特征选择feature_selection

特征创造是一个中很好的方法
在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!
所以特征选择的第一步,其实是根据我们的目标,用业务常识来选择特征。
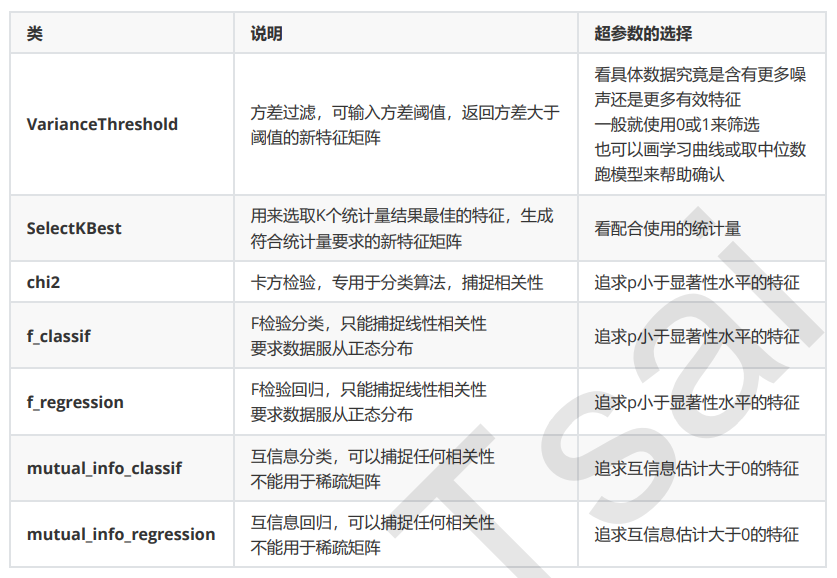
一、方差过滤
可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无 论接下来的特征工程要做什么,都要优先消除方差为0的特征。
当特征是二分类时,特征的取值就是伯努利随机变量,这些变量的方差可以计算为:
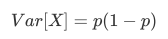
其中X是特征矩阵,p是二分类特征中的一类在这个特征中所占的概率。