循环结构
while循环


循环结构
while循环
选择结构嵌套
一定要控制好不同级别代码块的缩进量。
多分支选择结构
双分支选择结构
三元条件运算符
条件为真时的值 if (条件表达式) else 条件为假时的值
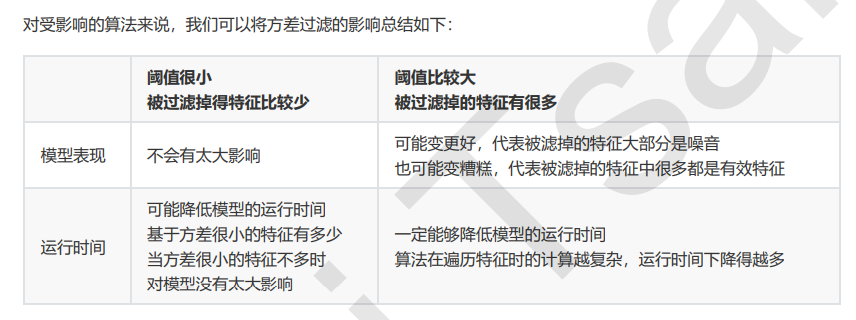
选取超参数threshold
我们怎样知道,方差过滤掉的到底时噪音还是有效特征呢?过滤后模型到底会变好还是会变坏呢?答案是:每个数据集不一样,只能自己去尝试。这里的方差阈值,其实相当于是一个超参数,要选定最优的超参数,我们可以画学 习曲线,找模型效果最好的点。但现实中,我们往往不会这样去做,因为这样会耗费大量的时间。我们只会使用阈值为0或者阈值很小的方差过滤,来为我们优先消除一些明显用不到的特征,然后我们会选择更优的特征选择方法 继续削减特征数量。
方差挑选完毕之后,我们就要考虑下一个问题:相关性了。我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会给模型带来噪 音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负 特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合feature_selection.SelectKBest 这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目 的无关的特征。
如果卡方检验检测到某个特征中所有的值都相同,会提示我们使用方差先进行方差过滤。并且,刚才我们已 经验证过,当我们使用方差过滤筛选掉一半的特征后,模型的表现时提升的。因此在这里,我们使用threshold=中 位数时完成的方差过滤的数据来做卡方检验。
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和 P值两个统计量,其中卡方值很难界定有效的范围,而p值,我们一般使用0.01或0.05作为显著性水平,即p值判断 的边界,具体我们可以这样来看:
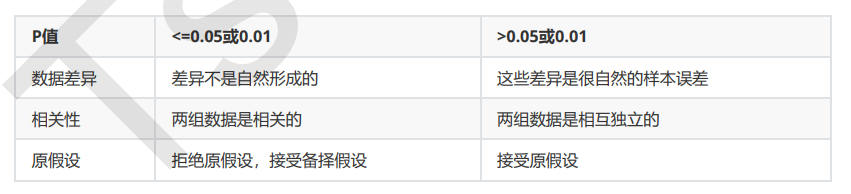
特征选择feature_selection

特征创造是一个中很好的方法
在做特征选择之前,有三件非常重要的事:跟数据提供者开会!跟数据提供者开会!跟数据提供者开会!
所以特征选择的第一步,其实是根据我们的目标,用业务常识来选择特征。
一、方差过滤
可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有什么作用。所以无 论接下来的特征工程要做什么,都要优先消除方差为0的特征。
当特征是二分类时,特征的取值就是伯努利随机变量,这些变量的方差可以计算为:
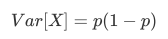
其中X是特征矩阵,p是二分类特征中的一类在这个特征中所占的概率。
包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如 coef_属性或feature_importances_属性来完成特征选择。但不同的是,我们往往使用一个目标函数作为黑盒来帮 助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。包装法在初始特征集上训练评估器,并且通过 coef_属性或通过feature_importances_属性获得每个特征的重要性。然后,从当前的一组特征中修剪最不重要的 特征。在修剪的集合上递归地重复该过程,直到最终到达所需数量的要选择的特征。区别于过滤法和嵌入法的一次 训练解决所有问题,包装法要使用特征子集进行多次训练,因此它所需要的计算成本是最高的。
最典型的目标函数是递归特征消除法(Recursive feature elimination, 简写为RFE)。它是一种贪婪的优化算法, 旨在找到性能最佳的特征子集。 它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,下一次迭代时, 它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。然后,它根据自己保留或 剔除特征的顺序来对特征进行排名,最终选出一个最佳子集。包装法的效果是所有特征选择方法中最利于提升模型 表现的,它可以使用很少的特征达到很优秀的效果。
feature_selection.SelectFromModel

选择结构
单分支选择结构
条件表达式详解
在选择和循环结构中,条件表达式的值为False的情况如下:
False、0、0.0、空值None、空序列对象
Embedded嵌入法
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行。在使用嵌入法时,我们先使 用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小选择特征。这些权值系数往往代表了特征对于模型的某种贡献或某种重要性,比如决策树和树的集成模型中的feature_importances_属性,可以列出各个特征对树的建立的贡献,我们就可以基于这种贡献的评估,找出对模型建立最有用的特征。
过滤法中使用的统计量可以使用统计知识和常识来查找范围(如p值应当低于显著性水平0.05),而嵌入法中使用 的权值系数却没有这样的范围可找——我们可以说,权值系数为0的特征对模型丝毫没有作用,但当大量特征都对 模型有贡献且贡献不一时,我们就很难去界定一个有效的临界值。
嵌入法引入了算法来挑选特征,因此其计算速度也会和应用的算法有很大的关系。如果采用计算量很大,计 算缓慢的算法,嵌入法本身也会非常耗时耗力。并且,在选择完毕之后,我们还是需要自己来评估模型。
先使用方差过滤,然后 使用互信息法来捕捉相关性,不过了解各种各样的过滤方式也是必要的。
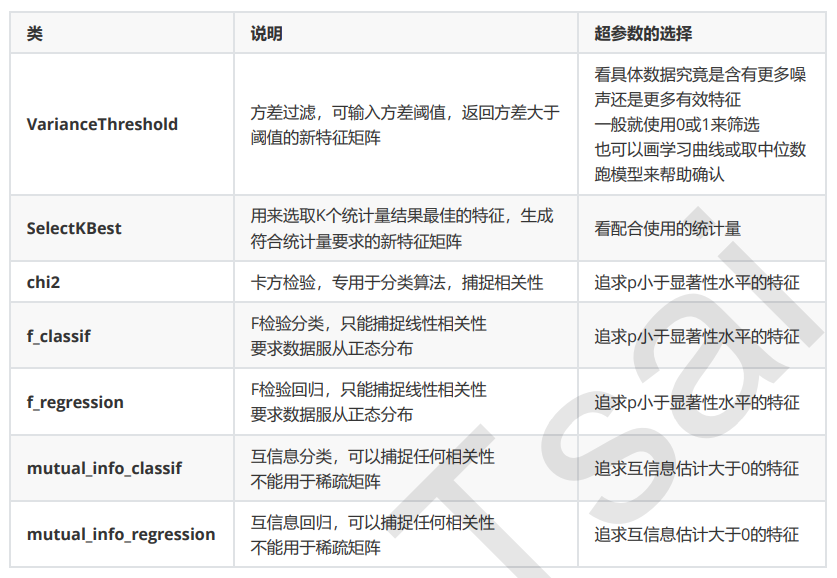
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既 可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和 feature_selection.mutual_info_regression(互信息回归)。这两个类的用法和参数都和F检验一模一样,不过 互信息法比F检验更加强大,F检验只能够找出线性关系,而互信息法可以找出任意关系。
集合:无序可变,集合底层是字典实现,集合的所有元素都是字典中的”键对象“,因此是不能重复且唯一的。
集合创建和删除
1.{}创建
2.set()创建
3.remove()、clear()
集合相关操作
字典核心底层原理(重要)
列表通过索引值寻找,字典通过键寻找。
字典对象的核心是散列表。散列表是一个稀疏数组,数组的每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用。
(1)将一个键值对放进字典的底层过程
序列解包
序列解包可以用于元组、列表、字典。序列解包可以方便对多个变量进行赋值。
字典元素添加、修改、删除
1.给字典新增键值对,如果键已经存在则被覆盖,若键不存在则增加。
2.使用update()将新字典中所有键值对全部添加到旧字典上,如果键重复则进行覆盖。
3.字典中元素的删除,可以使用del()方法,或者clear()删除所有键值对;pop()删除指定键值对,并返回对应的值对象。
4.popitem():随机删除和返回键值对,字典是无序可变序列,因此没有元素的排序顺序等;popitem弹出随机的项。
字典元素的访问
(1)通过【键】获得“值”
(2)通过get()方法获得值(推荐使用)
字典
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:"键对象"和“值对象”。可以通过“键对象”实现快速获取,删除,更新对应的“值对象”。“键”不可重复。
字典的创建
(1)通过{},dict()函数创建字典。
(2)zip()
(3)通过fromkeys创建值为空的字典
生成器推导式创建元组
生成器推导式生成的不是列表也不是元组,而是一个生成器对象。
元组的元素访问和计数
元组排序
zip():将多个列表对应位置的元素组合成为元组,并返回这个zip对象。