选择行,
选择列
选择行列


选择行,
选择列
选择行列
hist 直方图
from matplotlib import pyplot as plt
from matplotlib import font_manager
a=[zifuchuan]
plot.hist(a.fenzushu)
细节
计算组数=num_bin= (max(a)-nim(b)//d)
d=5
组数= 极差/组距
x轴的刻度设置
plt.xticks(range(min(a),max(a)+d,d))
plt.show()
图形大小:plt.figure(figsze=(20,8),dpi=80)
{数据}
数组的形状
shape即可查看数组的各个维度长度(输出按三维二维依次降低,块、行、个)
reshape方法可以重新设置行列,是有返回值的,而不改变本身
有返回值才会输出
结合shape和reshape可以做到在不清楚维度长度的情况下降维
flatten可以将数组展开变成一维
数组的计算
numpy数组对数字进行+*-/计算,是对全部单元进行计算
nan>>not a number 0/0
inf>>infinite x/0
数组对数组进行计算:
不同维度的数组进行计算至少有一个维度的长度相同
广播会在缺失或者长度为1的维度上进行(不同维度的计算本质上是广播)
广播原则:如果两个数组的后缘维度,即从末尾开始算起的维度轴长相符,或者某一方的长度为1,即广播jian'r
一维数组只有0轴,二维有0、1轴,三维有0、1、2轴
reshape(0,1,2),shape输出(2,1,0)
CSV逗号分隔值文件
numpy的读取文件方法
unpack参数实现行列转置
transpose,T,swapaxes(1,0)方法实现行列转置
numpy的索引和切片
索引从0开始
2:取得连续多行,[[2,5,6]]多一个[]取得不连续的行
:,1取得单列
:,1:取得连续列
:,[]取得不连续列
取得行列交叉的内容
取得不相邻的点
这个老师的逻辑能力和语言组织能力真的是匮乏 前言不搭后语 自己把自己绕进去了
讲的真垃圾
这课程讲的就和拿着稿子照本宣科一样
提升:
梯度提升
特征选择:方差过滤
```python
from sklearn.feature_selection import VarianceThreshold #特征选择,根据方差进行过滤
def var():
'''
特征选择-选择低方差的特征
:return:None
'''
var=VarianceThreshold(threshold=1.0)#保留方差值为1的数值
data=var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])#三行四列的二维数组
print(data)
return None
if __name__=='__main__': #调用
var()
```
PCA:主成分分析
把维度降低,但是数据信息尽可能不损耗

文本特征分类功能:
1、文本特征抽取:count
文本分类----如每天的文献分类/文章的分类
2、tf idf:
2.1 tf:term frequency:词的频率 出现的次数(类似count)
2.2 idf:逆文档频率inverse document frequency
log(总文档数量/该词出现的文档数量)
例:log(数值):输入的数值越小,结果越小
tf*idf 重要性
文本特征抽取:Count
功能:
文本分类
情感分析
默认对于单个英文字母或者单词:没有不统计
词组分类器:jie'ba
特征抽取:特征值化
字典数据特征抽取:对字典数据进行特征值化
DictVectorizer语法:
字典数据抽取:将字典中的一些类别数据,分别转换成一些数值。
数组形式:有类别的这些特征,先要转换字典数据
pandas数据处理
:缺失值,数据转换,重复值(不用处理)
sklearn:对特征进行处理
特征值(具体特征:身高/体重)->目标值(具体要达到的目的:如区分男女)
机器学习:使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。(强调学习 而不是专家系统)
有监督
无监督
强化学习(带反馈)
机器学习:数据清洗/特征选择;确定算法模型/参数优化;结果预测
不能解决:大数据存储/并行计算;做一个机器人
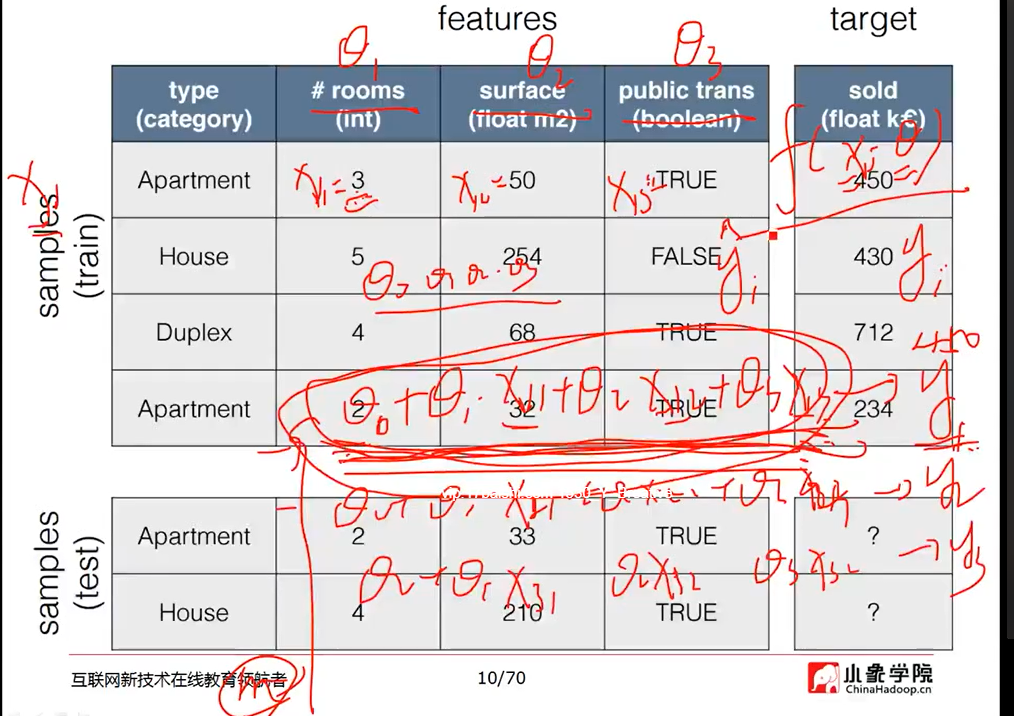
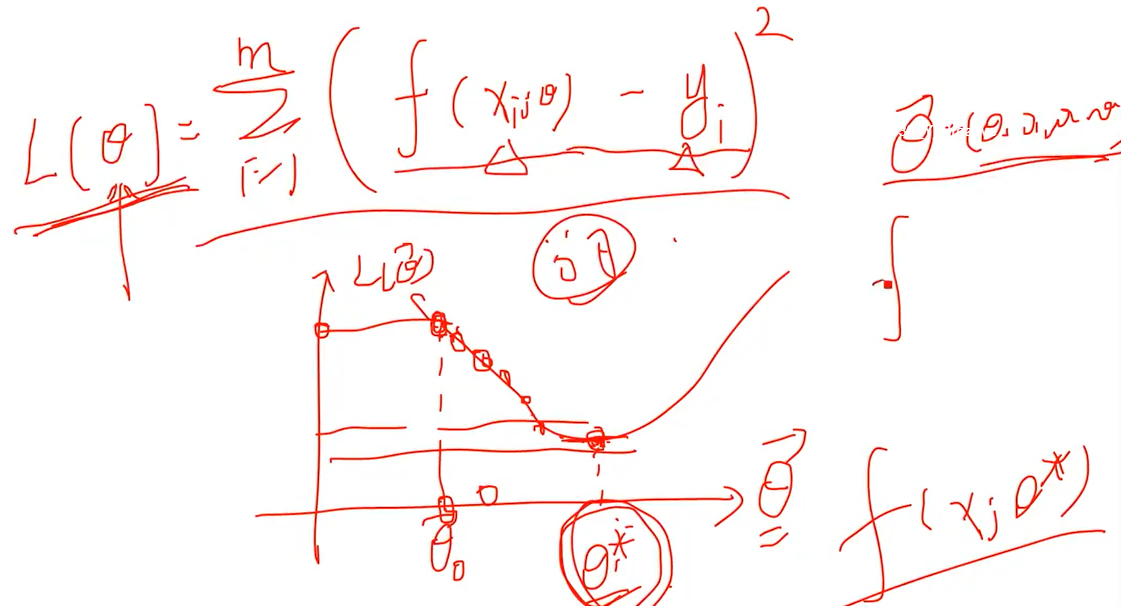
目标函数取最小称 损失函数
数据收集--->数据清洗----->特征工程----->数据建模












hessian矩阵 对称--》4>0 二阶行列式>0----》正定---->凸函数
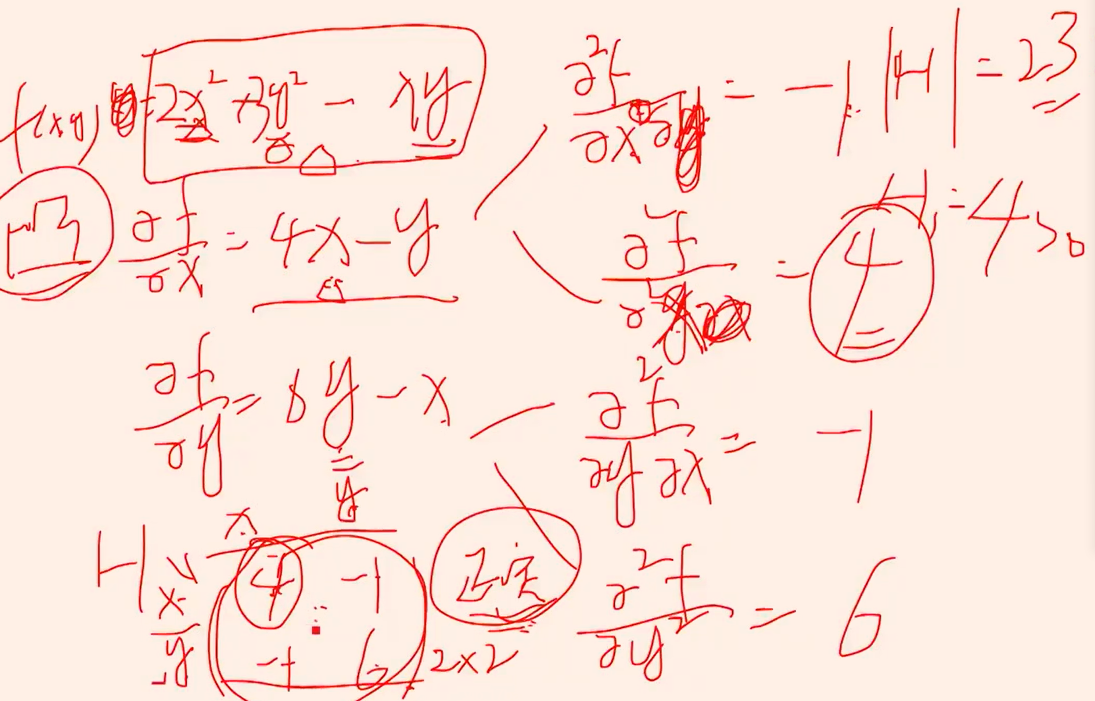
数据预处理
深度学习需要的是标准的正方形图片
(1)image resize
(2)Data Argumentation
(3)Normalize
(4)to tensor
自定义数据集实战
test数据量太小的话,测试结果波动较大,所以我们为了保证测试的效果,会把测试集的数据多分配一些
1、load data ——比较重要的模型;
继承一个通用的母类
inherit from torch.utils.data.Dataset
要定一个两个函数
_len_:数据量
_getitiem_:能够得到指定的样本
2、build model——在我们已经定义好的模型上做一些修改;
3、train and test
4、transfer learning
情感分类实战
Google CoLab
(1)continuous 12 hours;
(2)free K80 for GPU;
(3)不需要爬墙