

【分类模型的评估标准】
【准确率】
estimator.score():一般最常见使用的是准确率,及预测结果正确的百分比
【混淆矩阵】
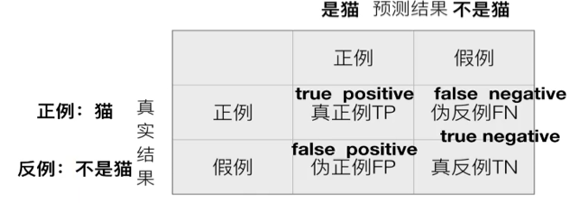
在分类任务下,预测结果和正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多酚类)
 【精确率】
【精确率】
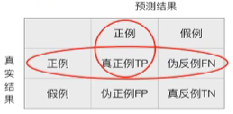
预测结果为正例的样本中,真实为正例的比例(查得准)

【召回率】
真实为正例的样本中,预测结果为正例的比例(查的全,对正样本的区分能力)
【分类模型评估API】
sklearn.metrics.classification_report (y_true, y_predict, target_names = None)
- y_true:真实目标值
- y_predict:估计器预测目标值
- target_names:目标类别名称
- return:每个类别精确率与召回率
