

- 1 贝叶斯, MLE的思想
假设1:p(Ai) 概率相似
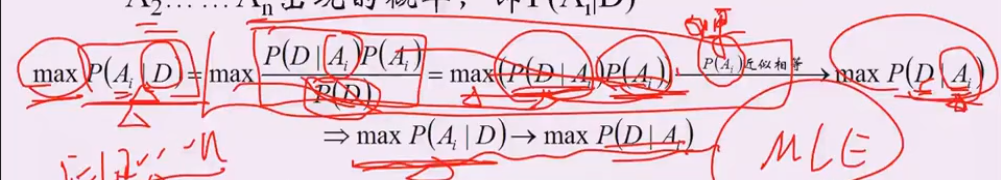
P(D|Ai): 给定结论Ai下, 这个数据以多大的概率产生。 可以理解为x1..xn是未知的数据参数,θi是已知的参数,能够使 p(x1..xn|θi)最大的参数θi,就是我们想要估计的参数, 这里xi对应D,Ai对应参数θ
- 2 赔率分析
公平赔率; y = 1/p y是赔率,p是赢的概率
赔率公式 y =a/p
计算庄家盈亏:

10.5% = 0.21 a / 2a
- 3 模糊查询与替换
2 PCA
2.1 原理
①求协方差矩阵
② 特征值排序
③ 方差最大的就认为是主要的方向,其中特征向量相互垂直,每一个特征向量就是一个方向,Aμi的方差最大,就认为是最主要的投影方向


①假定样本已经作了中心化,所以忽略均值E
Q 为什么特征值最大 等价于 求方差最大?
PCA中希望投影的方差最大,认为得到的信息最多。
目标函数: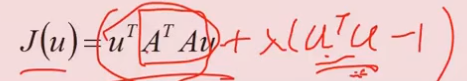
加上等式约束 μTμ=1, 根据拉格朗日求解,
aJ/aμ = 2ATAμ +2λμ = 0 ,求得λ就是 ATA的特征值。
因此,方差最大 等价于 最大特征值
2.2 过拟合问题
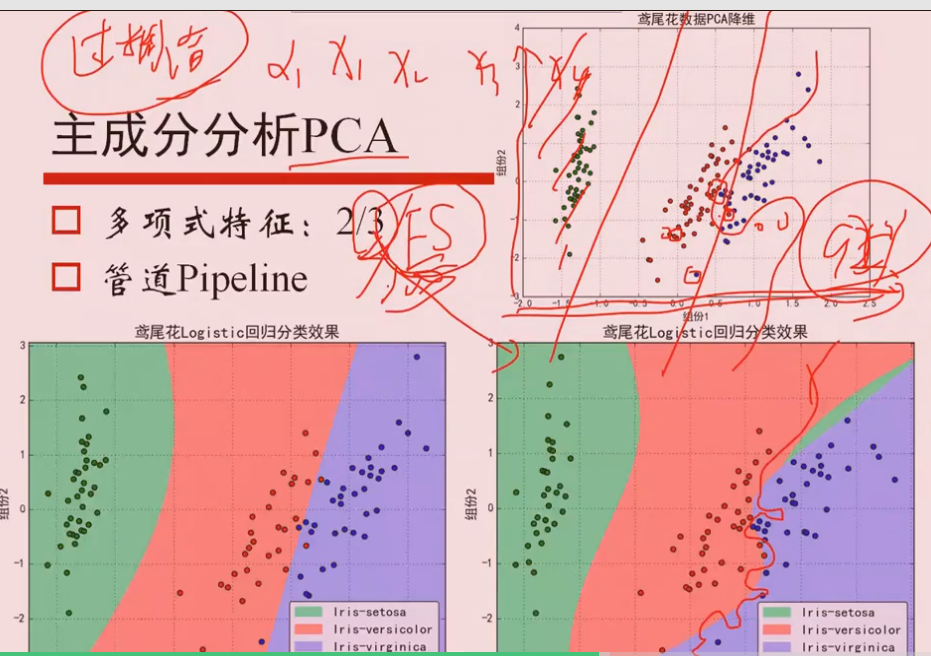
使用高阶的特征x1^2, x2^2...,特征过多,虽然会得到弯曲的曲线进行分离,但是很有可能产生过拟合问题
决策树不需要做one-hot编码
6.1 Prime
计算素数:
fliter(函数, x): 把数字放入x中,结果输出