.index_select(0, [0, 2])


.index_select(0, [0, 2])
torch.tensor([2., 3.2])
torch.FloatTensor(2, 3)
Unintialized: 未初始化的tensor
增强学习一般用 DoubleTensor
字典元素添加、修改、删除
1.给字典新增“键值对”。如果“键”存在,则覆盖旧的键值对;如果“键”不存在,则新增“键值对”。
2.使用update()将新字典所有键值对全部添加到旧字典对象上。如果key有重复,则直接覆盖。
3.字典中元素的删除,可以使用del()方法;或clear()删除所有键值对;pop()指定键值对,并返回对应的“值对象”;
4.popitem():随机删除和返回改键值对。
字典元素的访问
1.通过【键】获得“值”。若键不存在,则抛出异常。
2.通过get()方法获得“值”。推荐使用。有点是:指定键不存在,返回None;也可以设定指定键不存在时默认返回的对象。推荐使用get()获取“值对象”。
3.列出所有的键值对
4.列出所有的键,列出所有的值
5.len()键值对的个数
6.检测一个“键”是否在字典中
字典的创建
1..通过{}、dict()来创建字典对象。
2.通过zip()创建字典对象
3.通过fromkeys创建值为空的字典
几何概率:与构成事件的长、面积、体积 成比例;
几何概率特点:基本事件 的无限性(抽象)、等可能性;
古典概型特点:基本事件 的有限性(具象)、等可能性;
元祖总结
1.元祖的核心:不可变序列
2.元祖的访问速度和处理速度比列表快
3.与整数和字符串一样,元祖可以作为字典的
元祖tuple
列表属于可变序列,可以任意修改列表中的元素。元祖属于不可变序列,不能修改元祖中的元素。因此,元祖没有增加元素,删除元素,修改元素相关的方法。
因此,我们只需要学习元祖的创建和删除,元祖中元素的访问和计数即可。元祖支持如下操作:
1.索引访问
2.切片操作
3.连接操作
4.成员关系操作
5.比较运算操作
6.计数:元祖长度len()、最大值min()、最小值min()、求和sum()等。
元祖的创建
1.通过()创建元祖。小括号可以忽略
2.通过tuple()创建元祖
t = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
切片操作
通过索引直接访问元素
我们可以通过索引直接访问元素。索引的区间在【0,列表长度-1】这个范围。超过这个范围则会抛出异常。
index()获得指定元素在列表中首次出现的索引count()获得指定元素在列表中出现的次数
len()返回列表长度
删除:
del删除
pop()方法
remove()方法
列表元素的增加和删除
append()方法
+运算符操作
extend()方法
insert()插入元素
乘法扩展
序列
是一种数据存储方式,用来存储一系列的数据。在内存中,序列就是一块用来存放多个值的连续的内存空间。
基本运算符


运算符的优先级
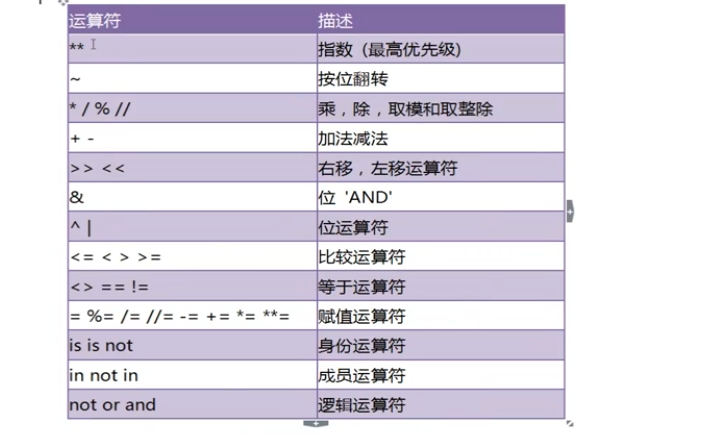
实际使用中,记住如下简单的规则即可,复杂的表达式一定要使用小括号组织。
1.乘除优先加减
2.位运算和算术运算>比较运算符>赋值运算符>逻辑运算符
可变字符串
可以使用io。stringI()对象或array模块。
format()基本用法
新增一个格式化字符串的函数str.format()
基本语法是通过{}和:来代替以前的%
spilt()可以基于指定分隔符将字符串分割成多个子字符串(存储到列表中)。如果不指定分割符,则默认使用空白字符(换行符/空格符/制表符)。
join()的作用和spilt()作用刚好相反,用于将一系列字符串连接