二维列表

前套循环打印2维列表
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行换行

 已关闭
已关闭
二维列表
前套循环打印2维列表
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行换行
列表的逆序
1、可以用切片[ : : -1]
2、reversed()返回迭代器,时间换空间
>>> a = [20,10,30,40]
>>> c = reversed(a)
>>> c
<list_reverseiterator object at 0x0000000002BCCEB8>
#说明c是个迭代器
>>> list(c)
[40, 30, 10, 20]
#把c转换成列表输出倒序
>>> list(c)
[]
#迭代器只能用一次,迭代器里包含一个指针(如:0x0000000002BCCEB8),从列表尾部向前指,用第一次的时候就已经指到最前了
切片slice操作
[起始偏移量 start:终止偏移量 end[:步长 step]]
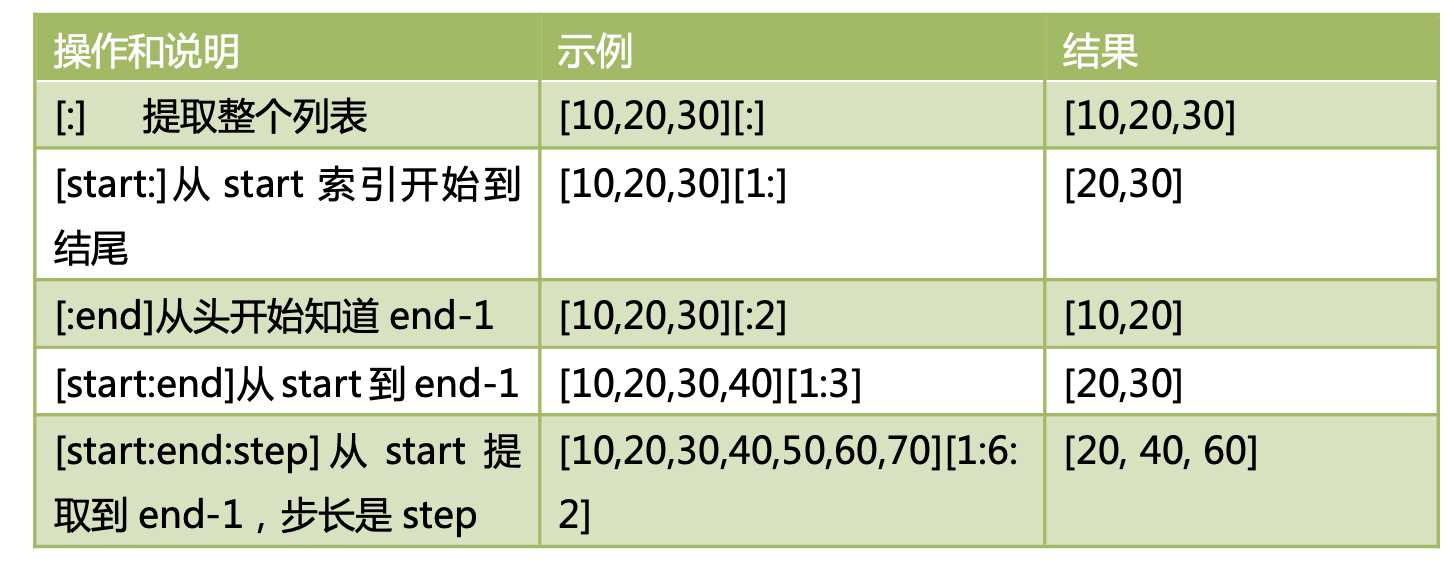
⚠️ end-1(索引)
⚠️如果只有如:[1:3]、[-5:-3],则包头不包尾
⚠️使用负数,反着数
列表的遍历
for obj in listObj:
print(obj)
列表元素访问和计数
1、索引访问
索引区间[0,列表长度-1],超范围会报异常
2、index() 元素在列表中(首次)出现的索引
index(value,[start,[end]])
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.index(20)
1
>>> a.index(20,3) #从索引位置 3 开始往后搜索的第一个 20
5
>>> a.index(30,5,7)
6
3、count() 计数
4、len() 长度=元素个数
5、成员资格判断
in
count() 返回0就不在
列表元素的删除
1、del() 本质是数组拷贝
被删元素后面的依次向前拷贝

2、pop() 方法
删除并返回指定位置元素
3、remove() 方法
删除首次出现的指定元素,若不存在报异常
列表的增加与删除
1、append() 尾部加,推荐
2、+运算,拼接,会产生新列表对象,id变
3、extend() 原地扩展,id不变
4、insert() 插入元素之一,涉及数组移动
5、乘法扩展
列表的创建
可存储任何数据,索引下表获取值
range()创建整数列表
range([start,] end [,step])
start参数:可选,起始
end参数:必选,结尾
step参数:可选,步长
循环创建多个元素
a = [ x*2 for x in range(5)]
>>>a
[0,2,4,6,8]
if过滤元素
a = [ x*2 for x in range(100) if x%9==0]
>>>a
[0,18,36,54,72,.......,198]
python的序列
数据存储方法:字符串、列表、元组、字典、集合
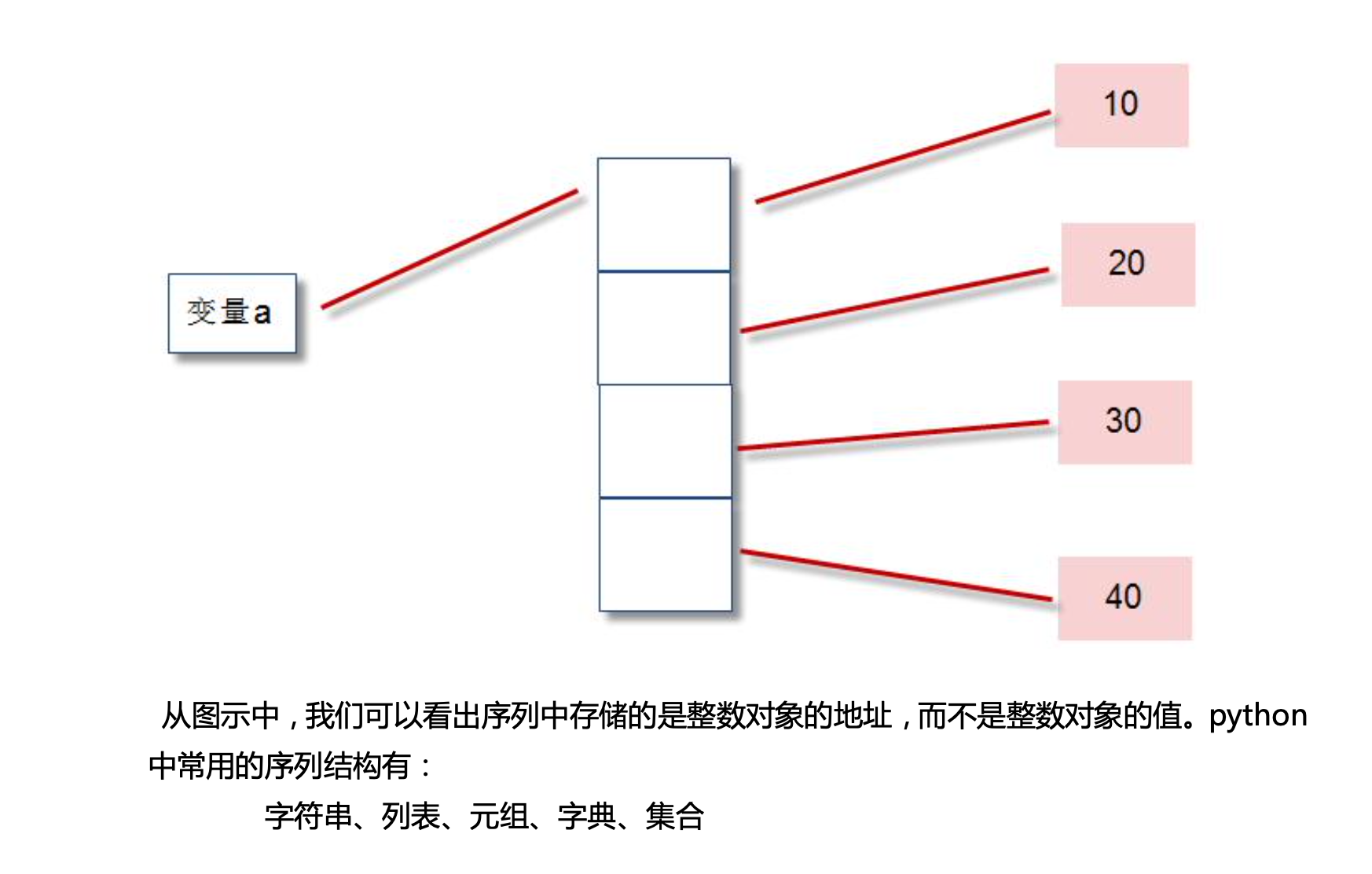
存地址、轻量级
列表大小可变
Python基础课
一、可变字符串
字符串定义以后是不可变的,不能原地修改吗,
思考:对于一组电影数据,如果要对这些数据进行分类,应该如何操作?
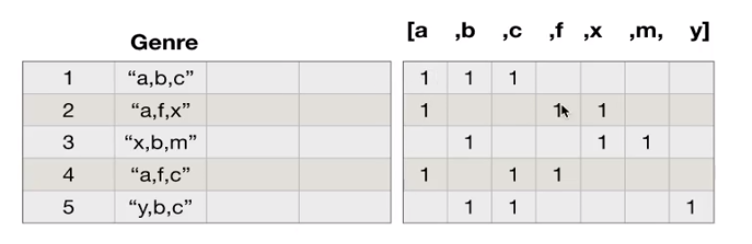
首先,先构一个二维数组,行数等于gener_list的数据量,即取出来genre这一列的数据,通过逗号进行分割,即将每一行数据分割出来一二维数据的形式返回列表中
df["Genre"].str.split(",").tolist()
然后将这个list里面的数据都转换为一维数组且去重
再构建一个新的二维数组,最初的值都为零,行是genre 的数据量,列表是一维数组的数据量,分类最为列索引
8
分解问题
确认坐标系0点
按照思路敲代码
"报错的文字里总有认识的单词”
搜索“CMD"
输入“python”
字符串的方法

pandas里面计算mean()时,可以直接跳过nan,来返回其他值得平均数
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
pandas的索引
DataFrame的基本属性
为什么要学习pandas?
numpy处理数值型数据;pandas用来处理字符串和时间序列等
pandas的常用数据类型
(1)series——一维、带标签的数组
(2)DataFrame——二维数组

生成随机数的方法