特征工程
数据挖掘的五大流程:
1. 获取数据
2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字,有的含时间序列,有的连续,有的间断。 也可能,数据的质量不行,有噪声,有异常,有缺失,数据出错,量纲不一,有重复,数据是偏态,数据量太 大或太小 数据预处理的目的:让数据适应模型,匹配模型的需求
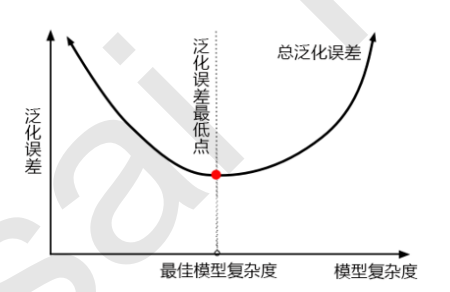
3. 特征工程: 特征工程是将原始数据转换为更能代表预测模型的潜在问题的特征的过程,可以通过挑选最相关的特征,提取 特征以及创造特征来实现。其中创造特征又经常以降维算法的方式实现。 可能面对的问题有:特征之间有相关性,特征和标签无关,特征太多或太小,或者干脆就无法表现出应有的数 据现象或无法展示数据的真实面貌 特征工程的目的:1) 降低计算成本,2) 提升模型上限
4. 建模,测试模型并预测出结果
5. 上线,验证模型效果
1.2 sklearn中的数据预处理和特征工程
模块preprocessing:几乎包含数据预处理的所有内容
模块Impute:填补缺失值专用
模块feature_selection:包含特征选择的各种方法的实践
模块decomposition:包含降维算法