Step 2:预处理


3208-段婷-人工智能学科-自然语言处理方向解锁式
3208-段婷-人工智能学科-自然语言处理方向解锁式
![]() 扫二维码继续学习 二维码时效为半小时
扫二维码继续学习 二维码时效为半小时
Step 1:创建自定义数据集
w = torch.rand(16, 3, 5, 5)
= (ker_num, input_channel, ker_size, ker_size)
Input_channels:
- 黑白:1
- 彩色:3
Stocastic: 随即筛选样本
val_set: for detecting overfitting
torch.nn.function
.matmul() 取后两维相乘
unsqueeze:
正:在之前插入
负:在之后插入
.index_select(0, [0, 2])
torch.tensor([2., 3.2])
torch.FloatTensor(2, 3)
Unintialized: 未初始化的tensor
增强学习一般用 DoubleTensor
几何概率:与构成事件的长、面积、体积 成比例;
几何概率特点:基本事件 的无限性(抽象)、等可能性;
古典概型特点:基本事件 的有限性(具象)、等可能性;
.开头是隐藏文件l
最大熵模型:
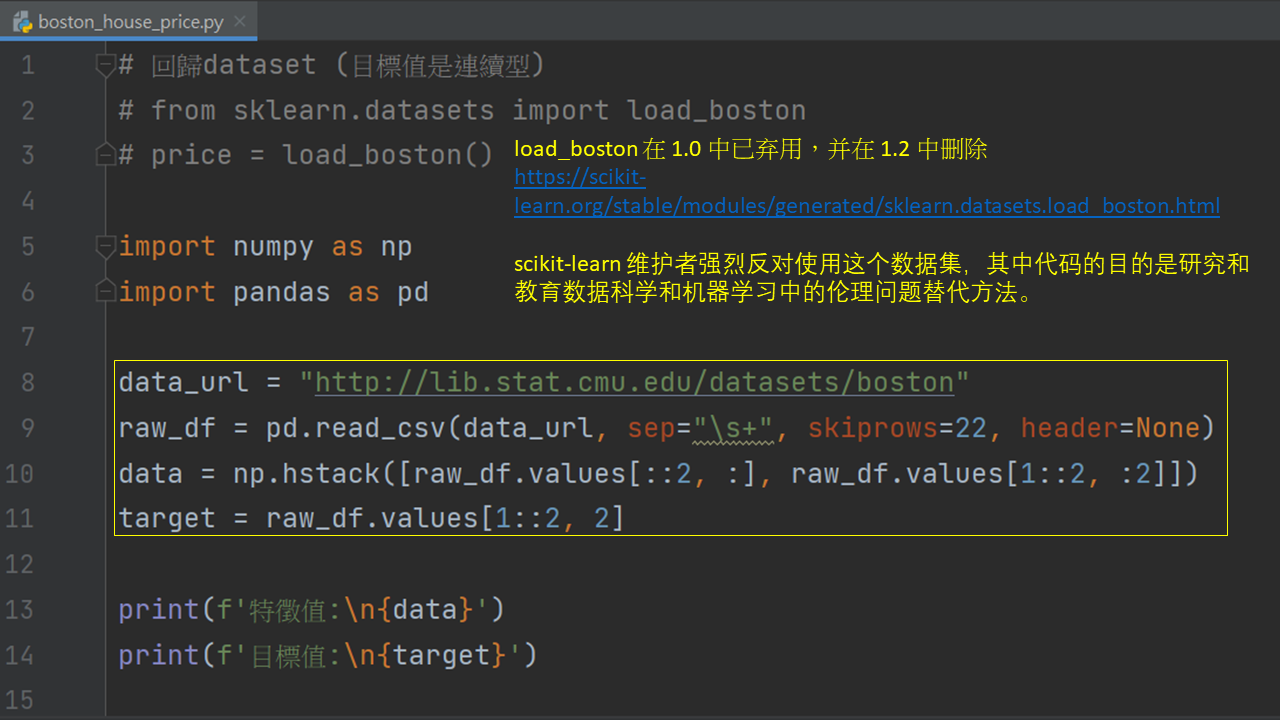
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)
機器學習推薦書:
1. 機器學習 (西瓜書)
2. Python數據分析與挖掘實戰
3. 機器學習系統設計
4. 面向機器智能TensorFlow實戰
5. TensorFlow技術解析與實戰