三、非线性SVM与核函数
1、核变换:把数据投影到高维空间中,寻找能将数据完美分割的超平面。
2、核函数使得 高维空间的任意两个向量的点积一定可以用低维空间这两个向量的某种计算表示
3、重要参数kernel:
1)"linear":线性核函数,线性
2) "poly": 多项式核,偏线性
3) "sigmoid": 双曲正切核,非线性
4) "rbf": 高斯径向基,偏非线性


三、非线性SVM与核函数
1、核变换:把数据投影到高维空间中,寻找能将数据完美分割的超平面。
2、核函数使得 高维空间的任意两个向量的点积一定可以用低维空间这两个向量的某种计算表示
3、重要参数kernel:
1)"linear":线性核函数,线性
2) "poly": 多项式核,偏线性
3) "sigmoid": 双曲正切核,非线性
4) "rbf": 高斯径向基,偏非线性
intercept_
线性回归
一、概述
回归的预测结果是连续型变量
二、多元(多个特征)线性回归LinearRegression
1、linear_model.LinearRegression使用的损失函数:SSE(误差平方和)或RSS(残差平方和)
2、最小二乘法:
1)通过最小化真实值与预测值之间的RSS来求解参数
2)最小二乘法求解线性回归是一种无偏估计的方法,要求标签必须服从正态分布
三、回归类的模型评估指标
四、多重共线性:岭回归和Lasso
五、非线性问题:多项式回归
逆矩阵存在的充分必要条件是特征矩阵不存在多重共线性
线性回归
一、概述
回归的预测结果是连续型变量
二、多元(多个特征)线性回归LinearRegression
1、linear_model.LinearRegression使用的损失函数:SSE(误差平方和)或RSS(残差平方和)
三、回归类的模型评估指标
四、多重共线性:岭回归和Lasso
五、非线性问题:多项式回归
线性回归
一、概述
二、多元线性回归LinearRegression
三、回归类的模型评估指标
四、多重共线性:岭回归和Lasso
五、非线性问题:多项式回归
线性回归
一、概述
二、多元线性回归LinearRegression
三、回归类的模型评估指标
四、多重共线性:岭回归和Lasso
五、非线性问题:多项式回归
ROC曲线
衡量在尽量捕捉少数类时,误伤多数类的情况如何变化(recall与
混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
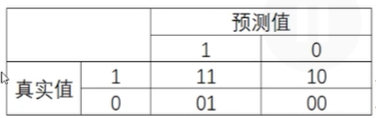
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
3)sklearn中没有特异度和假正率,需要自己计算
6个指标
1、准确率Accuracy

2、捕捉少数类
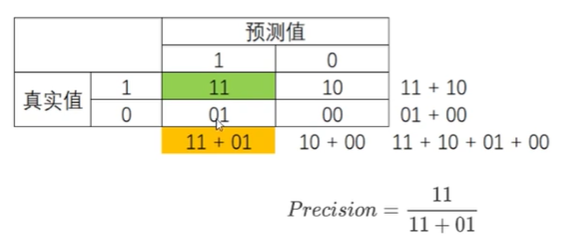
1)精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂时,追求高精确度
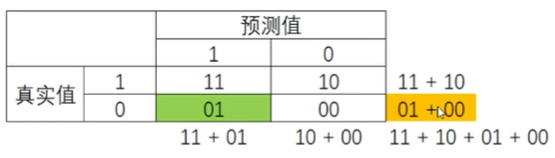
2)召回率Recall(敏感度、真正率、查全率)
越高,捕捉出了越多的少数类
不计一切代价找出少数类,追求高召回率
召回率和精确度此消彼长,代表捕捉少数类的需求和不误伤多数类需求的平衡

3)F1 measure:范围[0,1],越接近1越好,代表精确度和召回率越高

3、判错多数类
1)特异度specificity(真负率)
衡量一个模型把多数类判断正确的能力

2)假正率false positive rate=1-特异度
衡量一个模型把多数类判断错误的能力
SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
6个指标
1、准确率Accuracy
2、捕捉少数类
1)精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂时,追求高精确度
2)召回率Recall(敏感度、真正率、查全率)
越高,捕捉出了越多的少数类
不计一切代价找出少数类,追求高召回率
召回率和精确度此消彼长,代表捕捉少数类的需求和不误伤多数类需求的平衡
3)F1 measure:范围[0,1],越接近1越好,代表精确度和召回率越高
3、判错多数类
1)特异度specificity(真负率)
衡量一个模型把多数类判断正确的能力
2)假正率false positive rate=1-特异度
衡量一个模型把多数类判断错误的能力
SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
6个指标
1、准确率Accuracy
2、
1)精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂时,追求高精确度
2)召回率Recall(敏感度、真正率、查全率)
越高,捕捉出了越多的少数类
不计一切代价找出少数类,追求高召回率
召回率和精确度此消彼长,代表捕捉少数类的需求和不误伤多数类需求的平衡
3)F1 measure:范围[0,1],越接近1越好,代表精确度和召回率越高
SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
6个指标
1、准确率Accuracy
2、精确度Precision(查准率):
越低,误伤了过多的多数类,衡量 多数类判错付出的成本
将多数类判错成本高昂
SVC模型评估指标
1、混淆矩阵
二分类中极为有效,少数类为正例,多数类为负例
1)真实值在预测值之前,两数字相同则预测正确
2)所有指标范围在[0,1],11、00为分子的指标越接近1越好,01、10分子的指标越接近0越好
3)6个指标
准确率Accuracy
SVC模型评估指标
核变换:把数据投影到
1、函数contour([x,y],z,[levels])用来绘制等高线
x,y:平面所有点横纵坐标,必须是二维,选填
z表示x,y对应坐标点的高度,必填
levels:默认显示所有等高线,可不填,填写整数n显示n个数据区间,填写数组或列表(递增顺序)显示对应高度等高线
2、绘制等高线的步骤:
制作网格
SVM支持向量机
一、概述
SVM功能强大,可以进行有监督学习、无监督学习、半监督学习
SVM如何工作?在分布中找到一个超平面(比所在空间小一维,是一个空间的子空间)作为决策边界,使模型的分类误差尽可能小。
支持向量机是一个最优化问题,目的是找出边际最大的决策边界(通过损失函数)。边际(d)是超平面往两边移动,直到碰到最近的样本停下得来的。拥有更大边际的决策边界,在分类中泛化误差更小,边际很小会过拟合。因此,支持向量机又叫做最大边际分类器。
二、sklearn.svm.SVC
1、线性SVM的损失函数
SVM支持向量机
一、概述
SVM功能强大,可以进行有监督学习、无监督学习、半监督学习
SVM如何工作?在分布中找到一个超平面(比所在空间小一维,是一个空间的子空间)作为决策边界,使模型的分类误差尽可能小。
支持向量机是一个最优化问题,目的是找出边际最大的决策边界(通过损失函数)。边际(d)是超平面往两边移动,直到碰到最近的样本停下得来的。拥有更大边际的决策边界,在分类中泛化误差更小,边际很小会过拟合。因此,支持向量机又叫做最大边际分类器。
二、
SVM支持向量机
一、概述
可以进行有监督学习、无监督学习、半监督学习
二、
矢量量化本质是一种降维应用,特征选择降维:选取贡献大的特征;PCA降维:聚合信息;矢量量化降维:同等样本量上(不改变样本和特征数目)压缩信息大小