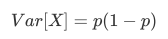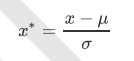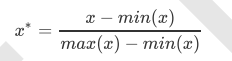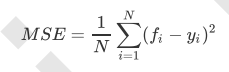随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决 原则来决定集成评估器的结果。在刚才的红酒例子中,我们建立了25棵树,对任何一个样本而言,平均或多数表决 原则下,当且仅当有13棵以上的树判断错误的时候,随机森林才会判断错误。单独一棵决策树对红酒数据集的分类 准确率在0.85上下浮动,假设一棵树判断错误的可能性为0.2(ε)。所以,当一共有25棵树时,判断错误的可能性为:
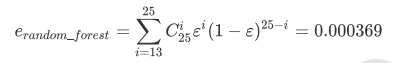
可见,判断错误的几率非常小,这让随机森林在红酒数据集上的表现远远好于单棵决策树。
随机森林中其实也有random_state,用法和分类树中相似,只不过在分类树中,一个random_state只控制生成一 棵树,而随机森林中的random_state控制的是生成森林的模式,而非让一个森林中只有一棵树。
当random_state固定时,随机森林中生成是一组固定的树,但每棵树依然是不一致的,这是 用”随机挑选特征进行分枝“的方法得到的随机性。并且我们可以证明,当这种随机性越大的时候,袋装法的效果一 般会越来越好。用袋装法集成时,基分类器应当是相互独立的,是不相同的。
bootstrap & oob_score
要让基分类器尽量都不一样,一种很容易理解的方法是使用不同的训练集来进行训练,而袋装法正是通过有放回的随机抽样技术来形成不同的训练数据,bootstrap就是用来控制抽样技术的参数。
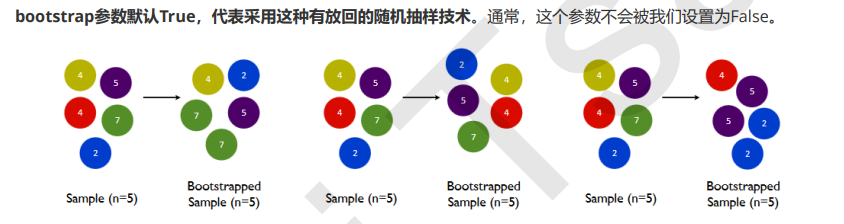
一般来说,自助集大约平均会包含63%的原始数据。因为每一个样本被抽到某个自助集中的概率为:
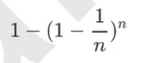
当n足够大时,这个概率收敛于1-(1/e),约等于0.632。因此,会有约37%的训练数据被浪费掉,没有参与建模, 这些数据被称为袋外数据(out of bag data,简写为oob)。
也就是说,在使用随机森林时,我们可以不划分测试集和训练集,只需要用袋外 数据来测试我们的模型即可。
重要属性和接口