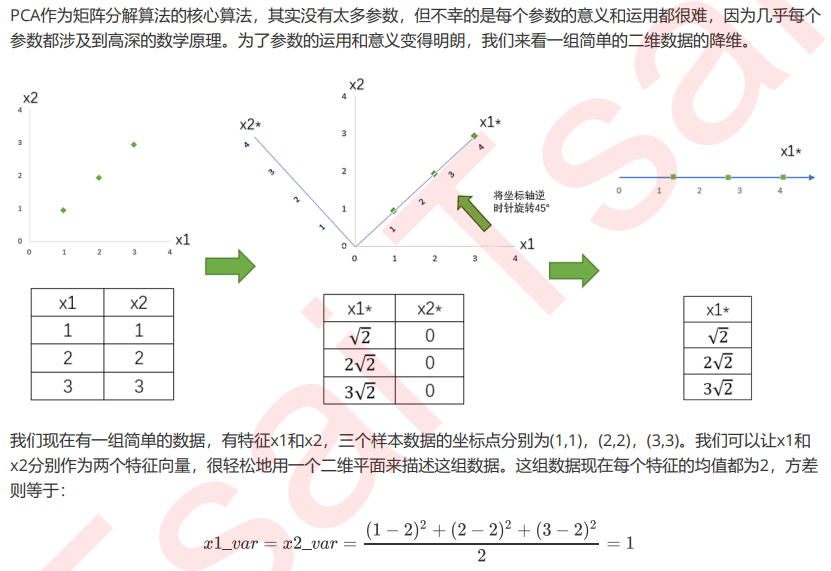
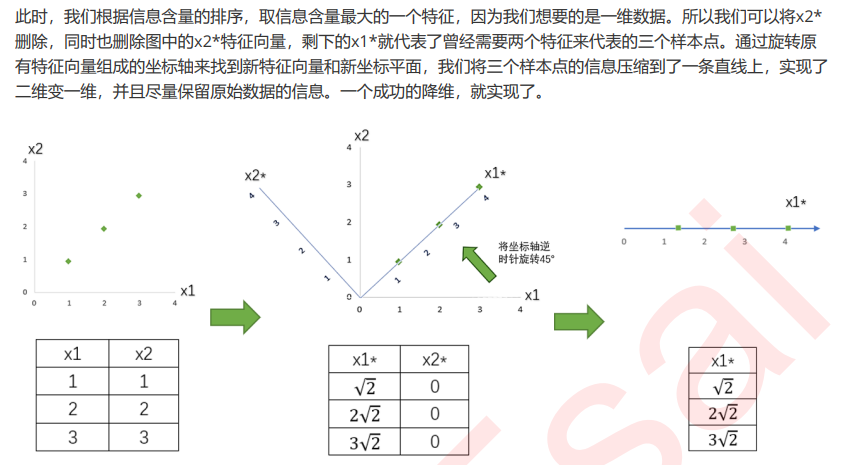
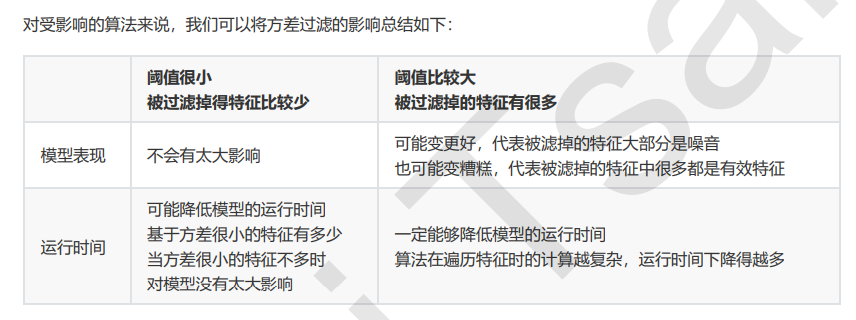
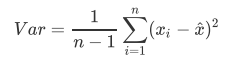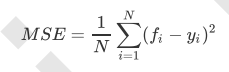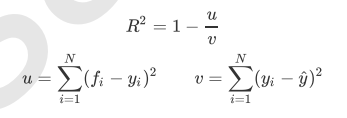重要参数n_components
n_components是我们降维后需要的维度,即降维后需要保留的特征数量,降维流程中第二步里需要确认的k值, 一般输入[0, min(X.shape)]范围中的整数。K是一个需要我们人为去确认的超参数,并且我们设定的数字会影响到模型的表现。就达不到降维的效果,如果留下的特征太少,那新特征向量可能无法容纳原始数据集中的大部分信息,因此,n_components既不能太大也不能太小。那怎么办呢?
可以先从我们的降维目标说起:如果我们希望可视化一组数据来观察数据分布,我们往往将数据降到三维以下,很 多时候是二维,即n_components的取值为2。