包头不包尾


包头不包尾
_eq()_ 比较对象值
python是非常适合做超大数的计算,而不会造成“整数溢出”,这也是pytthon特别适合科学运算的特点
1、整型
数字:加法,减法,乘法,浮点数除法,整数除法,模(取余),幂
2、浮点型
3、布尔型
4、字符串型
内置的数据类型
divmod(13,3)
python里面,是不支持常量的
堆与栈的本质,需要与java一起理解
python是动态类型语言
变量不需要显式声明类型,根据变量引用的对象,python解释器自动确定数据类型
每个对象,都是有类型的,只支持该类型支持的操作
1、ctrl +s 保存代码
2、“四个空格”表示一个缩进
目前,常用的编辑器一般设置成:tab制表符就是4个空格
写注释的习惯
python官方,有写代码的风格
开发环境,英文是IDE
Integrated Development Environment 集成开发环境
核心内容,都是python.exe的解释器
1、对于初学者,不要纠结是哪个开发环境,只要心理平静,都可以做到消化吸引
2、不同的IDE核心,都是Python.exe的解释器
IDIE
Pycharm
wingIDE
Eclipse
IPython
Python是一种解释型,面向对象的语言。
随着人工智能越来越热,python越来越热
python的特点:
1、可读性强:
2、简洁、简洁、简洁
研究证明,程序号每天可编写的有效代码数是有限的。完成同样功能能只用一半的代码,其实就是提高了一倍的生产率。
Python是由C语言开发,但是不再有C语言中指针等复杂数据类型,
Python的简洁性让开发难度和代码幅度降低,开发任务大大简化。程序号再也不需要关注复杂的语法,而是关注任务本身
程序员再也不需要关注复杂的语法,而是关注任务本身
1、java
编大多数的高级语音,是面向对象的
java与python都是跨平台的语言
python会被编译成与操作系统相关的二进制代码,然后再解释执行。这种方式和java类似,大大提高了执行速度,也实现了跨平台
java虚拟机,也是可以编译成与操作系统相关的二进制代码
6.丰富的库(丰富的标准库,多种多样的扩展库)
7.可扩展性。可嵌入到C到C++语言,
怎么理解为胶水式语言呢????
python是怎么与C整合呢
什么时候不应该用Python
1、Python解释执行,性能较低
Python版本与兼容问题解决方案
Python3:
2008年发布。Python3有个较大的提升,不兼容Python2.
所以学习从Python3开始,才是未来的主流。
使用C语言的解释器,效率最高。
goto(x,y)
circle( r )
penup()
pendown()
foward(distance)
left(angle)
开发环境:IDLE、pycharm……

官方:www.python.org
- 线性回归需要标准化
决策树的分类依据之一
信息增益
【分类模型的评估标准】
【准确率】
estimator.score():一般最常见使用的是准确率,及预测结果正确的百分比
【混淆矩阵】
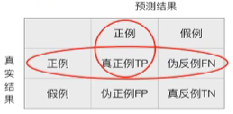
在分类任务下,预测结果和正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多酚类)
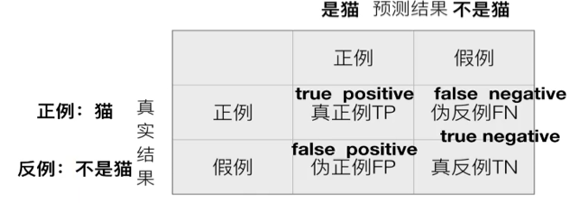 【精确率】
【精确率】
预测结果为正例的样本中,真实为正例的比例(查得准)

【召回率】
真实为正例的样本中,预测结果为正例的比例(查的全,对正样本的区分能力)
【分类模型评估API】
sklearn.metrics.classification_report (y_true, y_predict, target_names = None)
- y_true:真实目标值
- y_predict:估计器预测目标值
- target_names:目标类别名称
- return:每个类别精确率与召回率
朴素贝叶斯案例流程
1. 加载新闻数据,并进行分割
2. 生成文章特征词
3. 朴素贝叶斯流程进行预估
K近邻算法:相似的样本,特征之间的值应该都是相近的
k近邻算法:需要做标准化处理
【转换器】
fit_transform():输入数据并直接转换
fit():输入数据,但不做其他事
transform():进行数据的转换
【估计器】是一类实现了算法的API
1. 用于分类的估计器:
-- sklearn.neighbors
-- sklearn.naive_bayes
-- sklearn.linear_model.LogiscRegression
-- sklearn.tree
2. 用于回归的估计器
-- sklearn.linear_model.LinearRegression
-- sklearn.linear_model.Ridge
估计器流程
1、调用训练集:fit(x_train, y_train)
2、输入待预测的测试集数据:
2.1、y_predict = predict( x_test)
2.2、验证预测的准确率:score( x_test, y_test)