互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既 可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和 feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过 互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。


3415-陈漫漫-人工智能学科-数据挖掘方向-就业:是
3415-陈漫漫-人工智能学科-数据挖掘方向-就业:是
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
集合:无序可变,集合底层是字典实现,集合的所有元素都是字典中的”键对象“,因此是不能重复且唯一的。
集合创建和删除
1.{}创建
2.set()创建
3.remove()、clear()
集合相关操作
字典核心底层原理(重要)
列表通过索引值寻找,字典通过键寻找。
字典对象的核心是散列表。散列表是一个稀疏数组,数组的每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。
(1)将一个键值对放进字典的底层过程
序列解包
序列解包可以用于元组、列表、字典。序列解包可以方便对多个变量进行赋值。
字典元素添加、修改、删除
1.给字典新增键值对,如果键已经存在则被覆盖,若键不存在则增加。
2.使用update()将新字典中所有键值对全部添加到旧字典上,如果键重复则进行覆盖。
3.字典中元素的删除,可以使用del()方法,或者clear()删除所有键值对;pop()删除指定键值对,并返回对应的值对象。
4.popitem():随机删除和返回键值对,字典是无序可变序列,因此没有元素的排序顺序等;popitem弹出随机的项。
字典元素的访问
(1)通过【键】获得“值”
(2)通过get()方法获得值(推荐使用)
字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:"键对象"和“值对象”。可以通过“键对象”实现快速获取,删除,更新对应的“值对象”。“键”不可重复。
字典的创建
(1)通过{},dict()函数创建字典。
(2)zip()
(3)通过fromkeys创建值为空的字典
生成器推导式创建元组
生成器推导式生成的不是列表也不是元组,而是一个生成器对象。
元组的元素访问和计数
元组排序
zip():将多个列表对应位置的元素组合成为元组,并返回这个zip对象。
元组tuple
列表属于可变序列,可以任意修改列表中的序列。元组属于不可变序列,不能修改元组中的元素。所以,元组中没有增加元素,修改元素,删除元素相关的方法。
元组的创建
(1)通过()创建,小括号可以省略。
(2)通过tuple()创建元组。将字符串,range()序列,列表转化为元组。
元组的删除
多维列表
二维列表
列表的排序
(1)修改源列表,不建立新列表
a.sort()
(2)建新列表的排序
a=sorted(a)
(3)reversed()返回迭代器
切片操作
[起始偏移量:终止偏移量:步长]
列表的遍历
列表元素访问和计数
(1)通过索引直接访问元素
(2)获得指定元素在列表中首次出现的索引
index(value,[start,end])
(3)count()获得指定元素在列表中出现的次数
(4)len()列表长度
列表元素的删除
(1)del删除
a=[100,200,888,300,400] del(a[2]) print(a)
本质上是数组元素依次拷贝
(2)pop()方法
a=[10,20,30,40,50] b=a.pop() print(b) #50a中元素从末尾依次弹出 c=a.pop(1) print(c) #20弹出指定元素 print(a) #[10, 30, 40]a中元素被弹出后
(3)remove():删除首次出现的指定元素。
a=[10,20,30,40,50] a.remove(20) print(a) #[10, 30, 40, 50]
处理连续型特征:二值化和分箱
根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量。大于阈值的值映射为1,而小于或等于阈 值的值映射为0。默认阈值为0时,特征中所有的正值都映射到1。
二值化是对文本计数数据的常见操作,分析人员 可以决定仅考虑某种现象的存在与否。它还可以用作考虑布尔随机变量的估计器的预处理步骤(例如,使用贝叶斯 设置中的伯努利分布建模)。
分箱

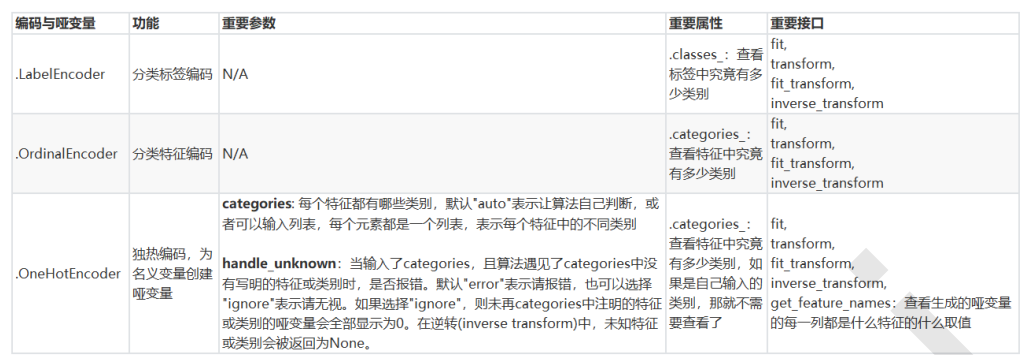
处理分类型特征:编码与哑变量
LabelEncoder:标签专用,能够将分类转换为分类数值
OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
OneHotEncoder:独热编码,创建哑变量
类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量向算法传达最准确的信息:
缺失值
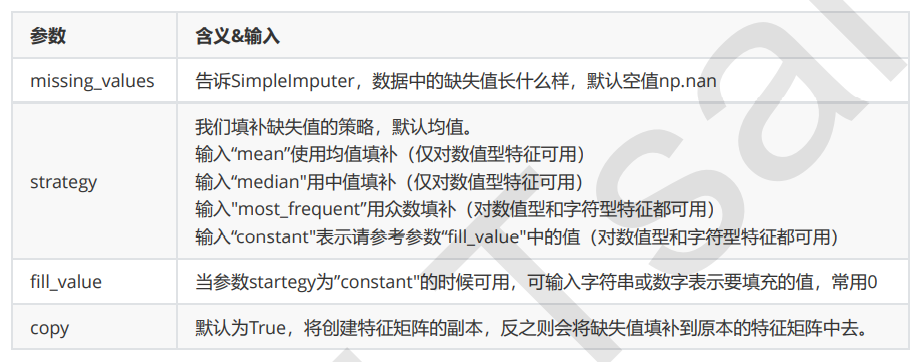
impute.SimpleImputer
StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分 布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候 保持缺失NaN的状态显示。
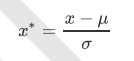
并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数 组,一维数组导入会报错。通常来说,我们输入的X会是我们的特征矩阵,现实案例中特征矩阵不太可能是一维所以不会存在这个问题。
StandardScaler和MinMaxScaler选哪个?
大多数机器学习算法中,会选StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。

数据无量纲化
在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布 的需求,这种需求统称为将数据“无量纲化”。
数据的无量纲化可以是线性的,也可以是非线性的。线性的无量纲化包括中心化(Zero-centered或者Meansubtraction)处理和缩放处理(Scale)。中心化的本质是让所有记录减去一个固定值,即让数据样本数据平移到 某个位置。
preprocessing.MinMaxScaler
当数据(x)按照最小值中心化后,再按极差(最大值 - 最小值)缩放,数据移动了最小值个单位,并且会被收敛到 [0,1]之间,而这个过程,就叫做数据归一化(Normalization,又称Min-Max Scaling)。注意,Normalization是归 一化,不是正则化,真正的正则化是regularization,不是数据预处理的一种手段。归一化之后的数据服从正态分 布,公式如下:
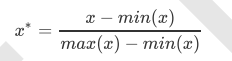
在sklearn当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有一个重要参数, feature_range,控制我们希望把数据压缩到的范围,默认是[0,1]。
axis = 0 按行计算,得到列的性质。
axis = 1 按列计算,得到行的性质。