缩进 表示逻辑层次 组织结构
行注释#
段注释‘‘‘


缩进 表示逻辑层次 组织结构
行注释#
段注释‘‘‘
建立python源文件
打开python
文件 新建 保存
不能随便加空格
1.IDE开发环境 集成开发环境
IDLE
pycharm
wingIDE
Eclipse
Ipython
python
cril+Z
quit()
死循环 中段 while True:
print(‘i love u’)
cril+C中段

需要四步:
(1)load data
(2)build model
(3)train
(4)test
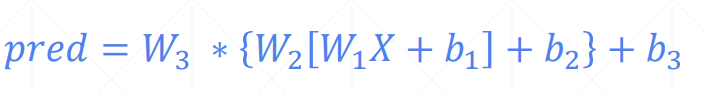
Non-linear Factor
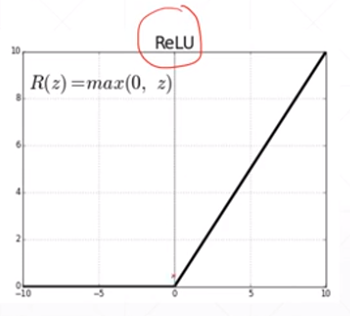
加入激活函数之后

pred既有线性表达能力,还有非线性的表达能力

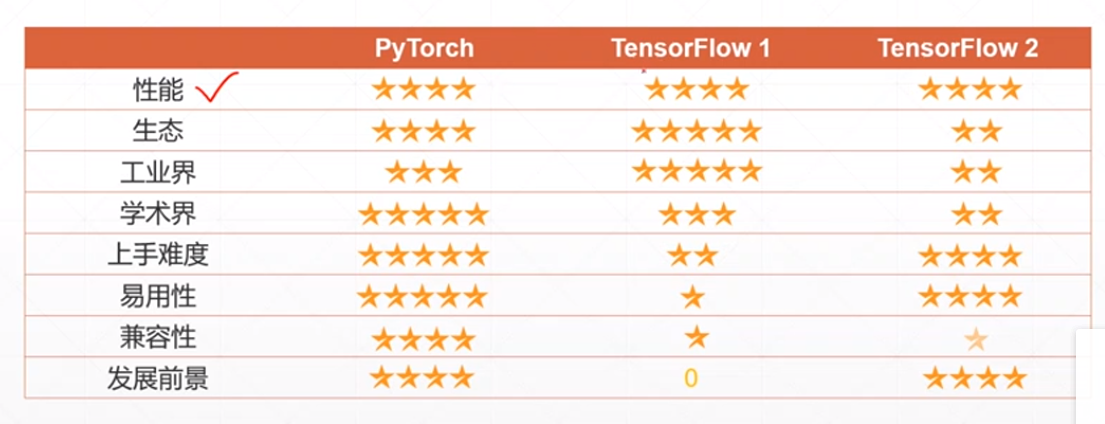
pytorch的功能:
(1)CPU加速;
没有显卡,用不了cuda
(2)自动求导*非常重要,因为深度学习本质上就是在利用梯度下降法来求最优解;
(3)常用网络层


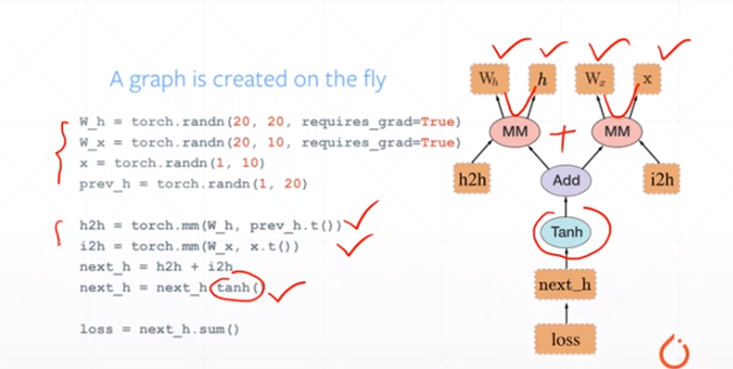
静态图:
define——>run
在最开始就需要定义好公式,给定输入值,得到输出值,而且在运行的过程中无法进行调整

动态图:
可以随时调整公式
linear Regression——我们要估计连续函数的值;
logistic Regression——在上述linear regression的基础上增加了一个激活函数,把y的空间压缩到0-1的范围,0-1可以表示一个概率
classification——所有的可能性概率之和为1
构造函数__init__()
类是抽象的,通过类这个模板,创建类的实例对象,然后使用类定义的功能
对象包含如下部分:
1. id
2. type
3. value
3.1 属性
3.2 方法
__init__()的要点如下:
1. 名称固定,必须为:__init__()
2. 第一个参数固定,必须为:self。
self 指的就是刚刚创建好的实例对象。
3. 构造函数通常用来初始化实例对象的实例属性,如下代码就是初始化实例属性:name
和 score。
def __init__(self,name,score):
self.name = name #实例属性
self.score = score
4. 通过“类名(参数列表)”来调用构造函数。调用后,将创建好的对象返回给相应的变量。
比如:s1 = Student('张三', 80)
5. __init__()方法:初始化创建好的对象,初始化指的是:“给实例属性赋值”
6. __new__()方法: 用于创建对象,但我们一般无需重定义该方法。
7. 如果我们不定义__init__方法,系统会提供一个默认的__init__方法。如果我们定义了带参
的__init__方法,系统不创建默认的__init__方法。
注:
1. Python 中的 self 相当于 C++中的 self 指针,JAVA 和 C#中的 this 关键字。Python 中,
self 必须为构造函数的第一个参数,名字可以任意修改。但一般遵守惯例,都叫做 self。
类的定义
类定义数据类型的属性和方法
定义类的语法格式:
class 类名:
类体
要点如下:
1. 类名必须符合‘标识符’的规则;一般规定,首字母大写,多个单词使用‘驼峰原则’
2. 类体中我们可以定义属性和方法。
3. 属性用来描述数据,方法(即函数)用来描述这些数据相关的操作
对象的进化
1. 简单数据
类似30,40,50.5这样的数字
2. 数组
同类型的数据放在一起。
3. 结构体
不同类型的数据放在一起,C语言中的数据结构。
4. 对象
将不同类型的数据、方法(函数)放到一起。
用class方法
面向对象
面向对象编程将数据和操作数据的方法封装到对象中,组织代码和数据的方式更接近人的思维。
python支持面向过程、面向对象,函数式编程等
面向过程POP
面对过程更加关注流程,按照步骤实现。适合小规模程序。
面向对象OOP
关注对象之间的关系,适合编写大规模程序。
先找名词,再找动词
LEGB规则
python查找名称时,按照LEGB规则查询
Local 函数或者类的方法内部
Enclosed 嵌套函数,闭包
Global 全局变量
Built in Python为自己保留的特殊名称
def outer():
str="outer"
def inner()
str="inner"
print(str)
pass
inner()
outer()
global声明全部变量
nonlocal申明外部函数的局部变量
嵌套函数(内部函数)
嵌套函数:
在函数内部定义的函数
1.封装-数据隐藏
2.避免函数内部重复代码
3.闭包
数据降维
1.特征选择
2.主成分分析
MinMaxScaler(feature_range=())
feature_range 可以指定在一定的数值范围内
tf idf
tf:term frenquency词的频率 出现的次数
idf:inverse document frequency 逆文档频率
log(总文档数量/该词出现的文档数量)
重要性程度
countvectorizer没有参数
文本都是放在列表里面的可迭代对象
性能瓶颈,读取速度
格式不太符合机器学习要求数据的格式
可用数据集:
Kaggle
UCI
scikit-learn