系统工具
概念:
命令行工具
shell脚本
系统管理
系统模块:
sys 提供一组功能映射python运行时的操作系统
os 提供跨平台可移植的操作系统编程接口
os.path 提供文件及目录工具的可移植编程jie


系统工具
概念:
命令行工具
shell脚本
系统管理
系统模块:
sys 提供一组功能映射python运行时的操作系统
os 提供跨平台可移植的操作系统编程接口
os.path 提供文件及目录工具的可移植编程jie
应用
字符串操作
.split(string, maxsplit = 0) 分割字符串
text = 'Beautiful is better than ugly. \nExplicit is better than implicit.\n Simple is better than complex'
re.compile(r'\n')
p.split(text)
re.split(r'\n',text)
re.split (r'-','Good-morning') //减号本身不是分组一部分
re.split (r'(-)','Good-morning') //减号本身是分组一部分
re.split (r'\n',text,1) //最多分割几个
字符串的替换
.sub(rep1, string,count =0 )
ords = 'ORD000\NORD001\NORD003'
re.sub(r'\d','-',ords)
//或:
p = re.compile(r'\d')
p.sub('-',ords)
re.sub(r'\*(?P<html>.*?)\*','<strong>\g<html></strong>',text)
re.sbu(r'([A-Z]+)(\d+)','\g<2>-\g<1>',ords)
re.sbun(r'([A-Z]+)(\d+)','\g<2>-\g<1>',ords) //同时返回替换了几次
编译标记
改变正则的默认行为
re.I 忽略大小写
re.M 匹配多行
re.S 制定'.'匹配所有字符,包括\n
import re
text = 'Python python PYTHON'
re.search(r'python',text)
re.findall(r'python',text)
re.findall(r'python',text,re.I)
re.findall(r'<html>',\n<html>,re.M)
//输出结果['<html>']
re.findall(r'\d(.)'.'1\ne',re.S)
//输出结果['\n']
模块级别操作
re.purge() 清除缓存
re.findall(re.re.escape()'shift+6','shift+python+shift+6')
Group编组
场景
1.从匹配模式中提取信息
2.创建子正则以应用量词
import re
re..search(r'(ab)+c','ababc')
3.限制备选项的范围
re.search(r'Cent(er|re)','Center')
4.重用正则模式中提取的内容
re.search(r'(\w+) \1','hello world') //模式,内容都一致\x,这里的x表示序号,索引从1开始
声明
1.(模式)
2.(?P<name>模式)
import re
text = 'Tom:98'
pattern = re.compile(r'(?p<name>\w+),(?p<score>\d+)')
m = pattern.search(text)
引用
1.在匹配对象内用 m.group('name')
2.在模式内用 (?p = name)
3.表现内 \g<name>
text = 'Tom is 8 years old. Jerry is 23 years old.'
pattern = re.compile(r'\d+')
pattern.findall(text)
.group()
1. 参数为0或空返回整个匹配
2. 有参时赶回特定分组匹配细节
3. 参数可以是分组名称
.groups() 返回包含所有子分组的元组
.start() 返回特定分组的起始索引
.end() 返回特定分组的终止索引
.span() 返回特定分组的起止索引元组
.groupdict() 以字典表形式返回分组名及结果
//分组
pattern = re.compile(r'(\d+).*?(\d+)')
m = pattern.search(text)
m.group() //等价于m.group(0)
m.group(1)
m.start(1)
m.end(1)
m.groups()
//('8','23')
import re
pattern = re.compile(r'(\w+)(\w+)')
text = "Beautiful is better than ugly."
pattern.findall(text)
//输出:[('Beautiful','is'),('better','than')]
it = pattern.finditer(text)
for m in it:
print(m.group())
正则表达式
1.re模块
import re
text = 'Tom is 8 years old. Mike is 25 years old.'
pattern = re.compile('\d+') //反复重用时,编译提高运行效率
pattern.findall(text)
//输出结果为['8','25']
//方法2(不编译)
re.findall('\d+',text)
//输出结果为['8','25']
2. RegexObject
模式对象,表现编译后的正则表达式(编译为字节码并缓存)
编译:re.compile('模式')
import re
s = "\\author:Tom"
pattern = re.compile('\\\\author')
pattern.findall(s)
//或
pattern = re.compile(r'\\author')
RegexObject行为
.findall()
(1)查找所有非重叠匹配项
(2)返回list
.match(string[,pos[,endpos]])
MatchObject
匹配,仅从起始位置
import re
pattern = re.compile(r'<html>')
text = '<html><head></head><body></body></html>'
pattern.match(text)
//匹配成功
text = ' <html><head></head><body></body></html>'
pattern.match(text)
//匹配失败,返回空,因为match从开始位置来匹配
pattern.match(text)
//匹配成功
search(string[,pos[,endpos]])
在任意位置搜索
返回MatchObject
text = ' <html><head></head><body></body></html>'
pattern.search(text)
.finditer( )
查找所有匹配项
返回包括MatchObject元素的迭代器
it = p1.finditer(text)
for m in it:
print(m)
正则表达式匹配规则:
元字符:
匹配:
1. 匹配单字,预定义元字符
. 除了\n外的所有字符
\d,[0,9] 匹配数字
\D, [shift+6 0-9] 匹配所有非数字
\s 空白字符 \t\n\r\f\v
\S 空白字符 [shift+6\t\n\r\f\v]
\w; [a-zA-Z0-9_]匹配字母,数字,字符
\W; [shift+6 a-zA-Z0-9_]非字母,数字,字符
2.批量备选
1.| yes|no
3.量词
1. ? 0或1次
2. * 0或多次
3. + 1或多次
4. 特定
(1) {n,m} 范围次数
(2) {n} n次
(3) {n,} 至少n次
(4) {,m} 最多m次
4. 贪婪与非贪婪
(1)贪婪(默认):尽量匹配最大范围结果
(2)非贪婪:尽量匹配最小的范围结果
方法:量词后追加?
例:??/*?/+?
5. 匹配边界
shift+6 行首
shift+4 行尾
\b 单词边界
\B 非单词边界
\A 输入开头
\Z 输入结尾
注:
正则表达式
1. regular expression
2. 一种文本模式,描述在搜索文本时要匹配的一个或多个字符串
ctrl+F
\d+
[A-Z]\w+
典型场景:
1.数据验证
2.文本操作
3.文本提取
4.文本替换
5.文本分割
语法:
1.字面值
(1)普通字符
(2)需转义 \;shift+6;shift+4; . ; | ; ? ; *; +; (); []; {}
2.元字符
BOM处理
open('data.txt','r',encoding='utf8').read()
//额外存储字节顺序标记/ufeff
open('data.txt','r',encoding='utf8-sig').read()
//忽略标记
open('data3.txt','r',encoding='utf8-sig').write('123')
//加入字节顺序标记
类型转换
字符串获取字节的方法(字节不能原位改变):
1.通过encode方法
s = abc
s.encode()
2.通过bytes函数
bytes('abc','ascii')
bytes([87,65,89,97]) //只能在0-255
3.b = b'abc'
字符串字节的读取和编码的读取:
open('data.txt','rb').read()
open('data.txt','rb').read()
bytearray(可原位改变)
ba = bytearray(s1,'utf8') //bytearray(b'abc')
ba[0] = 98 //bytearray(b'bbc')
ba.append(93) //append的数要在256之内
ba +b'c!'
转化为字符串
ba.decode()
str.encode('编码') 将特定字符编码
s1 = 'ABCD'
s1.encode('ASCII')
s2 = '优品课堂'
s1.encode('UTF-8')
str.decode('编码') 将字符编码解码为字符文本
b1 = b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82'
b1.decode('utf-8')
//不指定编码方式,默认以utf-8
s1.encode()
如何获知系统默认的是哪种编码方式:
(1)s2.encode //输入后系统会显示提示
import sys
sys.getdefaultencoding()
文件操作是按照gbk的形式写的
字符编码
ASCII: 存储在一个Byte 0-127
ord('A')
chr(104)
latin-1: 存储在一个Byte 128-255
utf-16: 2Byte存储字符(另加2Byte作为标识)
utf-32:4Byte
utf-8:可变字节:0-127使单字节
128-2047双字节存储
>2047 3Byte
(每Byte使用128-255)
保持最大限度的兼容性的同时,减少存储字节大小
字符串
数据类型
1. str 字符串
2.bytes 字节
3. bytearray 字节数组
utf8 可变编码
字符编码架构:
字符集:赋值一个编码到某个字符,以便在内存中表示
编码encoding:转换字符到原始字节形式
解码decoding:依据编码名称转换原始字节到字符的过程
字符串存储:
编码只作用域文件错处或中间媒介转换时
内存中总是存储解码以后的文本
pickle不便于把多个对象存储在一个文件里
shelve //更适用于自定义的类
import shelve
scores = [99,88,77]
student = {'name':'Mike', 'age':20}
db = shelve.open('shelve_student') //创建为二进制
db['s'] = student
db['scores'] = scores
len(db) //2
temp_student = db['s']
type(temp_student)
del db['scores']
class Student:
def __init__(self,name,age):
self.name = name
self.age = age
def__str__(self):
return self.name
def write_shelve():
s =Student('Tom', 20)
db = shelve.open('shelve_student_db')
db['s'] = s
db.close()
def read_shelve():
db = shelve.open('shelve_student_db')
st = db['s']
db.close()
if __name__ =='__main__':
read_shelve()
read_shelve()
pickle
import pickle
person = {'name : 'Tom', 'age': 20}
s = pickle.dumps(person)
p = pickle.loads(s)
dumps 对象到字符串
loads 字符串到对象
序列化对象到二进制文件
pickle.dump(person, open('pickle_db','wb'))
p = pickle.load(open('pickle_db','rb'))
scores = [88,99,77,55]
def write_scores():
with open('data_list.txt','w',encoding = 'utf8') as f:
f.write(str(scores))
print('文件写入完成...')
def read_scores():
with open('data_list.txt','r',encoding = 'utf8') as f:
lst = eval(f.read())
if __name__ =='__main__':
write_scores()
对象持久化
文本文件存储--扁平文件
pickle
shelve
数据库
ORM
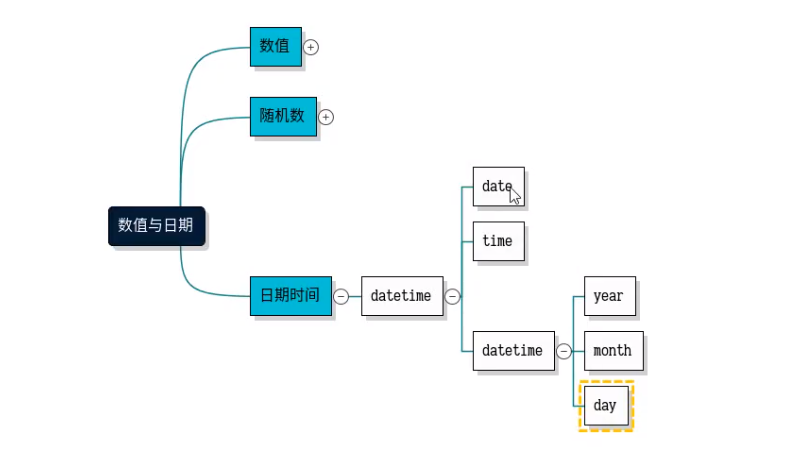
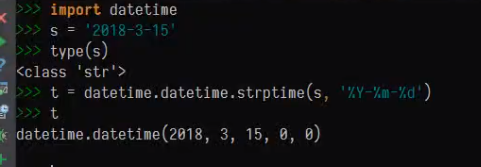
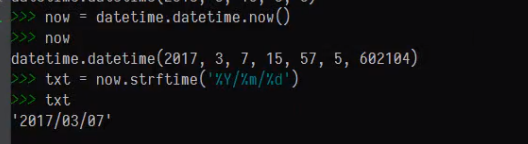
时间差处理