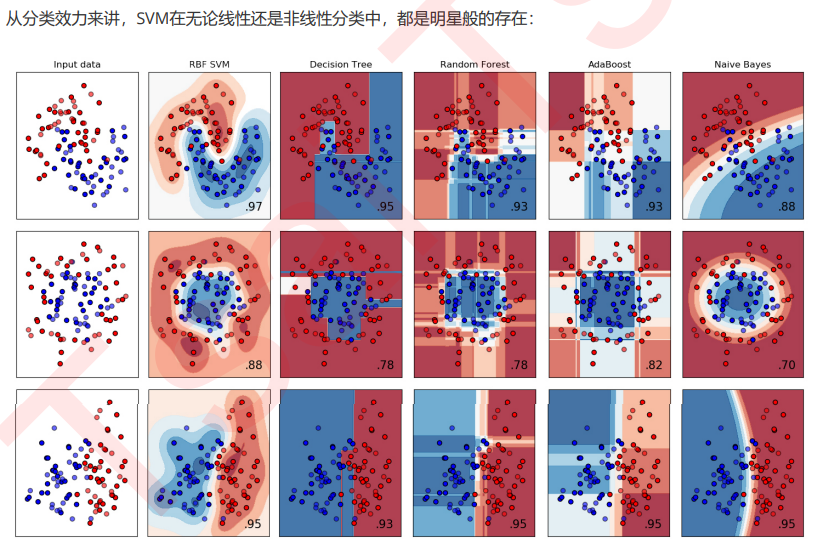
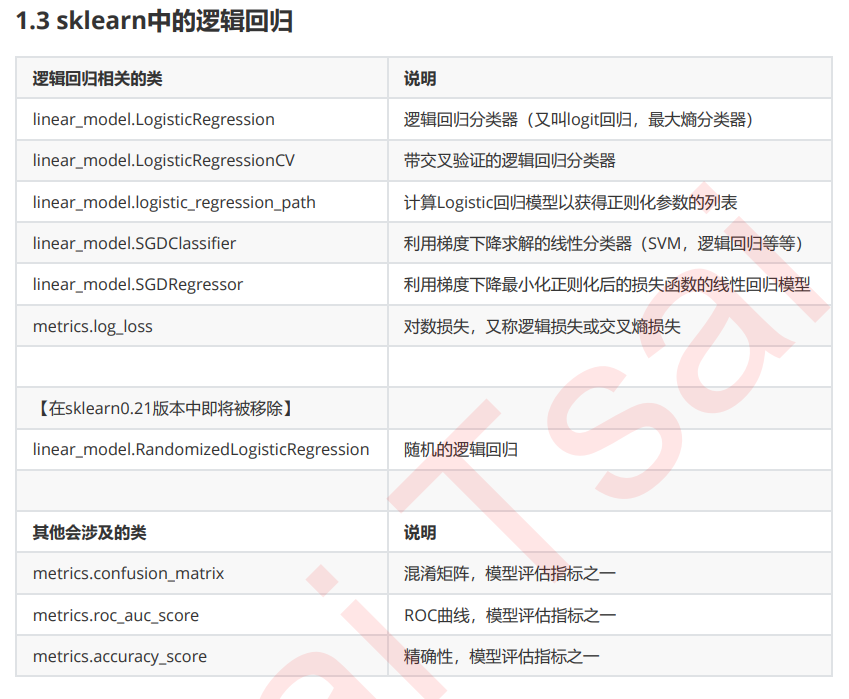
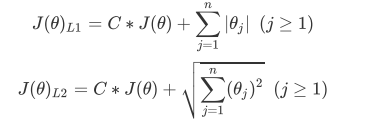数组的形状
shape即可查看数组的各个维度长度(输出按三维二维依次降低,块、行、个)
reshape方法可以重新设置行列,是有返回值的,而不改变本身
有返回值才会输出
结合shape和reshape可以做到在不清楚维度长度的情况下降维
flatten可以将数组展开变成一维
数组的计算
numpy数组对数字进行+*-/计算,是对全部单元进行计算
nan>>not a number 0/0
inf>>infinite x/0
数组对数组进行计算:
不同维度的数组进行计算至少有一个维度的长度相同
广播会在缺失或者长度为1的维度上进行(不同维度的计算本质上是广播)
广播原则:如果两个数组的后缘维度,即从末尾开始算起的维度轴长相符,或者某一方的长度为1,即广播jian'r