- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集可以没有目标值)
- 样本:一组数据也可以称为一个样本。
- 数据中对于特征的处理:
1. pandas:工具。数据读取非常方便,可以处理数据的基本格式
2. sklearn:可以对特征进行处理——这类处理被称为特征工程。
# 机器学习不需要对样本进行去重
【特征工程】
- 特征工程是将原始数据转换为能更好地代表预测模型的潜在问题的特征的过程,从而提高对未知数据的预测准确性
- 安装scikit-learn


- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集可以没有目标值)
- 样本:一组数据也可以称为一个样本。
- 数据中对于特征的处理:
1. pandas:工具。数据读取非常方便,可以处理数据的基本格式
2. sklearn:可以对特征进行处理——这类处理被称为特征工程。
# 机器学习不需要对样本进行去重
【特征工程】
- 特征工程是将原始数据转换为能更好地代表预测模型的潜在问题的特征的过程,从而提高对未知数据的预测准确性
- 安装scikit-learn
- 机器学习的数据:文件 csv
- 不用mysql的原因:
1. 具有性能瓶颈、读取速度慢
2. 格式不符合机器学习要求数据的格式
- pandas:读取数据的工具
- numpy(读取速度快)
- 可用数据集:Kaggle、UCI、scikit-learn
- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集没有目标值)
- 什么是机器学习:数据中自动分析获得规律(模型),利用规律对未知数据进行预测
- 影响人工智能发展的重要因素:计算能力、数据大小、算法发展
- 使用场景:无人驾驶的场景识别、图片艺术化、医用彩超辨别、需求销量等数据预测
- 机器学习领域:自然语言处理、图像识别、传统预测
- 机器学习库和框架:scikit learn(机器学习)、tensorflow(深度学习)
- 书籍:统计学习方法、机器学习、python数据分析与挖掘实战、机器学习系统设计、面向机器智能tensorflow实践
- 课程概要:特征工程、模型策略优化、分类回归聚类、tensorflow、神经网络、图像识别、自然语言处理
sudo进行用户切换。
$一般账户
#超级管理员
微信,如何实现多用户操作?
whoami我是哪个账户。
exit切回去。
which ls
python不适用的场景为效率性能要求较高的场景。c/go/java/c++都比他性能高。
cat显示文件内容
mv重新命名文件名移动
ln链接快捷键
ln -硬链接相当于复制
cat 1 2》3
把1和2合并到3里。
grep搜索
ls显示文件
cp复制粘贴
-r解决文件夹不让动。
rmdir 删除文件夹
rm -r可以删非空文件
ctrl+c删除命令行。
mkdir创建文件夹
tree以目录树的方式显示文件夹
-p自动创建文件夹
for 遍历所有数值
print(输出便利数值)
for x in 数值
print()
海龟绘图我pycharm无法输出
关键字,不能作为变量名,使用help()查看关键字,变量以字母或者下划线开头,后接字母下划线数字
字符串的变量
可用 == 和 is 来判断是否是同个id
只有包含下划线字母数字的字符才能进入驻留,特殊符号不可以,所以id会发生变化。
字符串成员操作符: in , not in
1.split(x) 以'x'为界限分割字符串 x可以是空格,单字符,多字符
2.‘x’.join(y) y中的字符串,以x为分隔,拼接成一个大字符串
使用【:】取字符串的片段
[:]:取全部
[2:]从第三个位置到最后
[2:5]从第三个位置到第五个位置 注:包头不包尾
[1:5:x] 在位置1:5之间每隔x取一个
也可以用'-'号进行反向取值,同样包头不包尾
[::-1],反向排
1.str() 注:转化数据为字符串
2.通过[]提取字符串 注:第一个字符为0,最后一个字符为len(str)-1,既可以正向提取,也可以反向向提取
3.replace在字符串中的应用
例:a = 'xy'
a.replace('x','y')
print(a)
输出: 'yy'
1.转义符号的使用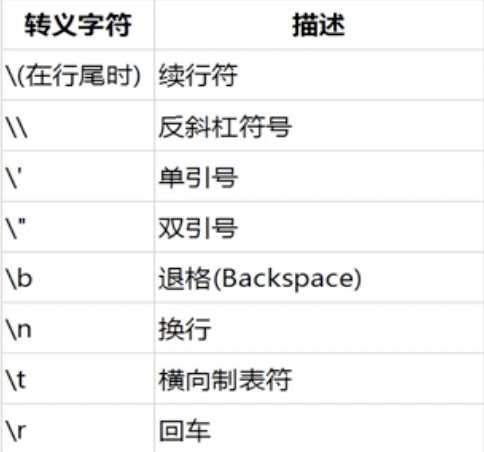
2.字符串可通过+进行拼接操作(需两个为字符串)
3.字符串可通过*号进行复制
4.通过end=“”,来避免换行
使用 input()从控制台读取键盘输入内容
myname = input('请输入名字:')
请输入名字:x
print(myname)
输出 'x'