变量:对对象的引用
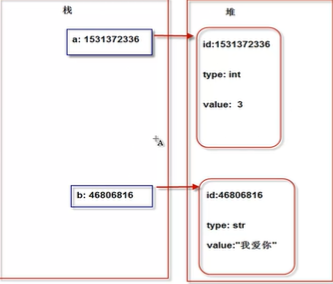


变量:对对象的引用
1. 对象:内存块,类似车位(编号(ID),类型(小汽车,大巴),内容(车牌号))
ID----TYPE----VALUE
\:表示反斜杠符,可以将较长行jie'duan
eg: a="asdfghjklzxcvbnm"
b="asdf\
ghjkl\
zxcvb\
bnm"
1. turtle.forward():表示鼠标前进的距离,()里面zhineng填一个参数(数字)
2. turtle.goto(x,y):表示鼠标运行到的地点,x表示横坐标,y表示纵坐标
3.turtle.penup()和turtle.pendown() 一定要加(),
思路:

turtule:hai'gui
错误的处理方法:(守-破-离)
1. 守:照着老师的做,敬畏的心
2.破:突破老师的一种思路,打破常规,加入思考
3.离:脱离传统模式,开始创新
4.建立体系:过主流的知识点(刚开始),时间有限,不纠结,不事事求完美
5. 问题解决之道:开始的时候,看和老师不一样,之后独立的时候,学会思考,百度,自己解决
传递不可变对象如果发生赋值操作用的是浅拷贝
内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。
深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象
#打印99乘法表
for m in range(1,10):
for n in range(1,10):
if m>=n :
print("{0}*{1}={2}".format(m,n,(m*n)),end="\t")
print() #表示换行
#列表输出的练习
r1= dict(name="高小一",age=18,salary=30000,city="北京")
r2= dict(name="高小二",age=19,salary=20000,city="上海")
r3= dict(name="高小三",age=20,salary=10000,city="深圳")
tb = [r1,r2,r3]
#打印工资大yu15000的人
for x in tb:
if x.get("salary")>15000:
print(x.get("name"))
复习:
字符串“”
列表[]
元组()
字典{}
for比while省去了
字典元素增删改
区分pop和popitem
返回删除值和返回删除键值对
字典元素访问
1、【键】检索
2、get(),键不存在返回None,推荐
3. 列出所有的键值对
>>> a.items()
dict_items([('name', 'gaoqi'), ('age', 18), ('job', 'programmer')])
4. 列出所有的键,列出所有的值
>>> a.keys()
dict_keys(['name', 'age', 'job'])
>>> a.values()
dict_values(['gaoqi', 18, 'programmer'])
5. len() 键值对的个数
6. 检测一个“键”是否在字典中 in
字典
键值对,无序,类似数据库那种感觉
字典中通过“键对象”找到对应的“值对象”。“键”是任意的不可变数据,但是:列表、 字典、集合这些可变对象,不能作为“键”。并且“键”不可重复。“值”可以是任意的数据,并且可重复。
创建方法
1、{} 或 dict()
2、zip()
>>> k = ['name','age','job'] #键
>>> v = ['gaoqi',18,'techer'] #值
>>> d = dict(zip(k,v)) #打包
>>> d
{'name': 'gaoqi', 'age': 18, 'job': 'techer'}
3、fromkey创建值为空(None)的字典
>>> a = dict.fromkeys(['name','age','job']) >>> a
{'name': None, 'age': None, 'job': None}
生成器推导式创建元组
>>> s = (x*2 for x in range(5))
>>> s
<generator object <genexpr> at 0x0000000002BDEB48> #s还是个指针
>>> tuple(s)
(0, 2, 4, 6, 8)
>>> list(s) #只能访问一次元素。第二次就为空了。需要再生成一次 []
>>> s
<generator object <genexpr> at 0x0000000002BDEB48>
>>> tuple(s)
()
>>> s = (x*2 for x in range(5))
>>> s.__next__() #逐步移动指针的方法
0
>>> s.__next__()
2
>>> s.__next__()
4
元组总结:
不可变
访问处理速度快
与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
元组的元素访问和计数
切片
排序:只能使用内置函数 sorted(tupleObj),并生成新的列表对象。
>>> a = (20,10,30,9,8)
>>> sorted(a)
[8, 9, 10, 20, 30]
zip(打包)
zip(列表 1,列表 2,...)将多个列表对应位置的元素组合成为元组,并返回这个 zip 对象。 >>> a = [10,20,30]
>>> b = [40,50,60]
>>> c = [70,80,90]
>>> d = zip(a,b,c)
>>> list(d)
[(10, 40, 70), (20, 50, 80), (30, 60, 90)]
元组 tuple
不可变序列,没有增删改操作
关键在于访问、计数
创建元组
1、()
a = (10,20,30) or a = 10,20,30
b = 10,
2 、tuple()
b = tuple() #创建一个空元组对象
b = tuple("abc")
b = tuple(range(3)) b = tuple([2,3,4])
【区分】
tuple()可以接收列表、字符串、其他序列类型、迭代器等生成元组。
list()可以接收元组、字符串、其他序列类型、迭代器等生成列表。
二维列表

前套循环打印2维列表
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print() #打印完一行换行
列表的逆序
1、可以用切片[ : : -1]
2、reversed()返回迭代器,时间换空间
>>> a = [20,10,30,40]
>>> c = reversed(a)
>>> c
<list_reverseiterator object at 0x0000000002BCCEB8>
#说明c是个迭代器
>>> list(c)
[40, 30, 10, 20]
#把c转换成列表输出倒序
>>> list(c)
[]
#迭代器只能用一次,迭代器里包含一个指针(如:0x0000000002BCCEB8),从列表尾部向前指,用第一次的时候就已经指到最前了
切片slice操作
[起始偏移量 start:终止偏移量 end[:步长 step]]
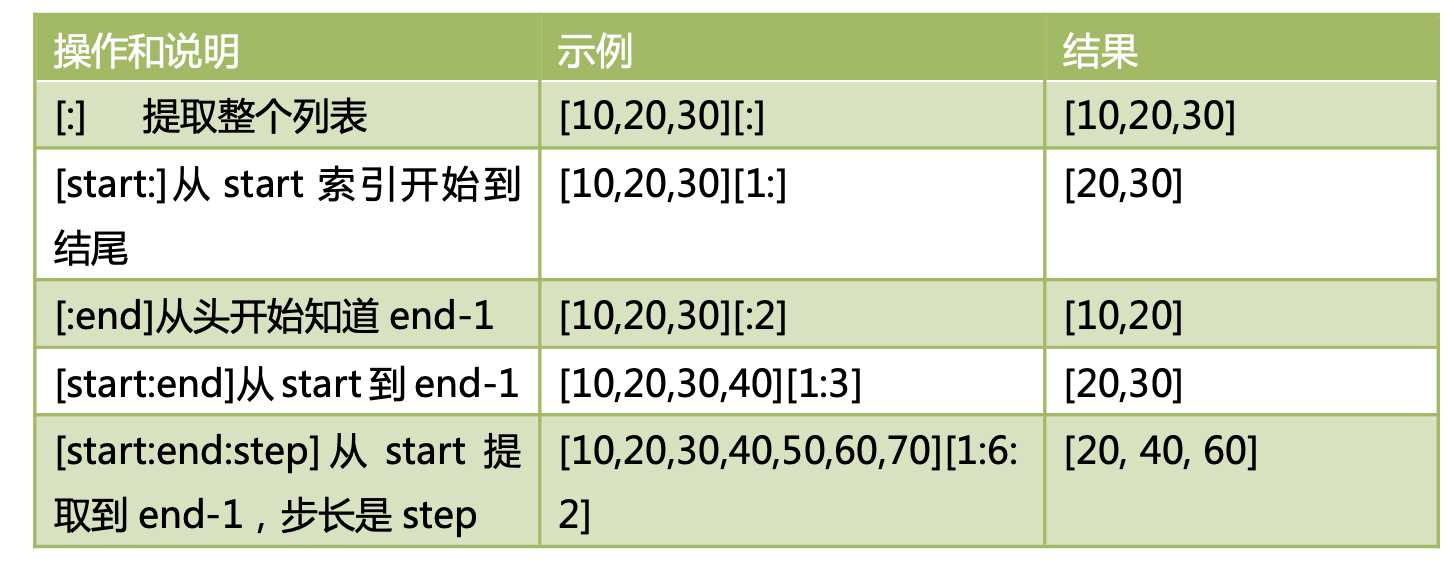
⚠️ end-1(索引)
⚠️如果只有如:[1:3]、[-5:-3],则包头不包尾
⚠️使用负数,反着数
列表的遍历
for obj in listObj:
print(obj)
列表元素访问和计数
1、索引访问
索引区间[0,列表长度-1],超范围会报异常
2、index() 元素在列表中(首次)出现的索引
index(value,[start,[end]])
>>> a = [10,20,30,40,50,20,30,20,30]
>>> a.index(20)
1
>>> a.index(20,3) #从索引位置 3 开始往后搜索的第一个 20
5
>>> a.index(30,5,7)
6
3、count() 计数
4、len() 长度=元素个数
5、成员资格判断
in
count() 返回0就不在