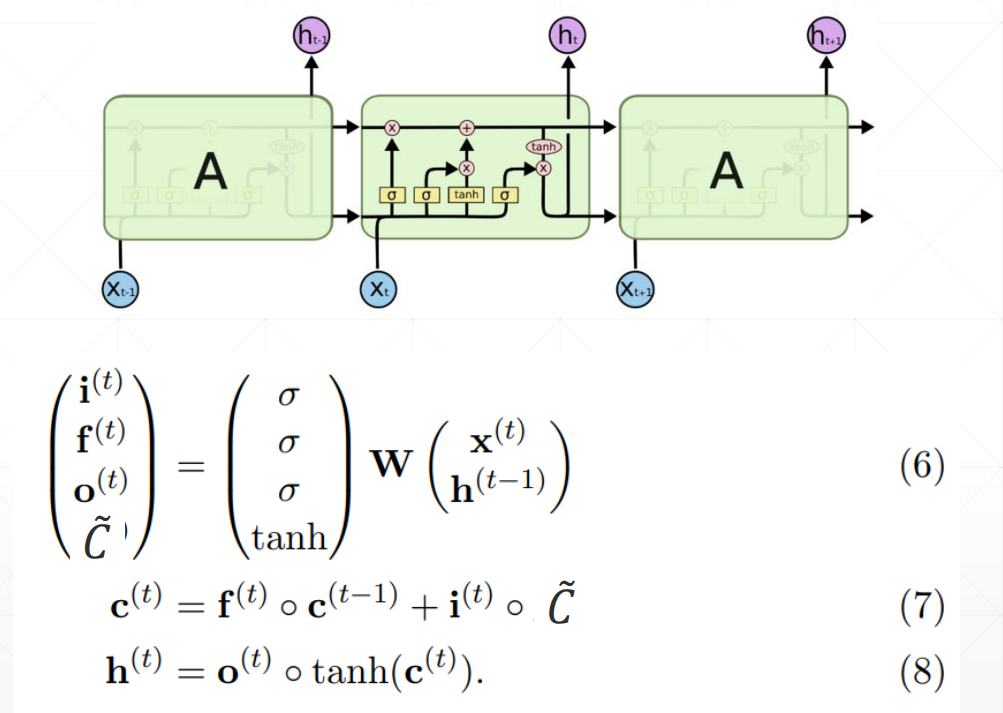
2、输入门
it作为一个开度,将多少信息传入到下一个时间点,有算法决定这个开度;新信息同样也是由ht-1和当前点的xt共同决定的。it是对当前信息的过滤系数,当前信息与开度相乘之后就是经过过滤后输入下一个点的新信息。
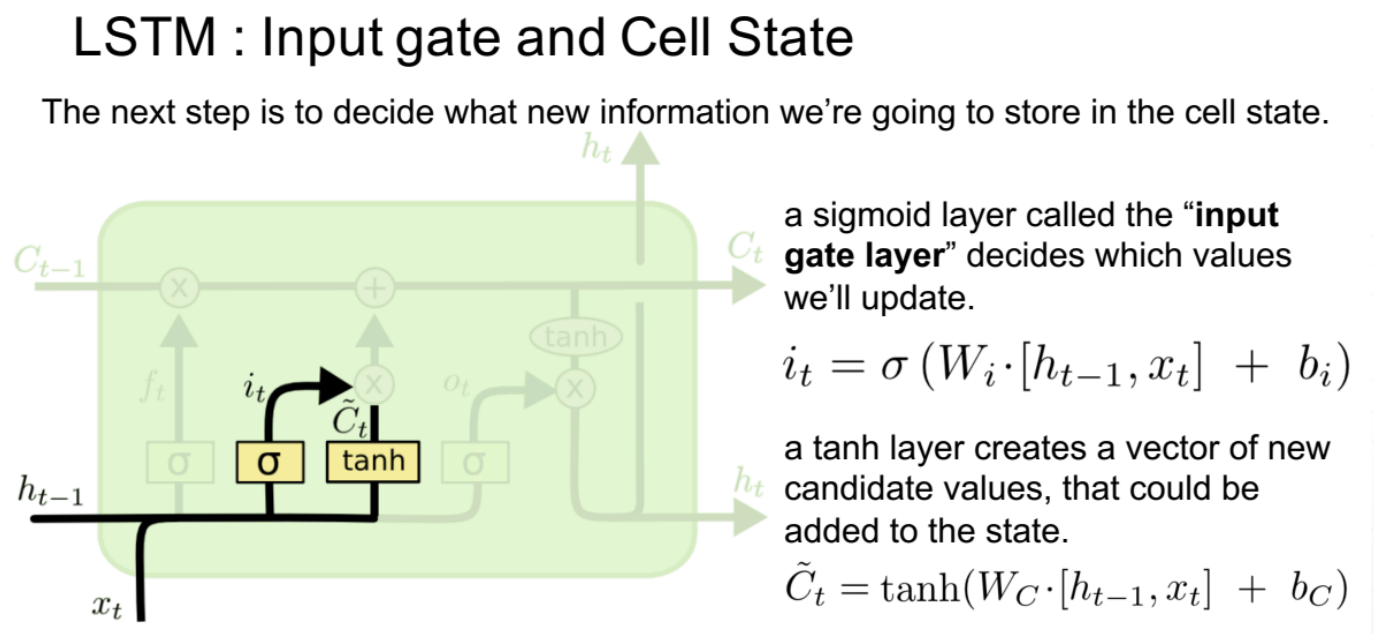
输入门的值

ct是memory,ht是隐藏层的输出
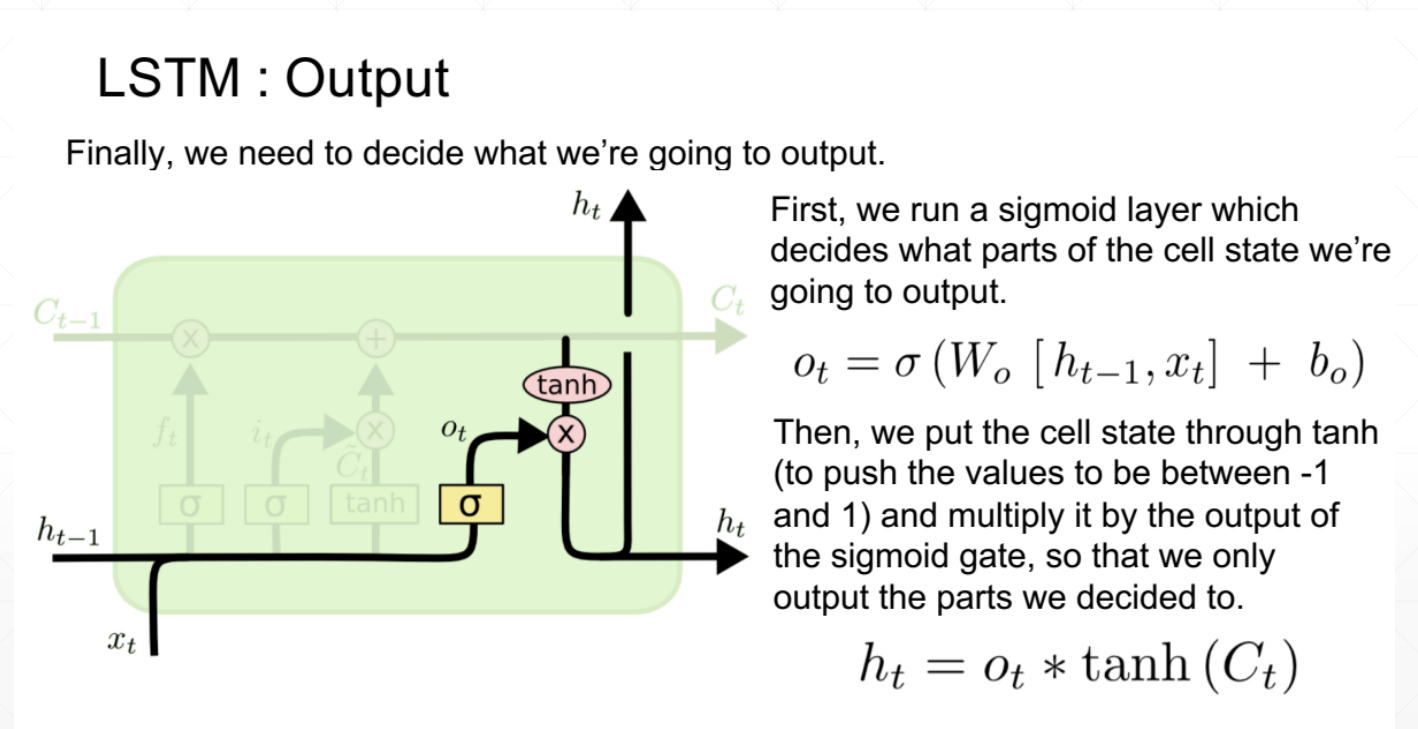
3、输出值
同样是由开度和ct共同决定的,ot作为开度也是由算法决定的
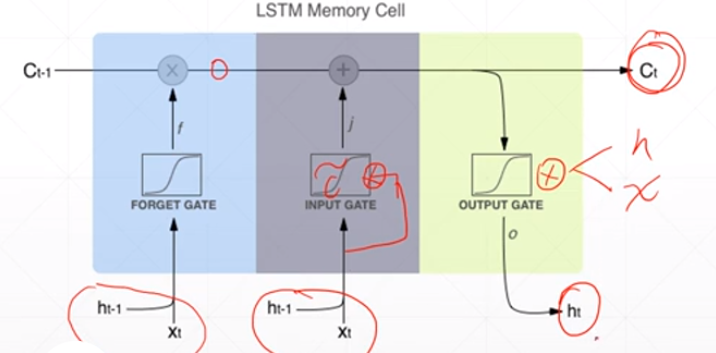
LSTM如何解决梯度离散的问题呢?
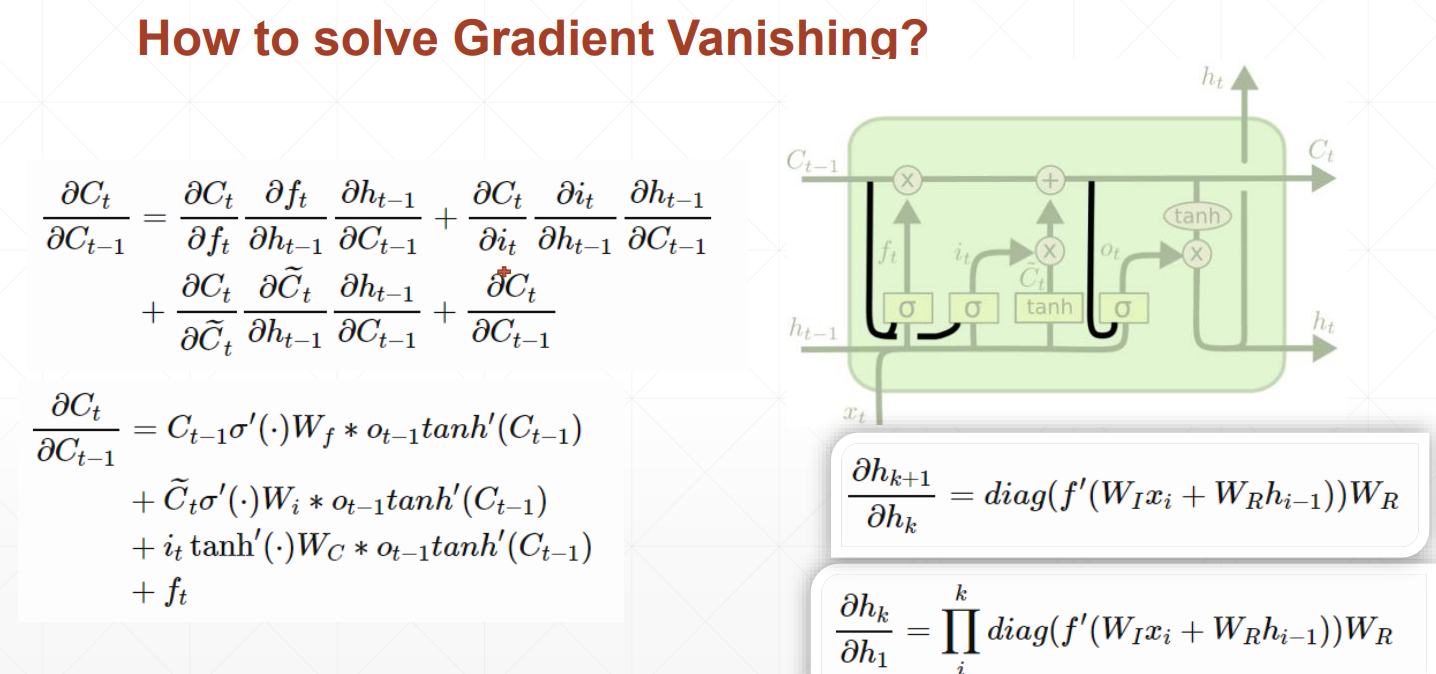
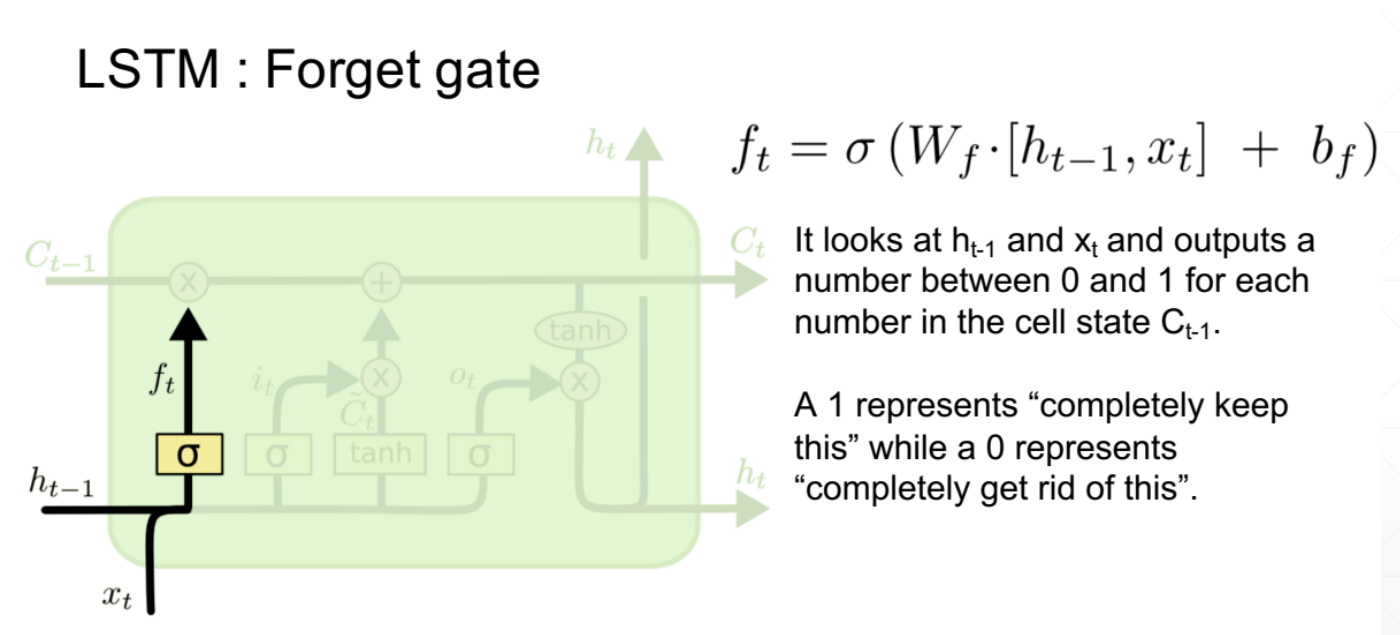
由于存在忘记门、输入门和输出门三个门
当前隐藏层对前一个隐藏层求导时,出现三个值相加的情况,不容易出现都是大或都是小的情况,数值相对可靠,所以效果相对来说更好一些。


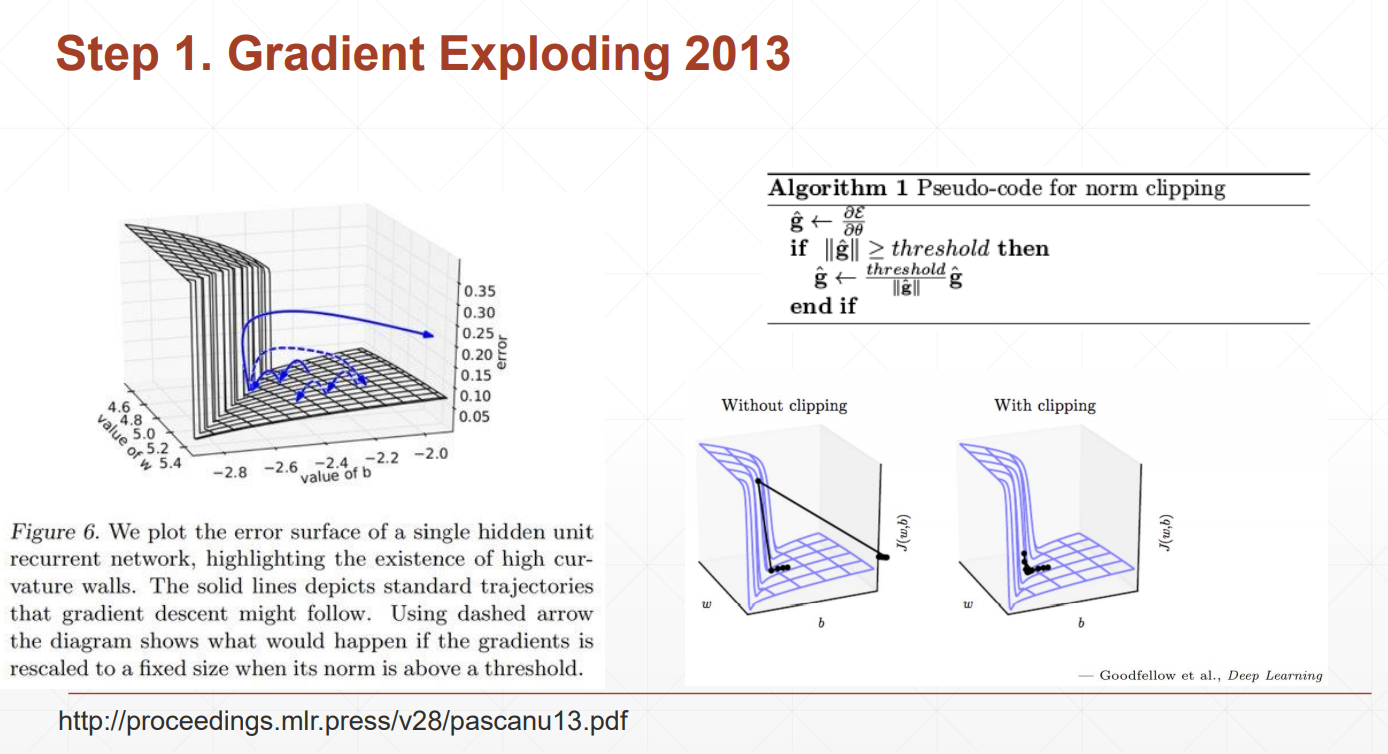



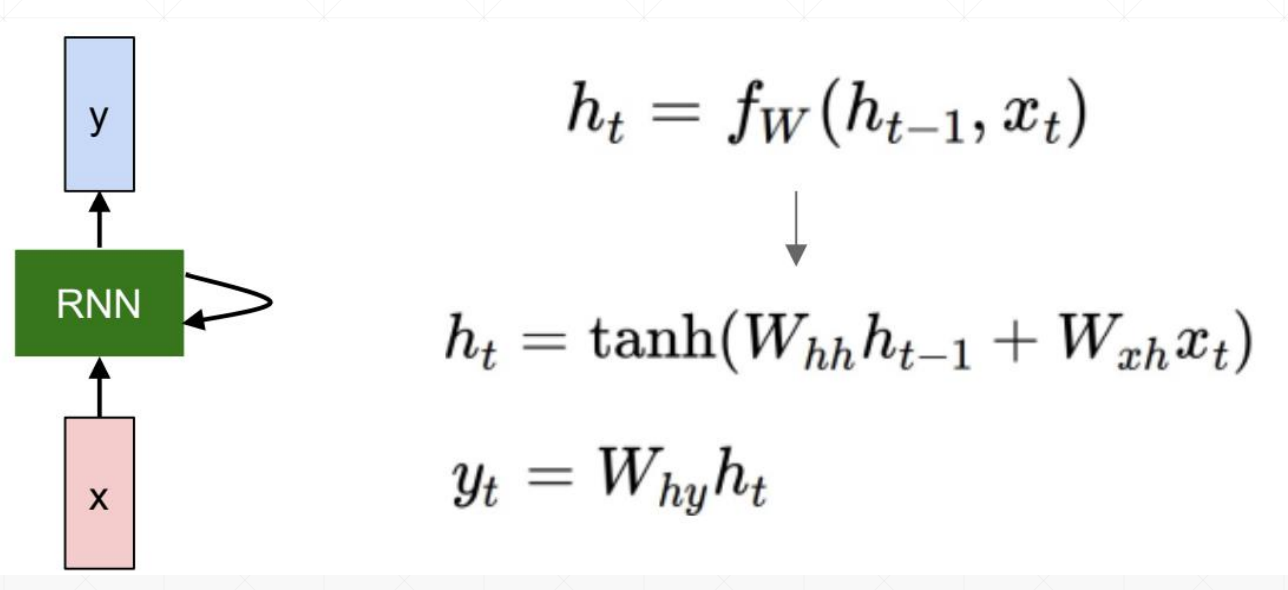












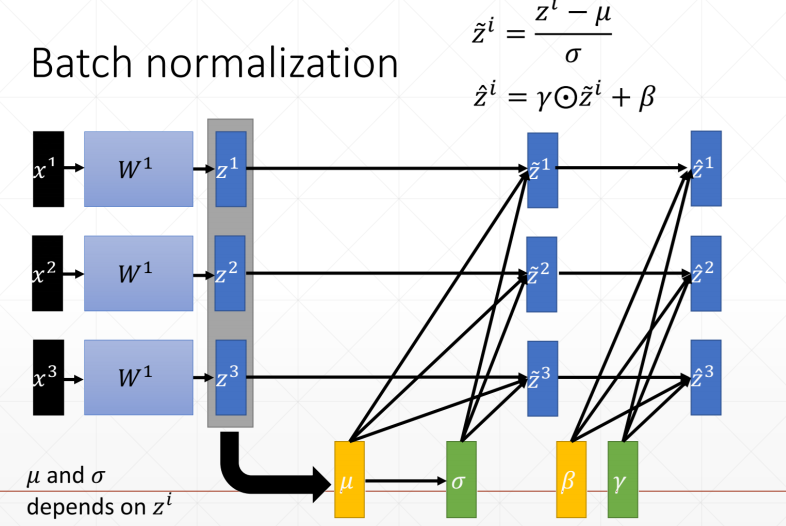
 我们主要学习Batch normalization以通道为基准,计算每个通道上的均值和方差,然后通过减均值除以方法来使这些值均匀得分布在某个范围内
我们主要学习Batch normalization以通道为基准,计算每个通道上的均值和方差,然后通过减均值除以方法来使这些值均匀得分布在某个范围内