写代码开发的工作,做为一场战争的话,
写出来的代码,相当于士兵与武器
故,数据结构与算法是一名程序开发人员的必备的基本功,不是一
算法,就是让计算机把问题解决出来,计算的方法
算法是计算机处理信息的本质,因为计算机程序本质是一个算法来告诉计算机确切的步骤来执行一个指定的任务。
一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用
算法是独立存在的一种解决问题的方法与思想
对于算法而言,实现的语言并不重要,重要的是思想。
算法可以有不同的语言描述实现版本(如C描述,C++描述,python描述等),我们现在是在python语言进行描述实现
算法的五大特性:
输入:算法具有0个或多个输入
输出:算法至少有1个或多个输出
有穷性:算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在接受的时间内完成
确定性:算法中的每一步都有确定的含义,不会出现二义性
可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
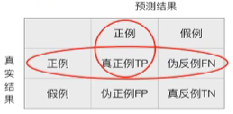
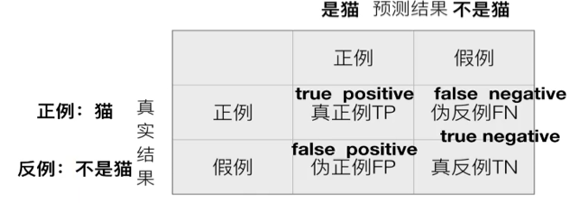 【精确率】
【精确率】