个相关领域(解决数据适应性问题)
个性化
深度+强化+迁移
监督学习:分类问题、回归
分类:决策树、KNN、贝叶斯、SVM、LR
回归:线性回归、多元回归LASSO回归、RIDGE回归、Elastic回归
无监督学习(非监督学习):
1、聚类(Kmeans)在没有类别标签的情况下,根据特征相似性或相异性进行分类;
2、特征降维(PCA. LDA):根据算法将高维特征降低到了低维
机器学习个概念的理解:
数据集:
定义数据集的名称
行:样本或实例
列:特征或属性,最后一列(类别标签列,结果列)
特征、属性空间:有特征维数所张成的空间
>>特征向量:组成特征火属性空间中的样本点
>>特征值或属性值:组成特征向量中的值
基于规则的学习:它是一种硬编码方式
X 自变量 定义域 特征
Y因变量 值域 结果
fx----f(对应关系)----->y(函数、映射、模型)
基于模型的学习:y=kx+b 寻求k和b的最佳值
通过数据构建机器学习模型,通过模型进行预测;
机器学习学的是模型中的k和
GPU图形图像处理器(处理速度是CPU的10倍以上)
机器学习==CPU+GPU+数据+算法
机器学习:致力于研究如何通过计算(CPU和GPU计算)的手段,利用经验来改善(计算机)系统自身的性能
是人工智能的核心
从数据中产生或发现规律
数据+机器学习算法=机器学习模型
有了学习算法我们就可以把经验数据提供给他,他就能基于这些数据产生模型
如何判断问题是否为机器学习问题?
预测性的
数据:观测值、感知值,测量值
信息:可信的数据
数据分析:对数据到信息的整理、筛选和加工的过程。
数据挖掘:对信息进行价值化的分析
用机器学习的方法进行数据挖掘。机器学习是一种方法,数据挖掘是一件事情;
人工智能包括机器学习,机器学习包括深度学习
机器学习是人工智能落地的一个工具。
机器学习是人工智能的一个分支
深度学习是机器学习的一种方法,为了解决机器学习领域中图像识别等问题而提出的
数据分层:
数据采集层、数据存储层、数据分析层、数据展示
数据采集层
用户访问日志数据,数据格式:地区吗|用户ip|目的ip|流量……;数据采集方式:采用fatp方式长传服务器;上传时间:每小时上传上一小时的数据;小文件合并:通过shell完成文件合并;监控文件:JNotify
用户的安全日志数据:
当用户触犯电信部门制定的只读、违反国家法律法规
数据采集方式用:Socket---C++完成数据采集,先缓存到内存再到磁盘;
数据格式:加密码:加密形式 abc:79217979web
网卡配置:千兆或万超网卡配置
数据存储层:HDFS分布式文件系统
数据分析层:用Mapreduce、Impala\Spark
1、完成数据清洗(缺失字段处理、异常值处理等
2、使用MR和Redis进行交互完成地区码201和地区名字的转换
3、使用MR处理好的数据进一步加载到Hive中做处理
4、试用MR将数据入库到HBASE完成固定条件查询
5、给到Spark中实时查询
机器学习层:
机器学习位于大数据上层,完成的是在大数据的数据存储和数据计算之上,通过数据结合机器学习算法建构机器学习模型,利用模型对现实时间做出预测
数据展示:Oracle+SSM
大数据的4V特征:
- 数据量大
- 数据种类多:
结构化数据(mysql);
非结构化数据(音频视频:HDFS/MR/HIVE);
半结构化数据(XML/HTML: HDFS/MR/HIVE); - 速度快:
增长速度快
处理速度快(实时、离线) - 价值密度低
价值密度=有价值的数据/ALL
价值高
机器学习算法解决问题
支持向量机的分类方法,是在这组分布中找出一个超平面作为决策边界,使模型在数据上的 分类误差尽量接近于小,尤其是在未知数据集上的分类误差(泛化误差)尽量小。

决策边界一侧的所有点在分类为属于一个类,而另一侧的所有点分类属于另一个类。如果我们能够找出决策边界, 分类问题就可以变成探讨每个样本对于决策边界而言的相对位置。比如上面的数据分布,我们很容易就可以在方块 和圆的中间画出一条线,并让所有落在直线左边的样本被分类为方块,在直线右边的样本被分类为圆。如果把数据 当作我们的训练集,只要直线的一边只有一种类型的数据,就没有分类错误,我们的训练误差就会为0。
但是,对于一个数据集来说,让训练误差为0的决策边界可以有无数条。
支持向量机(SVM,也称为支持向量网络),是机器学习中获得关注最多的算法没有之一。它源于统计学习理论, 是我们除了集成算法之外,接触的第一个强学习器。它有多强呢?

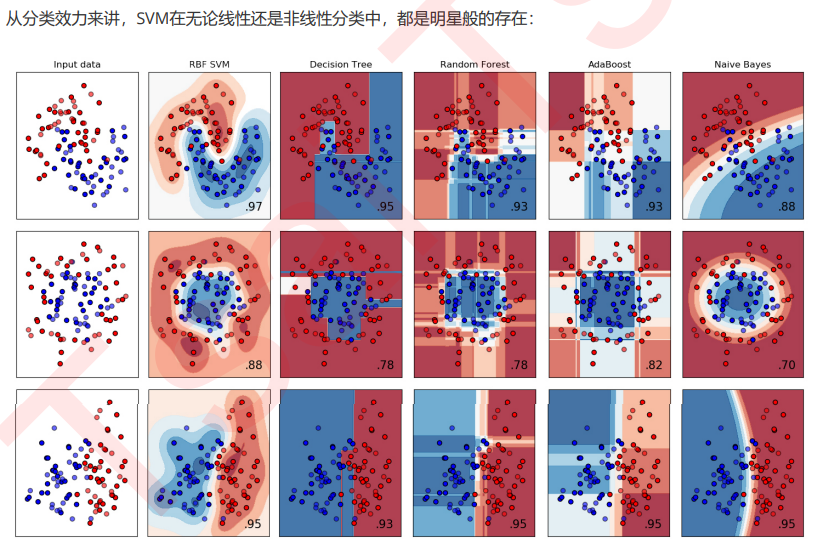
从实际应用来看,SVM在各种实际问题中都表现非常优秀。它在手写识别数字和人脸识别中应用广泛,在文本和超 文本的分类中举足轻重,因为SVM可以大量减少标准归纳(standard inductive)和转换设置(transductive settings)中对标记训练实例的需求。同时,SVM也被用来执行图像的分类,并用于图像分割系统。。除此之外,生物学和许多其他科学都是SVM的青睐者,SVM现在已经广泛被用于蛋白质分类,现 在化合物分类的业界平均水平可以达到90%以上的准确率。在生物科学的尖端研究中,人们还使用支持向量机来识 别用于模型预测的各种特征,以找出各种基因表现结果的影响因素。
从学术的角度来看,SVM是最接近深度学习的机器学习算法。线性SVM可以看成是神经网络的单个神经元(虽然损 失函数与神经网络不同),非线性的SVM则与两层的神经网络相当,非线性的SVM中如果添加多个核函数,则可以 模仿多层的神经网络。
高效嵌入法embedded