数据分析的介绍
- 为什么学习数据分析:Python数据科学的基础与机器学习课程的基础。
- 数据分析师用适当的方法对手机的大量数据进行分析,帮助人们做出判断,以便采取适当行动。
- 数据分析流程:提出问题、准备数据(数据清洗或预处理)、分析数据、获得结论、成果可视化。


数据分析的介绍
切片和索引
1.选择行 t【2】
2.选择列t【3:,:】
3.选择行列 连续的多行 t[2:,:3]
4.索引 t【2,3】
### numpy中的nan和inf
1.当本地文件为float的时候,有缺失时,会出现nan
或者做义工不适合的计算时
2.inf表示正无穷,-inf是负无穷
### numpy常用统计函数
1.求和:np.sum(t3,axis=0)是计算行上的结果
(axis=1是计算列上的结果)
2.均值:np.mean(t,axis=0)
3.中值:np.median(t3,axis=0)
4.最大值:np.max(axis=0)
5.最小值:np.min(axis=0)
6.极值:np.ptp(t3,axis=0)
7.标准差:np.std(axis=0)
标准差反应数据的波动情况,越大则越分散
## numpy好用的方法
1.获得最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t.axis=1)
2.创建一个全为0的数组:np.zeros((3,4))
3.创建一个全为1的数组:np.ones((3,4))
4.创建一个对角线为1的正方形数组(方阵):
np,eye(3)
## numpy生成随机数
##数组的拼接
#竖直拼接
np.vstack((t1,t2))
#水平拼接
np.hstack((t1,t2))
#行交换
t[[1,2],:]=t[[2,1],:]
#列交换
t[:,[0,2]]=t[:,[2,0]]
np.where(t<10,0,10)#numpy三元运算符
如果t<10,则为0,否则为10
np.clip(10,18)#numpy的裁剪
关键字,不能作为变量名,使用help()查看关键字,变量以字母或者下划线开头,后接字母下划线数字
## numpy读取本地数据
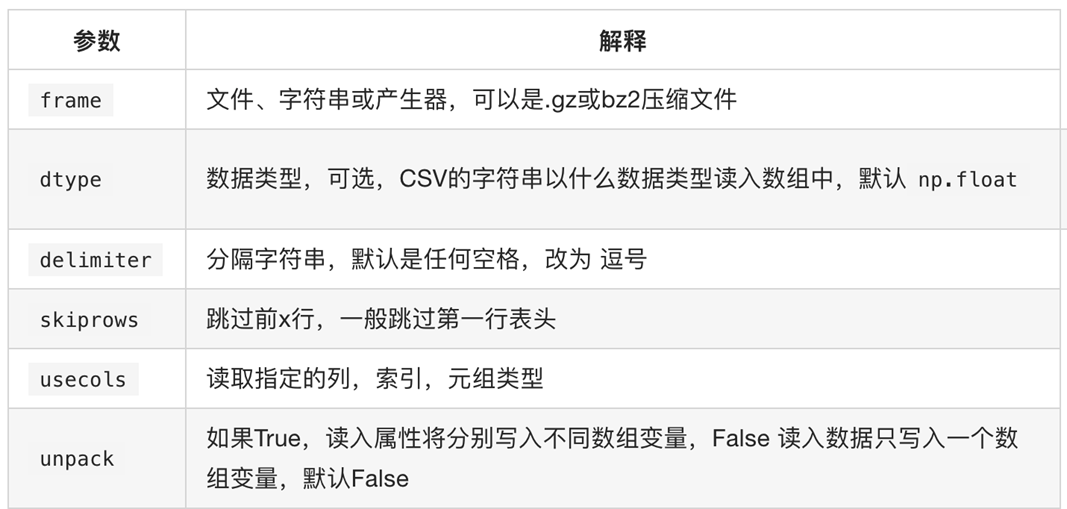
numpy读取数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
###数组的计算
np.shape()只有一个值是一维的,指的是有多少个元素
两个值,二维,指几行几列
三个值,三维
np.reshape((3,4))把什么变成三行四列形式
```python
import numpy as np t1=np.arange(32).reshape((2,4,4)) print(t1)
```
t1.flatten()可以快速把数据按顺序变成二维的
1.广播机制:数组与数字直接运算
2.特例:t1/0 :0/0=nan,数字/0=inf
3.数组与数组计算,长度相同时,按维度依次计算
## numpy学习(处理数字性数据)
1.np.array()把内容变成数组
2.t1.dtype可以显示其类型
3.np.astype可以把类型改变
4.保存固定位的小数
np.round(range(10),3)
### 总结四种方法
matplotlib.plot()折线图
matplotlib.bar 条形图
matplotlib.scatter 散点图
matplotlib.hist 直方图
更多绘图软件:Aoache ECharts
#### 绘制直方图
组数=极差/组距
#### 条形图
plt.bar 竖着的条形图,线条粗细是width(线条的宽度)
plt.barh 横着的条形图,线条粗细成了height(线条的高低)
plt.grid 是添加网格,alpha是透明度
回归>>>均方误差MSE
#### 散点图是plt.scatter
遗忘知识点:
plt.legend(loc="uppper left",prop=my_font)
###
plt.grid绘制网格
plt.grid(alpha=0.5)#alpha这个代表透明度
plt.plot(linestyle=':')表示折线变成虚线
color=''#线条颜色
linestyle=''#折线的形式
linewidth=5#线条粗细
alpha=0.5#透明度
以上都是放在plt.plot中的
随机森林>>>分类器比较好用吗?
random_state是不同的特征作为初始的节点来产生的不同的树,所以需要不同的特征
袋装法,有放回的随机抽样技术
n个样本组成的自助集
bootstrap>>默认为True
袋外数据(out of bag data,简写为oob)
criterion 不纯度的衡量指标
有基尼系数和信息熵,信息熵的增益
n_estimators 这是森林中树木的数量,基评估器的数量,default-10
实例化-交叉验证
波动本质上是一样的, 但集成算法压倒性的强
集成算法
调参曲线,交叉验证,网格算法 调参方法
base estimator 基评估器
boosting 结合弱评估器一次次对难以评估的对象进行攻克
对特征提问得出决策规则-决策树
# 函数rotation=90旋转的度数