selector:logType
1.获取body中数据
event.getBody():
2.区分类型


selector:logType
1.获取body中数据
event.getBody():
2.区分类型
DWD:判空过滤,维度退化(降维)
每周活跃设备分析:
累计每日活跃用户数并去重
date_add(next_day('2019-02-10','MO'),-7)
强制删表:cascade
函数运用:
collect_set
日期函数:
date_format():
date_add():
next_day():
last_day():当月最后一天
一、自定义UDTF函数使用
lateral view()
二、自定义UDTF函数,需要继承genericUDTF:重写initiallize();process():close()
从JSON对象中取值
脚本:
导入hdfs上的数据到hive表
脚本中需指定数据库mingchen
hive优化:
使用Tez引擎,jians
Tez运行引擎,性能优于Mr,数据传输不落入磁盘
awk:一种处理文本文件的语言
$ awk '{print $1,$4}' log.txt
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
报表系统、用户画像、推荐系统、机器学习、风控系统
ETL拦截器
定义intercept
1.获取数据
byte[] body = event.getBody();
String json = new String(body);
2.校验数据是否合法
定义logUtils类封装校验逻辑
NumberUtils.isDigits()判断是否纯数字
flume:
TAILDIR:支持断点续传
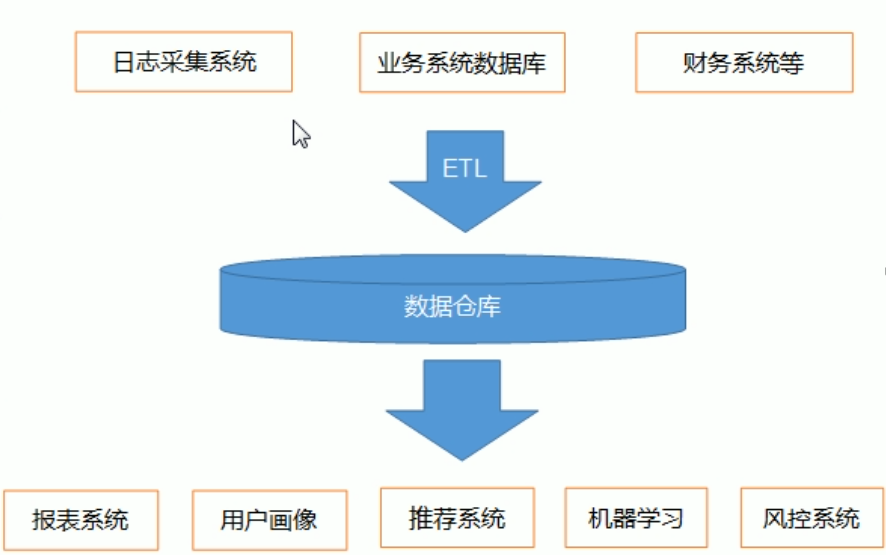
数据仓库,是为企业所有决策制定过程,提供所有系统数据支持的战略集合。
通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本、提高产品质量等。
对数据的处理爆发阔:清洗、转义、分类、重组合并、拆分、统计等
hadoop集群的常见端口号:50070、50090、9000、8088、19888
核心配置文件:core.site
两个必备条件:Java、ssh
断点续传:记录
json格式化解析工具
数据生成:
对字段必须熟悉
埋点用户行为数据:
用户在使用产品过程中,与客户端产品交互过程中产生的数据,比如页面浏览、点击、停留、评论、点赞、收藏等
业务交互数据:
业务流程中产生的登录、订单、用户、商品、支付等相关的数据,通常存储在DB找那个,包括MySQL、orcale等。
Nginx:主要负责负载均衡
flume:
三个组件,两个事务
拦截器
监控器ganglia
flume默认内存1GB,在企业中会调整至4GB左右
