n_estimators基评估器数量,该值越大,越好。
到达一定程度后,精确性会开始波动。


n_estimators基评估器数量,该值越大,越好。
到达一定程度后,精确性会开始波动。
集成算法:在数据上构建多个模型,集成所有模型的建模结果。
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果。
集成评估器:基评估器,装袋法,提升法,stacking
sklearn中的ensemble,集成算法有一半以上都是树的模型。决策树用于分类和回归问题。通过有特征和标签的表格中,通过对特定特征进行提问,总结出决策规则。
如何找到正确的特征去提问,定义衡量分支质量的指标不纯度。
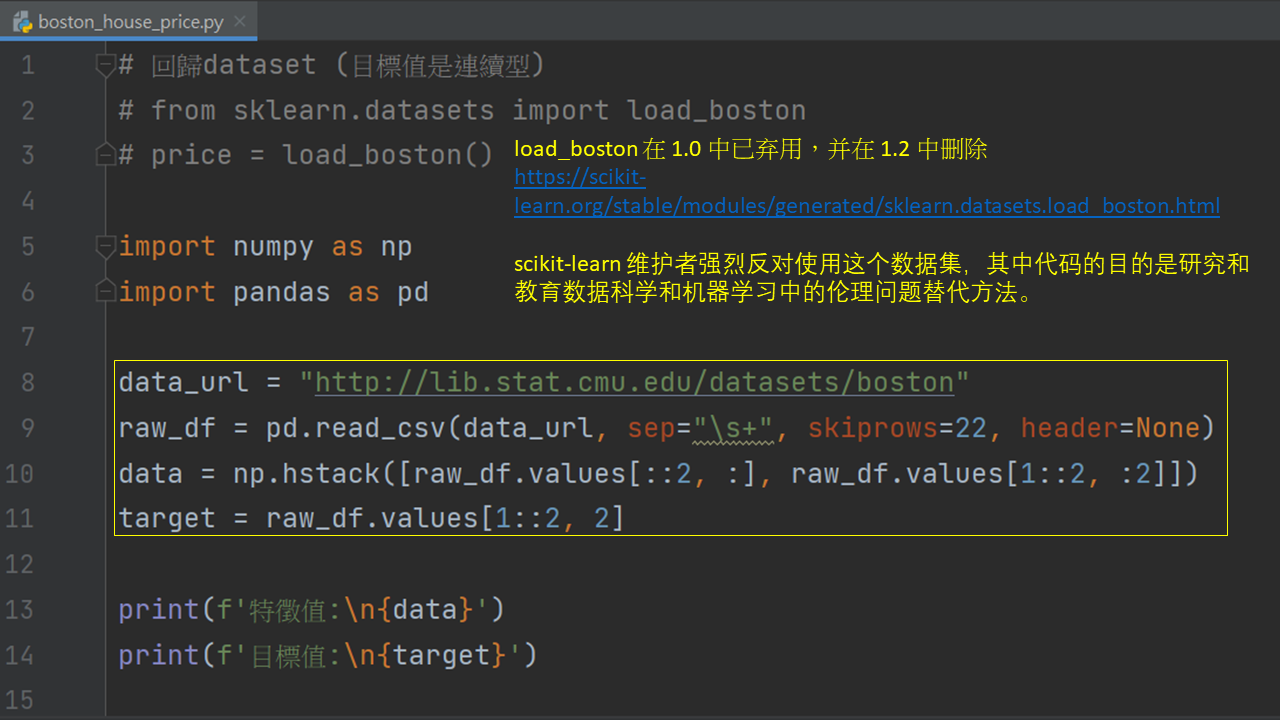
load_boston 在 1.0 中已弃用,并在 1.2 中删除
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html
scikit-learn 维护者强烈反对使用这个数据集,其中代码的目的是研究和教育数据科学和机器学习中的伦理问题替代方法。
Imputer, 已更新很久了
课程是旧版本, 我为新版本稍作说明

as a reminder for classmates, currently we use 'sklearn' rather than 'scikit-learn' in coding ;)
機器學習推薦書:
1. 機器學習 (西瓜書)
2. Python數據分析與挖掘實戰
3. 機器學習系統設計
4. 面向機器智能TensorFlow實戰
5. TensorFlow技術解析與實戰
如何修改
机器学习简介
机器学习、深度学习可以做什么?
(自然语言处理、图象识别、传统预测)
机器学习库和框架
scikit learn、TensorFlow
课程定位:
以算法、案例为驱动的学习,浅显易懂的数学知识
注意:参考书比较晦涩难懂,不建议直接读
课程目标:
熟悉机器学习各类算法的原理
掌握算法的使用,能够结合场景解决实际问题
掌握使用机器学习算法库和框架
机器学习课程
特征工程;模型、策略、优化,分类、回归和聚类,TensorFlow,神经网络,图象识别,自然语言处理
sklearn中的信息熵,实际上是信息增益。即父节点的信息熵-子节点的信息熵。
非参数:即不限制数据结构和类型
有监督:有标签
二阶导数是凸函数?
SymPy 符号运算包 函数运算
1.O表示多项式的阶
2.o (n)
from pyplot as plt 重命名,简化
temperature是气温, 100度很吓人啦 XD
啊深度啊收到卡后
老师的卷发就到了发掘了深刻的
numpy读取数据
np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
转置t.T()
t1.reshape(1,24) #修改数组形状
t1.flatten() #展开 二维降成一维
t1+2 #数组每个值都加2 (广播机制)
0除以0得到nan(不是一个数字),其他数字除以0得到inf(无穷的意思)
t6+t5 #对应位置的数据计算
matplotlib