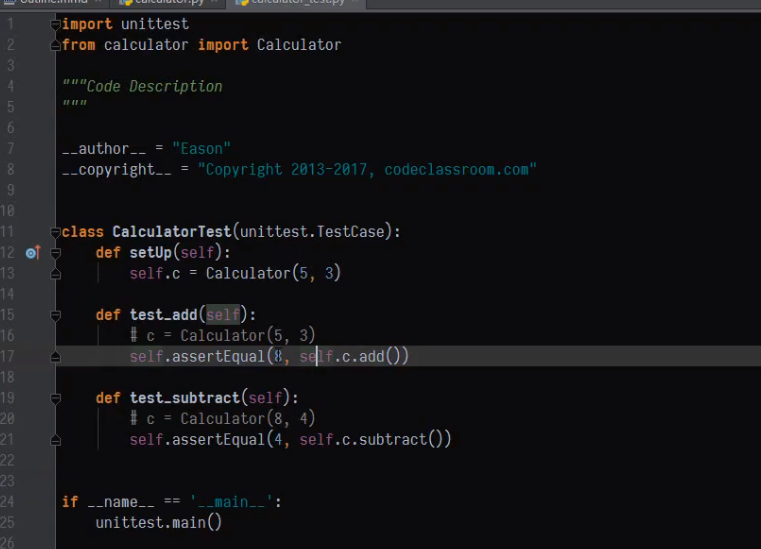


assertTrue 判断表达式是否为真
assertAlmostEqual 判断是否约等
assertIn 在字符串里
assertIs 判断是否为同一引用
assertEqual 判断值是否相等
assertIsNone 返回值是否为空
assertIsInstance 判断是否是某类型的实例(e.g. str)
assertGreater 是否大于
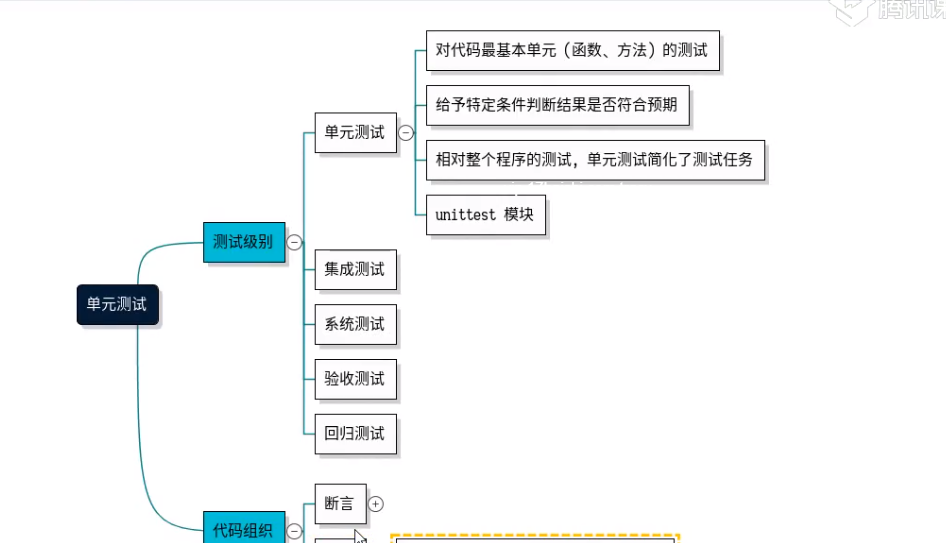
测试级别:
单元测试:对代码的基本单元(函数,方法)的cesh
集成测试
系统测试
验收测试
回归测试
错误异常处理
错误类型
1. 语法错误
2. 语义错误
3. 逻辑错误
异常处理
1. SyntaxError:语法错误(拼写问题等)
2. ZeroDivisionError: 处理异常
3. AttributeError: 属性异常
try:
x = 5/2
except 错误类型 as e: ('程序遇到错误',e) //捕获特定异常
else: //未遭遇异常时
finally: //必须要释放的内容e.g.文件
手动抛出异常:
raise AttributeError('属性错误')
简单的代码测试
import unittest
def get_formatted_name(first,last)
full_name = "{} {}".format(first,last)
return dull_name.title()
print(get_formatted_name)('Tom','Lee')
测试文件:
import unittest
from main import get_formatted_name
class NameTestCase (unittest.TestCase):
def test_title_name (self):
formatted_name = get_formatted_name('tom','lee')
self.assertEqual(formatted_name,"Tom Lee")
if __name__ =='__main__':
unittest.main()
测试文件中:
def setUp(self):
self.c = Coder('Tom')
self.c.skills = ['Python','.NET']
多态
import math
class Circle:
def __init__(self,radius):
self.radius = radius
@property
def area(self):
return math.pi*self.radius **2
def get_area(self):
return math.pi * self.radius **2
c = Circle(4.0)
print("圆的面积是:{}".format(c.get_area()))
print("圆的面积是:{}".format(c.area))
class Employee:
def __init__(self,department,name,birthdate,salary):
self.department = department
self.name = name
self.birthdate = birthdate
self.salary = salary
def give_raise(self,percent,bonus = .0)
self.salary = self.salary *(1+ percent) + bonus
def __repr__(self):
return'<员工:{}>'.format(self.name)
def working(self):
print('员工:{},在工作...'.format(self.name))
class Programmer(Employee):
def__init__(self,department,name,birthdate,salary,specialty,project):
super().__init__(department,name,birthdate,salary)
(或Employee.__init__(self,department,name,birthdate,salary))
self.specialty = specialty
self.project = project
def working (self):
print('程序员:{}在开发项目:{}...'.format(self.name,self.project))
if __name__=='__main__':
p = Programmer('技术部',‘Peter’,datetime.date(1990,3,3),8000,'Flask','CRM')
多态:属于同一类型的不同实例,对同一消息做出不同响应
class Department:
def__init__(self, department,phone,manager)
self.department = department
self.phone = phone
self.manager = manager
class Employee:
def__init__(self, department: Department,name)
self.department = department
self.name = name
if __name__ =='__main__':
dep = Department ('技术部','010-87718391','张三')
p = Programmer(dep,'Peeter')
print (p.department)
面向对象的特征:
封装
继承 提高代码重用
多态
class Book:
def __init__(self,title,price,author): //赋默认值的参数需在最后
self.title = title
self.price = price
self.author = author
if __name__=='__main__':
book = Book('Python经典',price=29.0,author='Tom')
实体化后调用时显示有意义信息的方法:
def __repr__(self):
return '<图书:{} at ox{}>'.format(self.title,id(self))
打印时:(若不用该函数,则与__repr__(self)代替)
def __str__(self):
return'[图书:{},定价:{}]'.format(self.title, self.price)
统计图书的个数 -- 全局 -- 和实例无关的东西不要写到init中,不加self
class Book:
count = 0
def __init__(self,title,price,author): //赋默认值的参数需在最后
self.title = title
self.price = price
self.author = author
Book.count+=1
def__del__(self):
Book.count -=1
//未绑定方法
def cls_method (cls):
priny(‘类函数’)
@staticmethod (//若加上可以通过实例调用,最好不要加)
def static_method():
print('静态函数,逻辑上与实例无关')
if __name__=='__main__':
book = Book('Python经典',price=29.0,author='Tom')
del(book3)
print('图书数量:{}.format(Book.count)') //此处count也可以通过实例名调用:book.count,但不建议,可自己改掉
Book.cls_method(book)
Book.static_method()
import datetime
class Student:
def__init__(self,name,birthdate):
self.name = name
self.birthdate = birthdate
方法1:
@property //属性,装饰器
def age(self):
return datetime.date.today().year - self.birthdate.year
@age.setter
def age(self,value):
raise AttributeError('禁止赋值年龄!')
@age.deleter
def age(self):
raise AttributeError('禁止删除年龄!')
方法2:定义函数
def get_age(self):
return datetime.date.today().year - self.birthdate.year
if __name__=='__main__':
s = Student('Tom', datetime.date (1992.3.1))
print(s.birthdate)
print(s.get_age( ))
print(s.age)
引入模块
import
import model
if __name =="__main__"
print(model.page)
from
from models from page
if __name =="__main__"
print( page)
from models import *
if __name =="__main__"
print( page)
取别名
import models.test as ...
from models import test ad m_test
使用模块的原因:
1.代码重用
2.命名空间
3.实现数据或服务共享
步骤:
1.找到模块文件
2.编译为字节码
3.运行模块文件
搜索范围:
1.当前程序主目录
2.环境变量目录下
3.标准库
4.扩展库import importlib、
重新载入(reload之前要importlib模块):
import importlib
importlib.reload(models)
错误写法:
from models import test
reload(models)
因为reload只认识模块,不认识from
按目录组织
directory只能从文件管理来管理文件
若要成为文件路径的一个部分 -- 包 -- python package
__init__.py只在当前包第一次被调用的时候执行
用途:第三方的库,包的导入
3.3以下改文件必须要,3.3以上可省略
面向过程:c(最贴合硬件,底层开发) -- 数据结构和算法
面向对象:抛开代码,以符合人的思维习惯分析解决问题,对象的特征和行为
面向对象
图书管理系统
面向过程的三个特性:
封装(提高代码重用,降低代码冗余)
def search_book(title)
print('搜索包含关键字{}的图书'.format(title))
book = {'title': 'python 入门', 'price':39.00,'author':search_book}
print(book.get('price',0.0))
book.get('search_book')('python')
步骤:
1.面向对象分析:OOA
2.类定义对象代码模板(蓝图)uml关系类图(把分析对象编程代码)OOD
3.实例化(创建内存对象)OOP
实现:
1.分析对象的特征和行为
2.写类描述对象模板
3.实例化,模拟过程
继承 多态
代码:
import datetime
class Book: //类名大写字母开头
def __init__(self,title,price=0.0,author=' ',publisher= None,pubdate=datetime.date.today()): //初始化器
self.title = title
self.price = price
self.author = author
self.publisher = publisher
self.pubdate = pubdate
def __repr__(self):
return '<图书{}>'.format (self.title)
def print_info(self):
print('当前这本书的信息如下:')
print('标题:{}'. format(self.title))
print('定价:{}'. format(self.price))
print('作者:{}'. format(self.author))
print('出版社:{}'. format(self.publisher))
print('出版时间:{}'. format(self.pubdate))
book1 = Book('c#经典', 29.9,'Tom','优品课堂',date(2016,3,1)) //实例化
book2 = Book('入门到精通')
book2.author='优品'
book1.print_info()
动态类型
函数的参数匹配
def func(a,b,c)
print(a,b,c)
fun(1,2,3)//默认位置匹配
fun(c=1,b=2,a=3)//名称匹配
默认一些值时:
def func(a,b=2,c=3)
print(a,b,c) //调用时可省略传值
func('a','b','c')
重载
或使用tuple来传递参数,但一定要传至少一个
def avg(score,*scores)
//或 def avg(*scores)
return sum(scores)/len(scores)
不能直接传一个定义好的tuple
//错误情况:
score = (89,90,91)
result = avg(score)
//正确情况
score = (89,90,91)
result = avg(*score)
//直接传字典表
def display(**employee)
print(employee)
display(name=‘tom’,age=22)
字典表的两种声明方法
或
emp=dict(name=‘tom’,age=22)
def display(**employee)
print(employee)
display(**emp)
*args 任意量参数
**kwargs 任意量关键字参数
lambda表达式 -- 定义匿名函数
f = lambda name: print(name)
f('tom')
f2 = lambda x,y: x+y
print(f2(5,3))
def hello_chi(name):
print('您好',name)
def hello_eng(name):
print('hello',name)
while True:
name=input(‘请输入姓名:\n’)
if name = ‘stop’:
break
language = input(‘请选择语言:\n c:中文版\n, e:英文版\n j:日文版')
if language language =='c':
hello.chinese(name)
elif language =='e':
hello_english(name)
elif language =='j':
(lambda name:print('...',name))(name)
if language language =='c':
action = hello.chinese
elif language =='e':
action = hello_english(name)
elif language =='j':
action = lambda name:print('...',name)(name)
action(name)
字典表可以给方法
def hello_chinese(name):
print('你好:',name)
def hello_english(name):
print('hello:',name)
operation={
'e': hello_english,
'c': lambda name : print ('你好', name)
}
while True:
name = input('请输入姓名:\n')
if name == 'stop':
break
language = input ('请选择语言版本:\n' c: 中文版\n e:英文版\n)
operation. get(language, hello_chinese)(name)
def hello_chinese(name):
print('你好:',name)
def hello_english(name):
print('hello:',name)
def hello(action,name):
action(name)
hello(hello_chinese,'Tom')
hello(lambda name: print('...',name), 'Tom')
l = list(range(1,21))
result = []
//1. 使用循环,效率最低
for n in l:
if n % 2 ==0
rasult.append(n)
//2.使用推导
result = [x for x in l if x%2 == 0]
// 高级工具:map(),返回结果为map类型
def add_num(x):
return x+5
res = list(map(add_num,l) ) //灵活性最高
//若不写list则显示不出来列表
res = list(map(lambda n: n**2,l)
print(result)
filter(函数,可迭代对象)
l = list (range(1,11))
def even_num(x):
return x%2 ==0
res = list(filter(even_number,1))
print(res)
或: res = filter (even_num,1)
for n in res:
print(n,end='')
或:
res =filter(lambda n: n%2 ==0, 1)
推导最好
函数 function
定义代码目的:最大化代码重复&最小化代码冗余&过程分解
def 函数名():
形参
实参
从外往里传
从里往外传:返回一个值
函数变量的作用域local(区分global)
形参的生命周期在函数体内(本地)
x=55
def func():
x=99
print(x)
x=55
def func():
global x
x=99
print(x)
built-in(作用域比global还要高)
封装(函数套函数时用到)
def func():
x=100
def nested():
x=99
print(x)
print (x)
//nested没调用,所以没有print
def func():
x=100
def nested():
x=99
print(x)
nested()
print (x)
外层x成为封装--enclosure (local之上global之下)
用外侧封装的生命
def nested():
nonlocal x
定义新函数会覆盖原来的内置函数
参数:
def change_num(x)
x+=10
x=5
print('x={}'.format(x)) //5
change_number(x)
print('x={}'.format(x)) //5
整型这一数据类型不能改变
由于这一特性,在函数调用x时x传的值为副本,即x一直不改变
函数的传递时,不可变类型(int float tuple str)传递副本给函数,函数内操作不影响原始值
可变类型(列表,字典表),传递地址引用,函数内操作可能会影响原始值
change_list(l[:])
change_list(l.copy())
迭代(iterate)
可直接遍历的类型:list, tuple, dictionary, file
可迭代的对象(实现迭代器协议的对象)支持遍历/循环 -- 目的:节省内存
可实现迭代协议的对象:对象内部有next方法:__next__()
f.__next__()
全局方法:next(f)
file 有__next__
list没有
但为啥还能for,因为for实现了额外步骤
可迭代的对象
字典表遍历时只能遍历取出键
d={'a':1,'b':2}
for k in d:
print{k}
如下写法错误:
d={'a':1,'b':2}
for k,v in d:
print{k,v}
迭代工具
for
推导
map
迭代器对象&可迭代对象
迭代器对象对象已经实现
可迭代对象需要额外加iter()方法,用于生成迭代器,用for时自动生成 __iter__()
iter(f) is f
True 则说明是迭代器对象
若需要可迭代对象能使用__next__()函数,可以用:i = iter(urls) 当urls为列表时
为什么列表不实现:因为列表可嵌套列表,可能使结构复杂
内置可迭代对象
(1)range() 类型为range
zip //负责将两个集合合成一个
result = zip (['x'],[1])
类型为zip
print结果为元组
有next方法
map将每一个元素应用函数的执行
while循环
while true: (死循环)
x = 'youpinketang'
while x:
print (x, end = '')
x=x[1: ]
break
从循环中跳出
continue
跳到循环头部进行下一次循环
while x:
x-=1
if x%2 !=0:
continue
print(x,end='')
while True:
name = imput('请输入您的姓名:')
if name =='stop'
break
age = imput('请输入您的年龄:')
print('您好:{},您的年龄是:{},欢迎学习'。format(name,age))
pass
占位符,对代码的不确定
else
for 循环:
found = False
for x in range (1,5)
if x ==6:
found = True
print('已经找到了',x)
break
if not found:
print ('没找到')
for x in range(1,5):
if x ==6:
print('有这个数字',x)
break
else:
print('没找到')
for x in [1,2,3,4]:
print (x, end =' ')
sum = 0
for x in [1,2,3,4,5]
sum+=x
print(s um)
只遍历字典表的键
for key in emp:
print('{} =>{}'.format (key, emp.get(key,'未找到')))
or
for key in emp.keys():
print(key)
只遍历值
for key in emp.values():
print(key)
values不是列表,是可使用for,while循环的可迭代的试图结构,为了减少对内存的占用
找交集
result =[]
for x in s1:
if x in s2:
result.append(x)
print (result)
l = [x for x in s1 if x in s2]
print(l)
range()
for x in range (1,101,2)
enumerate():可获得现在在循环的是第几项
s='youpinketang'
for idx, item in enumerate(s):
print('{}){}'.format(idx,item))
语句,表达式,流程控制
1. 代码风格
(1)代码格式指南-PEP8
(2)缩进4空格
(3)一行不超过79字符
(4)等于号前后空格
(5)空行,逻辑分割的隔两行
2.语句
(1)赋值语句
x=5
通过元组赋值:(x,y) = (5,10)
x,y=5,10
序列声明变量可以接受任意类型
序列赋值:
[a,b,c]=(1,2,3) 左右数量对应时不会出错
a,b,c='uke'
多了:
若序列赋值左右数量不一致时会报错,避免方法:列表的切割:
方法1
s='youpin'
a,b,c=s[0],s[1],s[2:]
方法2
a,b,*c=s
扩展序列解包赋值(c后的为序列)
a,*b,c=s
不够:
后面多出来的是空列表
ps:只能有一个星号
多目标赋值
a=b=c='uke'
(2)a = b =[]
a.append(3)
//b也相应变成[3]
分开方法:
a=[]
b=[]
a.append(3)
分开方法2
a,b=[],[]
参数化赋值
+=
列表的参数化赋值
l=[1,2]
l+=[9,10]
加元素 append
加列表extend (和+=比效率更高)
表达式
(1)函数调用
(2)方法调用
(3)字面值
(4)打印操作
打印两个:
url = 'www.codeclass.com'
s='123'
print(url,s,sep='|' )
print(s,url,end='...\n')
将信息打印到文件:
print (s,url,end='...\n',file=open('result.txt','w',encoding='utf8'))
流程控制
(1)if语句
score = 75
if score >=90:
print ('优秀')
elif socre >=80
print('良')
elif score >=60
print('及格')
else print('不及格')
多重分支
def add(x):
print (x+10)
operation = {
'add':add,
'update': lambda x: print(x*2)}
}
def default_method(x):
print('无处理')
operation.get('delete',default_method)(10)
三元表达式
if score >=60
result='及格'
else
result = '不及格'
等价于
result = '及格' if score>=60 else score<60
文件与类型汇总
1. 基本语法:file = open('文件名',mode)
写文件:myfile=open('hello.txt','w')
myfile.write('优品课堂\n')
myfile.close()
读取文件:f=open('hello.txt','r')('r'可省略)
f.read() --读取所有内容
read相当于指针
重新打开: f = open('hello.txt')
f.readline()
f.readline()
放入列表:
l = open ('hello.txt').readlines() (类型为列表)
for line in l
print(line)
为了防止乱码可指定编码:
f = open ('course.txt','w',encoding='utf8')
读取二进制文件:rb
2. mode: r(读) w(写)a(追加) b(二进制文件)+(读+写)
3.类型的丢失
x,y,z=1,2,3
l=[1,2,3]
f=open('datafile.txt','w')
f.write('{},{},{}'.format(x,y,z))
f.write(str(l))
f.close()
chars = open('datafile.txt').read()
序列化--pickle存取python对象:
d ={'a':1,'b':2}
f = open('datafile.pkl','wb')
import pickle
pickle.dump(d,f)
f.close()
不要用记事本打开
open('datafile.pkl','rb').read() (读取无意义)
f = open ('datafile.pkl','rb')
data=pickle.load(f)
data['a']
data.get('b')
防止忘记关闭文件的做法:
传统方法:
f=open('course.txt')
l=f.readlines()
for line in l
print(line)
close()
新方法
with open('course.txt') as f
for line in f.readlines()
print(line)
数据类型汇总:
集合
1.序列 可变(列表list)/不可变(字符串string,元组tuple,字节数组)
2.映射 字典表dict
3.集合 set:集合信息不能有重复,花括号,但没有键
数字
1.整型 int/boolean
2.浮点型 float/decimal/fraction
可调用
1.函数 function
2.生成器 Generation
3.类 Class
4.方法
其他
1.模块
2.实例
3.文件
4.None
5.视图
内部
1.type
在内存中的表现:
l=['abc',[(1,2),([3],4)],5]
字典表 dict (映射类型)
通过键值对存储索引
1.定义代码
(1)通过字面值d={'ISBN':'223421','Title':'python入门','price':39.00}
(2)通过dict构造函数声明
emp = dict (name='Mike', age=20,job='dev')
呈现的顺序不是输入顺序,乱序(根据键哈希以后产生的结果)
2.通过方括号下标索引来找
3.插入一个值
d['author']='Jerry'
4.与列表的区别:列表不能访问不存在的索引
6.检索某一键值(防止抛异常)
d.get('price')
7.用get设置默认值防止抛异常
d.get('price',0.0)
8.字典表长度
len(emp)
9. 字典表可以原位改变
d['Price']=99.00
10.字典表的合并
dep = {'department':'技术部'}
emp.update(dep)
11.弹出某一项
emp.pop('age')
12.只关注键
dict.keys() --返回视图
13.只关注值
dict.values()
for k in emp.keys():
print(k) //像列表一样遍历
14. emp.items()
形式变换:
for k,v in emp.items():
print('{}=>{}'.format(k,v))
14.列表不能作为键,只能是不支持原位改变的作为键
15.支持嵌套
emp = {'age':20,'name':{'firstname':'Jerry','lastname':'Lee'}}
取出:
emp.get('name')
emp['name']['firstname']
16.排序
方法1:
ks = list(d.keys())
ks.sort()
for k in ks:
print(d.get(k))
方法2(全局函数):
ks=d.keys()
for k in sorted(ks):
print(k,d.get(k))
元组tuple
1.与列表类似,但不支持原位改变,圆括号声明。
2.是任意对象的有序集合,通过下标访问,属“不可变”类型,长度固定,任意类型,任意嵌套
3.元组的声明
(1,2)
(1,2)+(3,4)
1,2
单个元素声明元组(逗号用来标识类型):
x=(40,)
求长度:len(x)
x
4.通过元组的特性便于交换变量
5.支持推导
方法1:
for x in t:
print(x**2)
方法2(放入列表中):
(1) res = []
for x in t:
res.append(x**2)
(2) res = [x**2 for x in t]
6.检索元素位置
t.index(3)
7.统计元素次数
t.count(3)
8.namedtuple
from collections import namedtuple
Employee = namedtuple ('Employee', ['name','age','department','salary'])
Jerry= Emloyee('Jerry',age=30,department='财务部',salary=9000.0)
Jerry.name
布尔型和列表
1. python中的布尔型介于true/false和int型之间,本质相当于int的0,1
2. 列表支持原位改变
l=list(s)
s=''.join(l)
3. 字符串分割
url.split(',')---分割成列表
l=url.split(',')
4. function -- 函数
s.split() -- 方法
5. .startswith, .emdwith, .find(返回位置)
6. 格式化字符串
'{0} => {1}'.format (a,b)
7. upper
列表 list
1. 与数组相似,但类型可以不一致,是任意对象的有序集合,可以通过索引下表访问元素,长度可变,属可变序列(可原位改变)。
2. 基本操作
len([1,2,3])
相加
将字符串的字符变为元素 list
取出:遍历
判断是否在列表中:遍历 or in
'k' in l
for c in l:
print(c, end='|')
(tab和空格不要混合使用)
运算:
l= [1,2,3,6,9]
res=[]
for i in l:
res.append(i**2)
列表的 推导:
l1=[i**2 for i in l]
[]*3
追加 .append 追加一个元素
扩展 .extend 扩展一个列表
内置排序算法:l.sort(); l.reverse()
l.pop() -- 类似于堆栈的操作
删除元素:del (l[0])(全局函数)
找出元素位置l.index(7)
数元素个数l.count(7)
修改列表时是否影响其他列表(是引用类型,支持原位改变的问题)
l2=l1 影响
拷贝副本(不影响)
l3=l1.copy() 不影响
l4=l1[:] 不影响
数值与字符串
1. 数值类型
1.1 变量要先声明再使用,声明需至少赋一次值
print (age)
Traceback (most recent call last):
File "D:\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 3296, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-dbcadc9b8512>", line 1, in <module>
print (age)
age = 20
print (age)
20
1.2 浮点型精度问题--计算机硬件存储结构描述浮点型的特性造成--可用decimal解决
1.1+2.2
Out[5]: 3.3000000000000003
1.3 数值显示的格式化(保留小数位数)
(1)仅在界面上显示情况发生变化:通过字符串
f=3.33333
'f={0:.2f}'.format(f)
1.4 比较,返回结果为布尔型
1.5 相除
10/4
10//4
10//4.0
向左
import math
math.floor(3.4)
向0
math.trunc(3.94)
四舍五入
round
1.6 python的整型大小只受限于内存大小和计算机配置
八进制:0o开头
十六进制:0x开头
二进制:0b
转换:oct(八进制)hex(十六进制)bin(二进制)
1.7 decimal
import decimal
decimal.Decimal('3.14')
2. 字符串
2.1 声明
2.1.1 直接声明 '', ""
2.1.2 定义说明文档 """ """ 不会被忽略,可生成文档
2.1.3 转义符 --地址:path='C:\\abc\\xyz.txt'
忽略转义符:path = r 'c:\abc\xyz.txt'
\
\n 换行
\b 退格
\t Tab
\a 响铃
2.1.4 字符串基本操作
(1)len
(2)s = 'hello'
for c in s
print (c, end=' ')
(3) 选取
s[0]
s[0:4]
s[-1]
s[len(s)-1]
s[:]
s[::2]
s[::-1]
(4) 字符串和整型不能相加
(5)字符和asc码的对应关系
ord
chr
(6)不支持原位改变
若改变则用:
h.replace('e','a')
h=h.replace('e','a')
1、windows命令提示符
切换盘
进入目录:cd
返回上级目录:cd..
返回根目录cd\
列出目录:dir
2、 代码(.py)--解释器--字节码(.pyc)--PVM托管运行-- 机器码
3 、变量表 对象 类型约束
动态类型