字典介绍
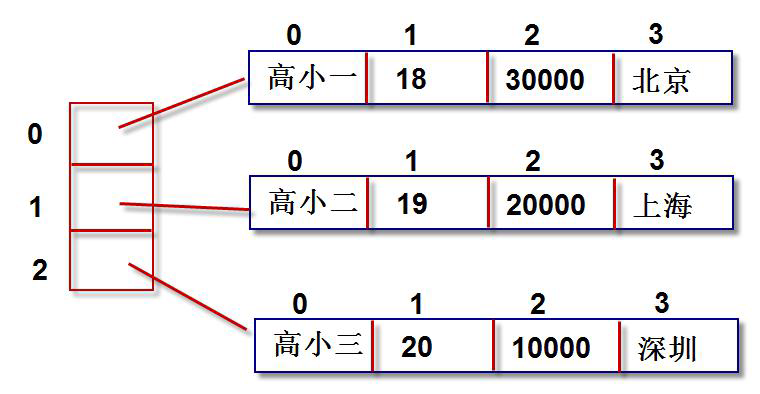
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”
可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。(列表中我们通过“下标数字”找到对应的对象。字典中通过“键对象”找到对应的“值对象”。)
“键”是任意的不可变数据(整数、浮点数、字符串、元组)并且“键”不可重复。
“值”可以是任意的数据,并且可重复(列表、字典、集合)
一个典型的字典的定义方式:
a ={'name':'gaoqi','age':18,'job':'programmer'
字典的创建
1. 我们可以通过{}、dict()来创建字典对象。
>>> a = {'name':'gaoqi','age':18,'job':'programmer'}
>>> b = dict(name='gaoqi',age=18,job='programmer')
>>> a = dict([("name","gaoqi"),("age",18)])
>>> c = {} #空的字典对象
>>> d = dict() #空的字典对象
2. 通过zip()创建字典对象
>>> k = ['name','age','job']
>>> v = ['gaoqi',18,'techer']
>>> d = dict(zip(k,v)) #k键;v值
>>> d
{'name': 'gaoqi', 'age': 18, 'job': 'techer'}
3. 通过fromkeys 创建值为空的字典
>>> a = dict.fromkeys(['name','age','job'])
>>> a
{'name': None, 'age': None, 'job': None}