float(3)=3.0
float("3.14")=3.14


float(3)=3.0
float("3.14")=3.14
id+type(类型)+value(值)=对象
eg: 3 id:1531372336 type:int value:3
a:1531372336 #把地址赋给a
变量必须先被初始化,不然不能运行。eg:ddd 是不能运行会报错的。
F1快捷键,找出python的API
\ ——用于换行,也叫行连接符。
数据预处理
深度学习需要的是标准的正方形图片
(1)image resize
(2)Data Argumentation
(3)Normalize
(4)to tensor
自定义数据集实战
test数据量太小的话,测试结果波动较大,所以我们为了保证测试的效果,会把测试集的数据多分配一些
1、load data ——比较重要的模型;
继承一个通用的母类
inherit from torch.utils.data.Dataset
要定一个两个函数
_len_:数据量
_getitiem_:能够得到指定的样本
2、build model——在我们已经定义好的模型上做一些修改;
3、train and test
4、transfer learning
情感分类实战
Google CoLab
(1)continuous 12 hours;
(2)free K80 for GPU;
(3)不需要爬墙
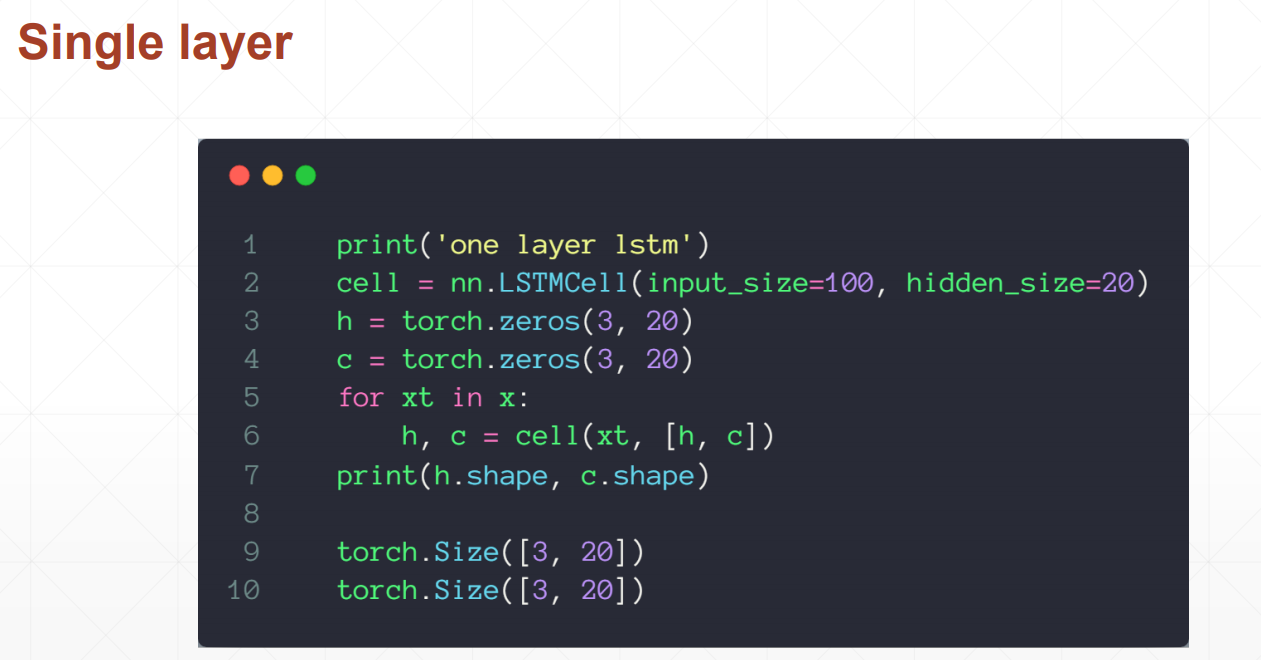
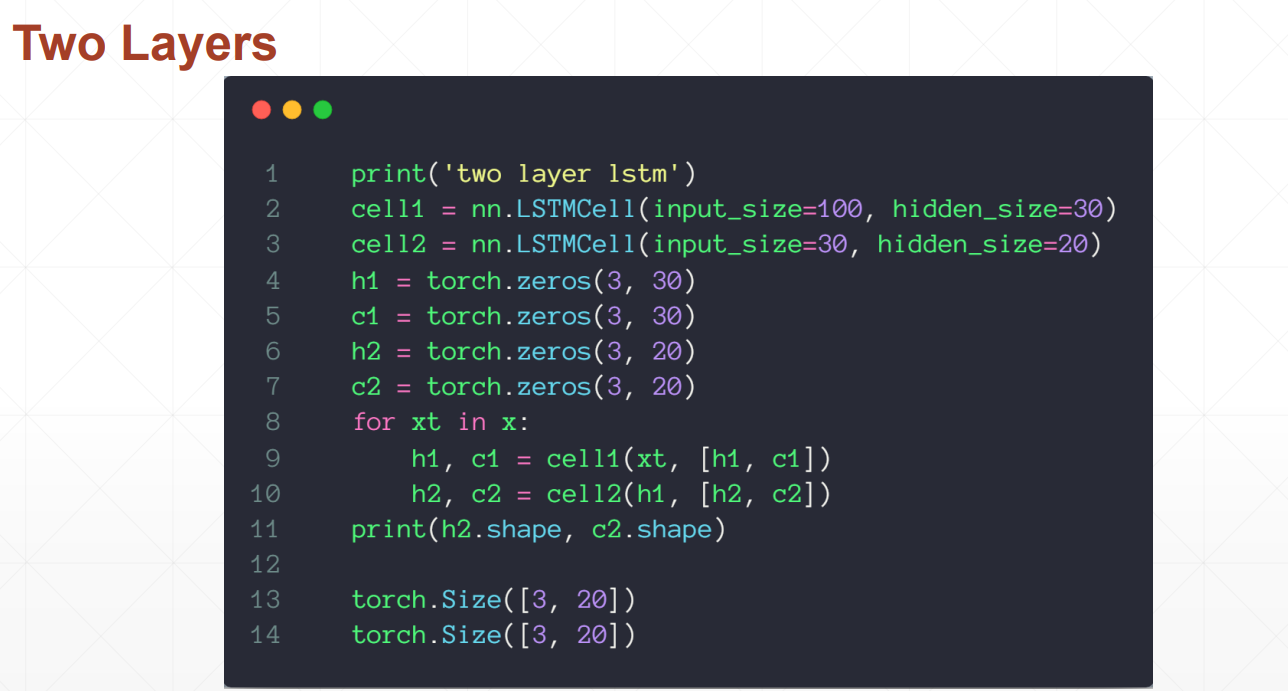
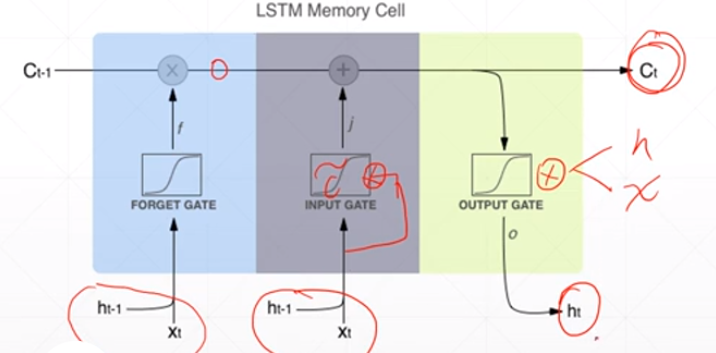
LSTM使用方法

LSTMcell更为灵活的使用方法,可以自定义喂数据的方式
2、输入门
it作为一个开度,将多少信息传入到下一个时间点,有算法决定这个开度;新信息同样也是由ht-1和当前点的xt共同决定的。it是对当前信息的过滤系数,当前信息与开度相乘之后就是经过过滤后输入下一个点的新信息。
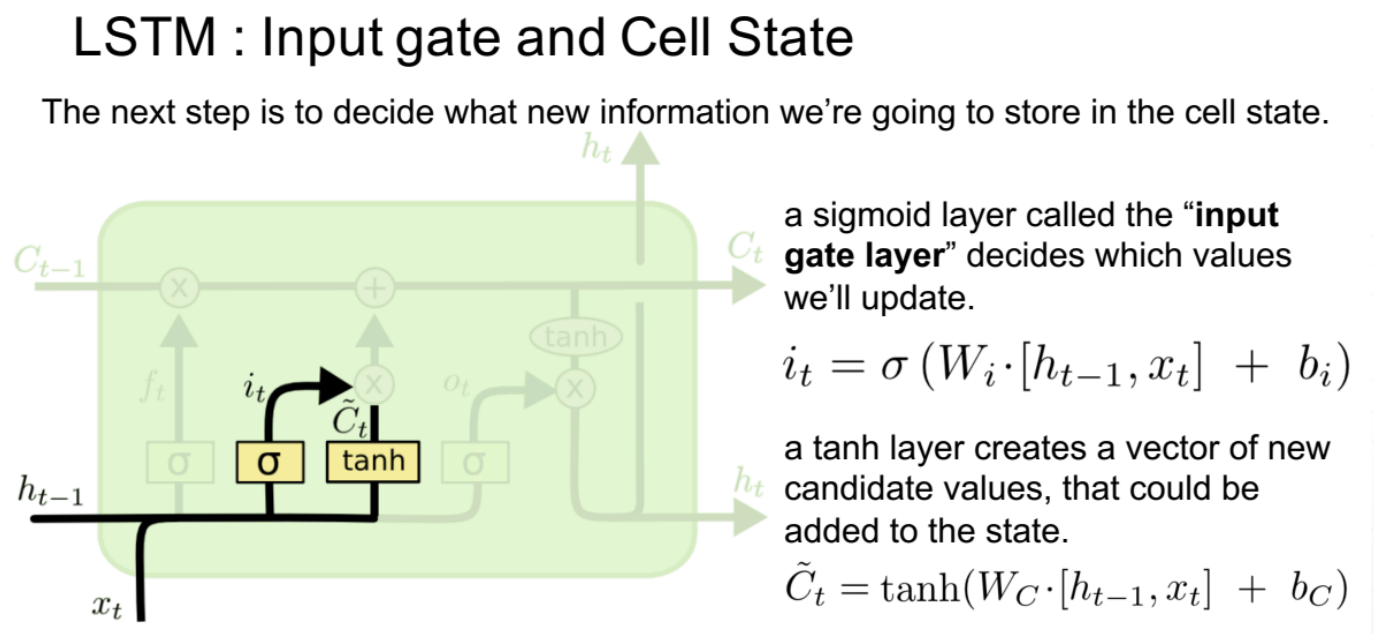
输入门的值

ct是memory,ht是隐藏层的输出
3、输出值
同样是由开度和ct共同决定的,ot作为开度也是由算法决定的
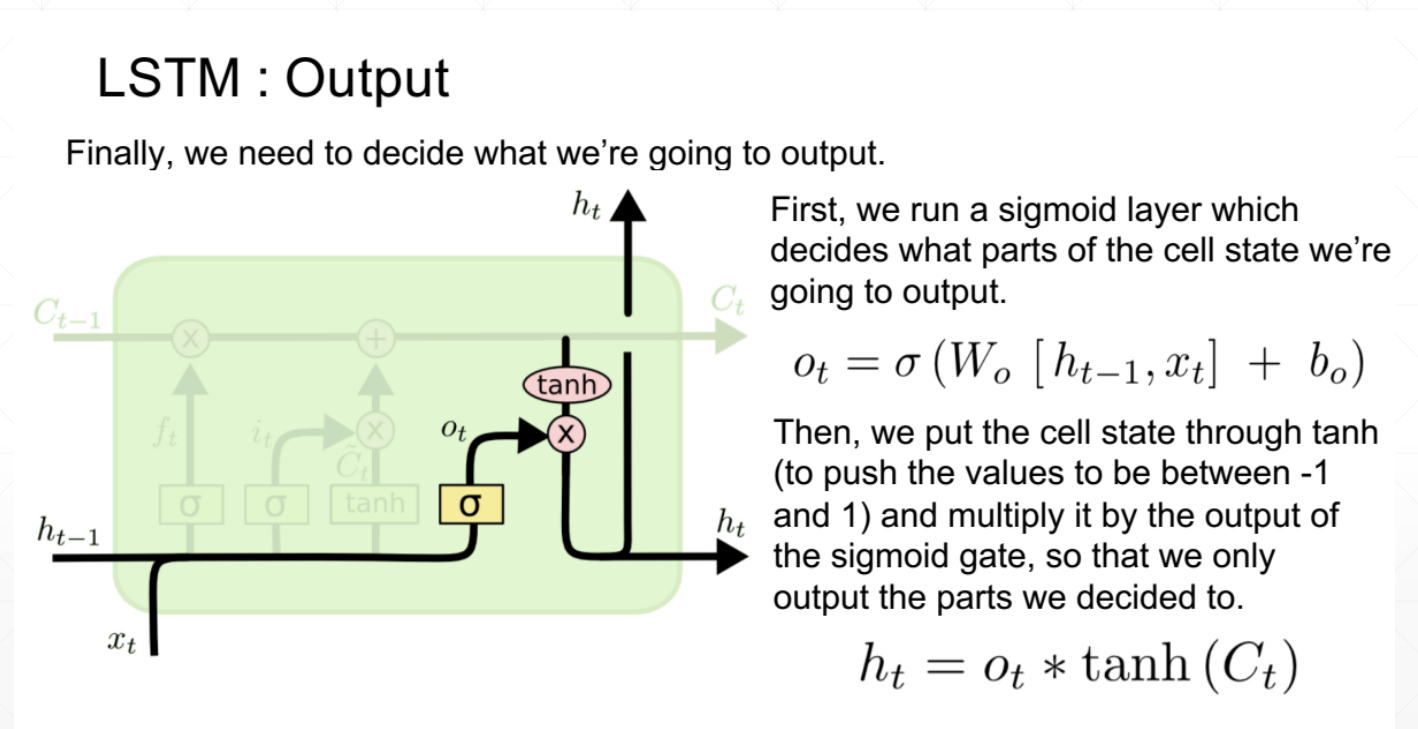
LSTM如何解决梯度离散的问题呢?
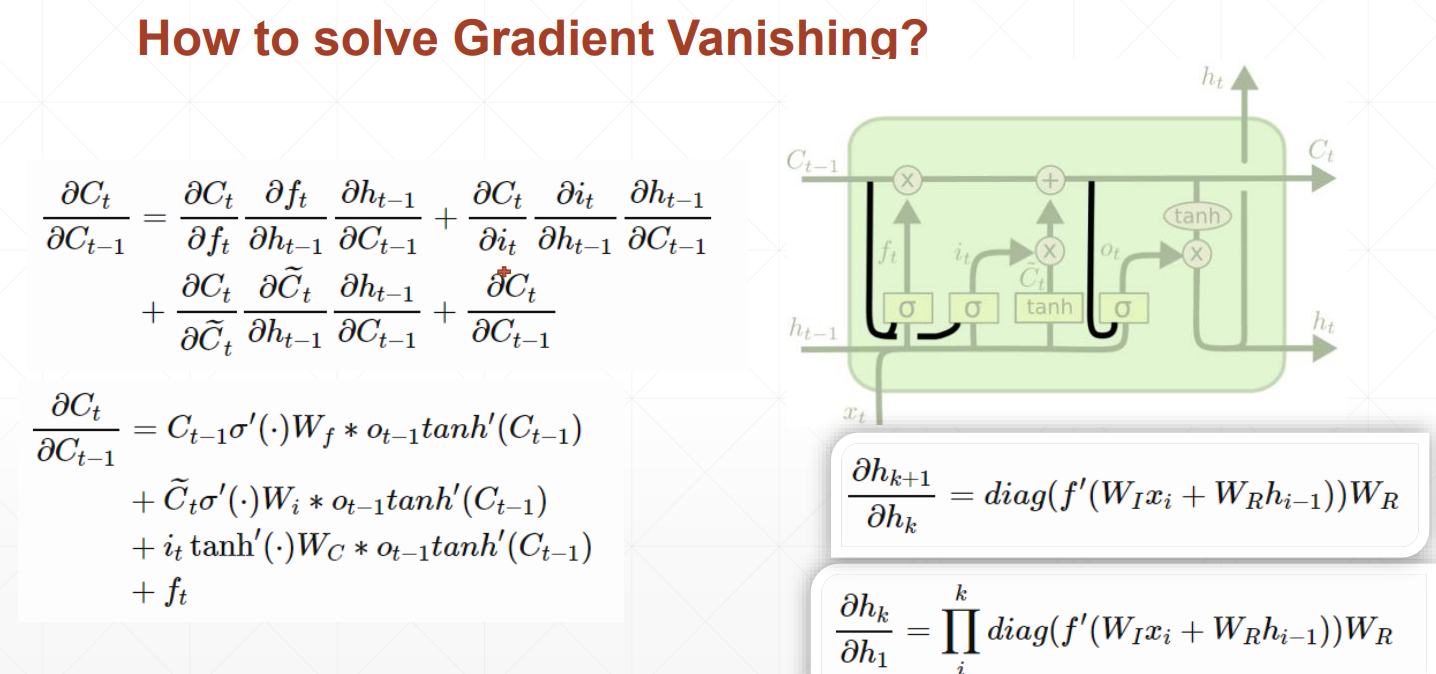
由于存在忘记门、输入门和输出门三个门
当前隐藏层对前一个隐藏层求导时,出现三个值相加的情况,不容易出现都是大或都是小的情况,数值相对可靠,所以效果相对来说更好一些。
LSTM将短期记忆变长,RNN只能记住比较短的时间序列,LSTM就是为了解决短期记忆的问题。
1、忘记门
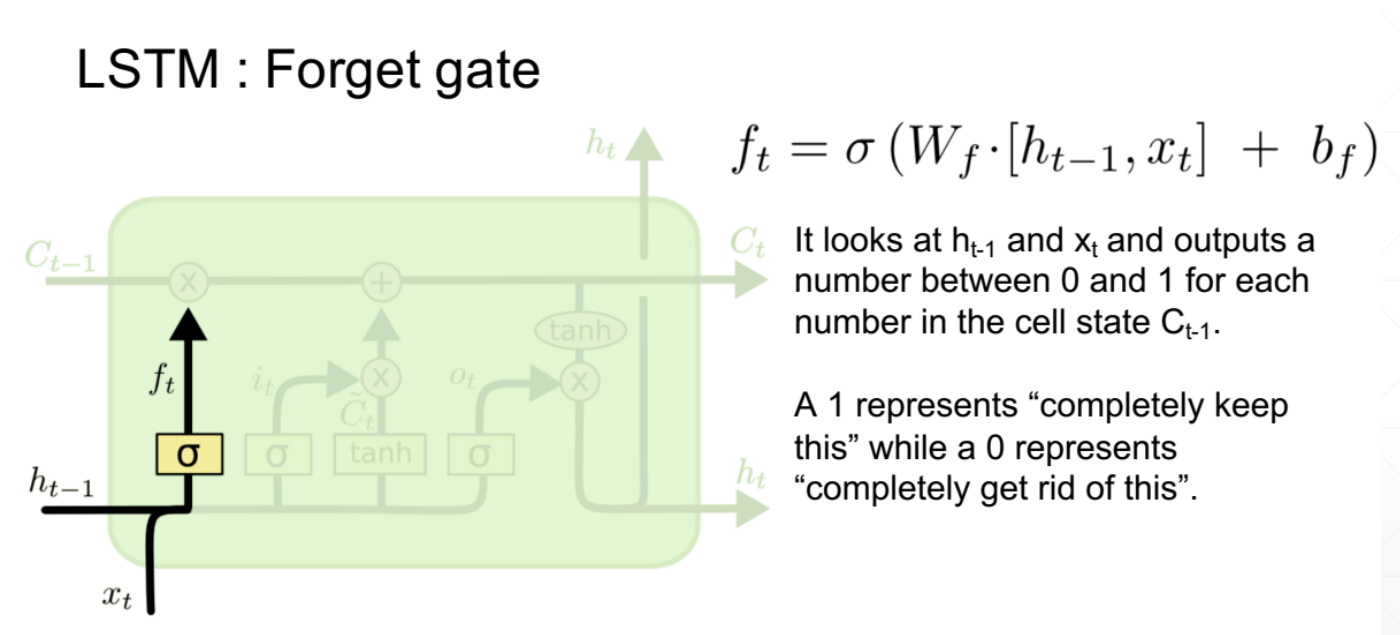
梯度爆炸
why?

梯度是有WR的k次方乘以其他的一些东西得到的

当WR大于1的时候,k次方会非常大
当WR小于1的时候,k次方会接近于0
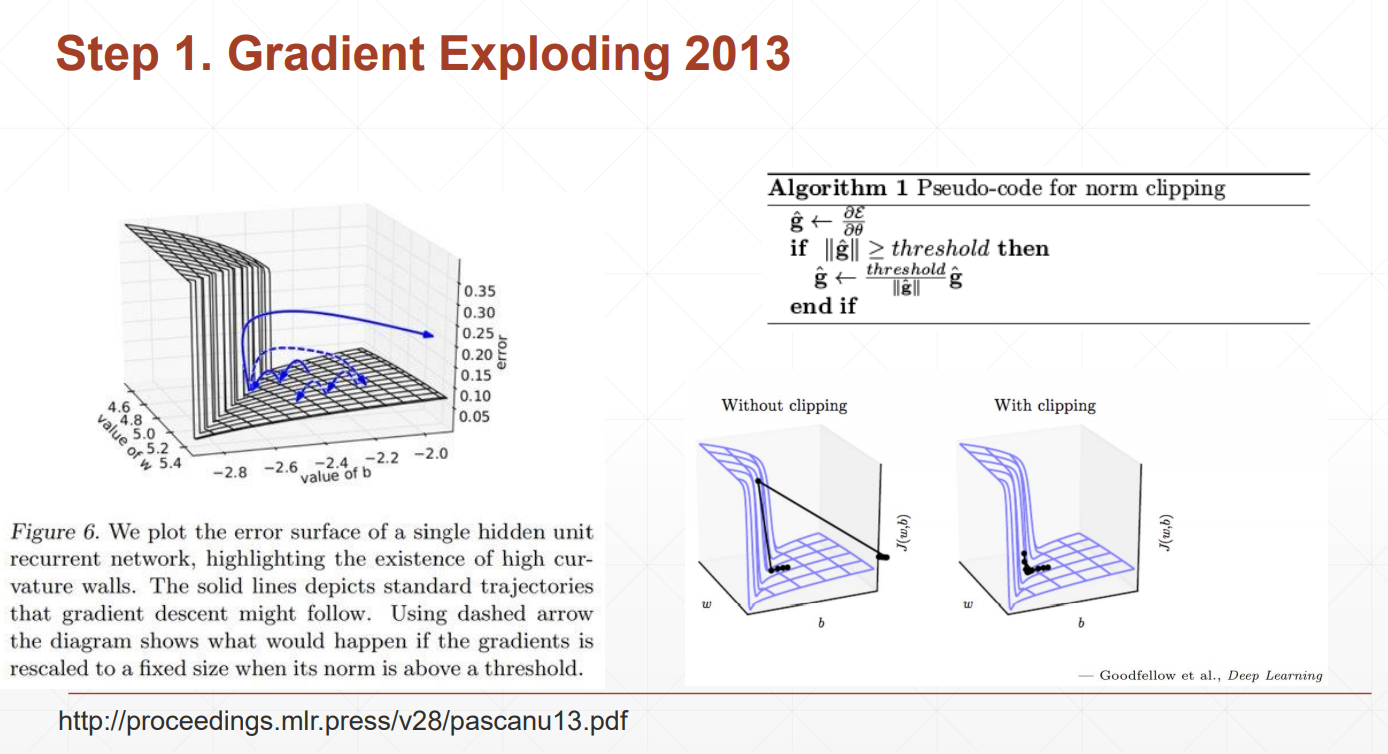
我们的loss本来是逐渐变小的,发生梯度爆炸的loss会突然增大,为了解决这个问题,我们可以检查当前位置的梯度值,如果大于我们设定的阈值,我们将用梯度本身来除以她此刻的模,再乘以阈值,这样使得梯度在设定范围内,且方向不发生变化
Gradient Clipping

查看一下梯度的模,利用clip_grad_norm把梯度的裁剪到10左右
梯度离散:后面隐藏层梯度变化比较大,前面的隐藏层梯度变化很小,长时间得不到更新
#序列化
import pickle#引入pickle模块
a1="蜡笔小新"
a2=234
a3=[10,20,30,40]
#把上面的内容添加一个二进制文件中
with open("data.dat","wb") as f:
pickle.dump(a1,f)
pickle.dump(a2,f)
pickle.dump(a3,f)
#现在是乱码状态,下面开始转换成可读的内容
with open("data.dat","rb") as f:
b1=pickle.load(f)
b2=pickle.load(f)
b3=pickle.load(f)
#打印出来
print(b1);print(b2);print(b3)
#测试a1是否于b1相等
print(id(a1));print(id(b1))
#不相等
蜡笔小新
234
[10, 20, 30, 40]
1617878845360
1617920883280
#读取和写入CSV文件
#引入CSV模块
import csv
#打开文件,注意:如果乱码,请在最后标明encoding的类型
with open("efg.csv","r",encoding='utf-8') as f:
a_csv=csv.reader(f)#读出文件内容
# print(list(a_csv))
for row in a_csv:#用循环读出文件内容
print(row)
#打开一个新的文件
with open("ee.csv","w") as f:
#获得一个写入器
b_csv=csv.writer(f)
#一行一行的写
b_csv.writerow(["ID","姓名","年龄"])
b_csv.writerow(["1001","工藤新一","17"])
c=[["1002","希希","18"],["1003","黑羽快斗","16"]]
b_csv.writerow(c)
['\ufeffID', '姓名', '年龄', '破案量']
['1001', '工藤新一', '17', '1000']
['1002', '服部平次', '18', '200']
['1003', '黑羽快斗', '16', '100']
ID,姓名,年龄
1001,工藤新一,17
"['1002', '希希', '18']","['1003', '黑羽快斗', '16']"
with open("e.txt","r",encoding="utf-8") as f:#打开文件
print("文件名是:{0}".format(f.name))#打印文件名
print(f.tell())#返回文件中指针的当前位置
print("读取内容:{0}".format(str(f.readline())))#读取文件的第一行
print(f.tell())#返回文件中指针的当前位置
print("读取内容:{0}".format(str(f.readline())))#读取文件的第二行
print(f.tell())#返回文件中指针的当前位置

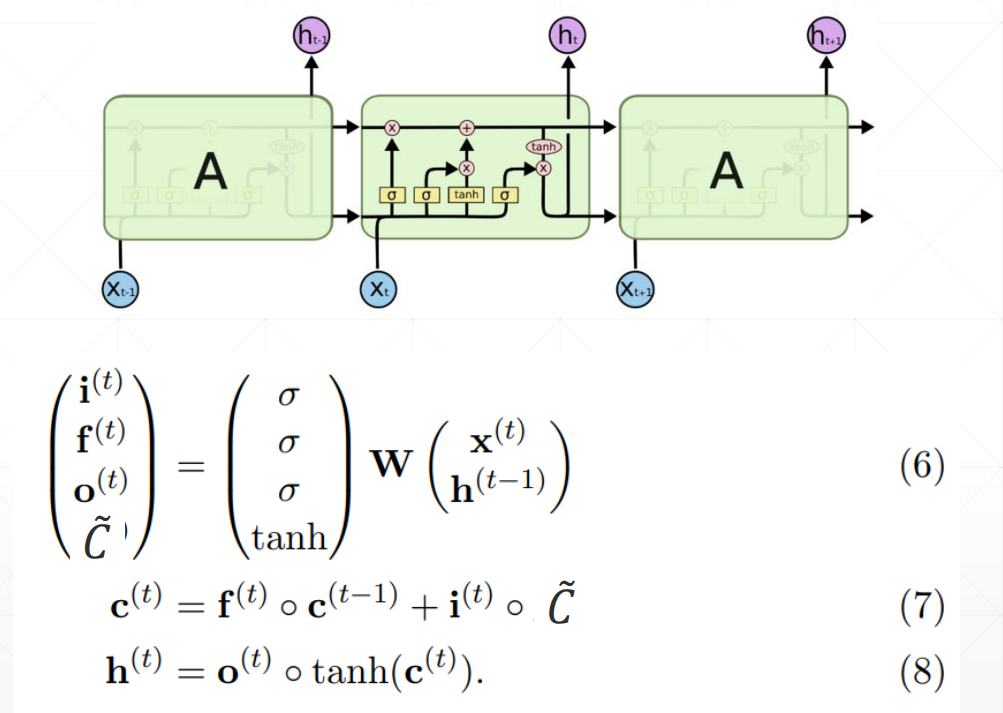
out是所有的时间戳上面最后一个memory状态
h是左右一个时间的所有memory状态
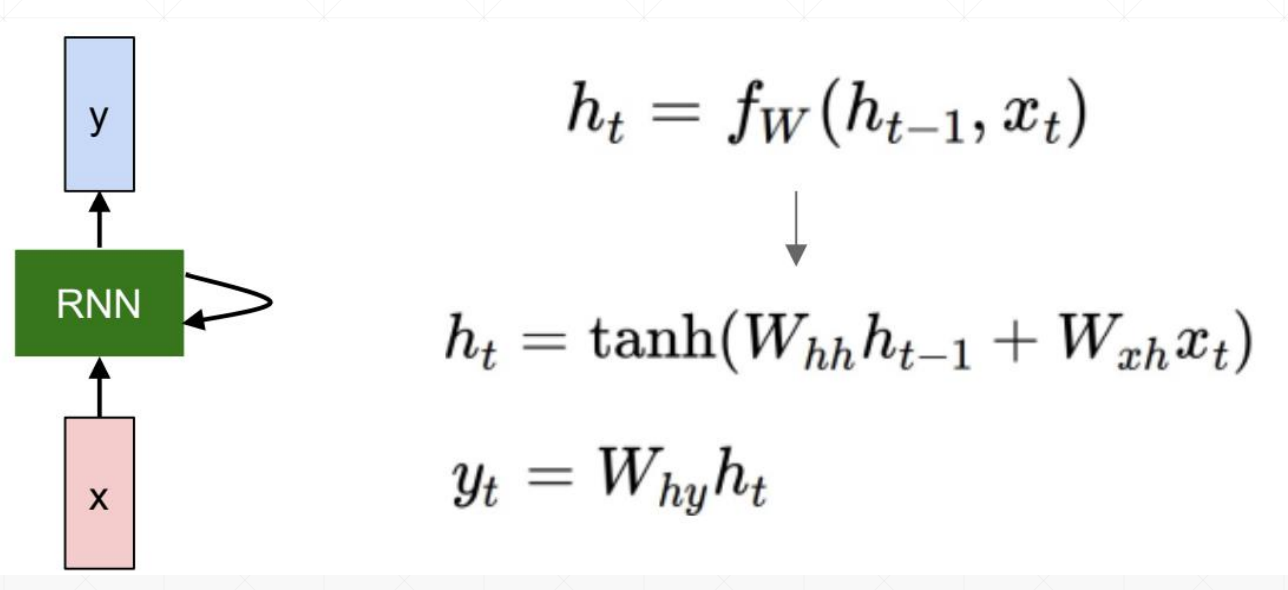
memory的更新方式
How to train?
求导过程略
RNN循环神经网络
RNN跟CNN最大的区别是会根据语境信息更新
时间序列表示方法
pytorch里面并没有支持字符串的功能
one_hot是比较稀疏的、维度高
sequence序列能接受的input shape有两种
[word num, b, word vec]
[b, word num, word vec]
