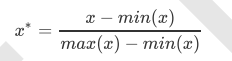StandardScaler
当数据(x)按均值(μ)中心化后,再按标准差(σ)缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分 布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下:
对于StandardScaler和MinMaxScaler来说,空值NaN会被当做是缺失值,在fit的时候忽略,在transform的时候 保持缺失NaN的状态显示。
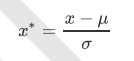
并且,尽管去量纲化过程不是具体的算法,但在fit接口中,依然只允许导入至少二维数 组,一维数组导入会报错。通常来说,我们输入的X会是我们的特征矩阵,现实案例中特征矩阵不太可能是一维所以不会存在这个问题。
StandardScaler和MinMaxScaler选哪个?
大多数机器学习算法中,会选StandardScaler来进行特征缩放,因为MinMaxScaler对异常值非常敏感。