/windows有分盘
而linux没有分盘。在直接用
除了home文件夹,其它的都不用动
只有第一个/才能称之为根目录


/windows有分盘
而linux没有分盘。在直接用
除了home文件夹,其它的都不用动
只有第一个/才能称之为根目录
tree 的命令
Linux内核有几千万行代码
Linux发行版本
Android 是Linux kernel外面封装一圈java程序
桌面环境,是win的天下
操作系统,就是让多个程序一起执行
所谓的并发,莫过如此
Android的本质,就是linux
kernel是整个操作系统,最核以的东西
LINUX kernel 封装了java的东西,就是Android
Unix是整个OS的鼻祖
用同一门语言,运行在联想的电脑上,与华硕的电脑上,运行的结果不一样。
叫做跨硬件平台性比较差。
BCPL的第二个字母作为这种语言的名字,这就是C语言
C语言的主体完成,Thompson和Ritchie迫不及待地开始用它完全重写现在大名鼎鼎的Unix
迭代:已有版本,开发一个新的版本,称之为迭低
开源与闭源
他以小型UNIX(mini-UNIX)之意,将它称为MINIX
mini-Unix 用来教学
汽车导航:默认出厂的WIN CE
Android主要运行在移动端
win10 主要在PC上,个人电脑上
操作系统为自己控制硬件
什么是操作系统
操作系统OS
软件,能够直接控制硬件,向上支持应用软件使用
没有操作系统的
应用层软件,
开发环境:IDLE、pycharm……

官方:www.python.org
- 线性回归需要标准化
决策树的分类依据之一
信息增益
【分类模型的评估标准】
【准确率】
estimator.score():一般最常见使用的是准确率,及预测结果正确的百分比
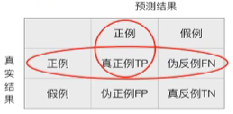
【混淆矩阵】
在分类任务下,预测结果和正确标记之间存在四种不同的组合,构成混淆矩阵(适用于多酚类)
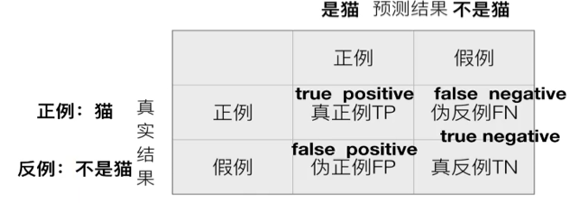 【精确率】
【精确率】
预测结果为正例的样本中,真实为正例的比例(查得准)

【召回率】
真实为正例的样本中,预测结果为正例的比例(查的全,对正样本的区分能力)
【分类模型评估API】
sklearn.metrics.classification_report (y_true, y_predict, target_names = None)
- y_true:真实目标值
- y_predict:估计器预测目标值
- target_names:目标类别名称
- return:每个类别精确率与召回率
朴素贝叶斯案例流程
1. 加载新闻数据,并进行分割
2. 生成文章特征词
3. 朴素贝叶斯流程进行预估
K近邻算法:相似的样本,特征之间的值应该都是相近的
k近邻算法:需要做标准化处理
【转换器】
fit_transform():输入数据并直接转换
fit():输入数据,但不做其他事
transform():进行数据的转换
【估计器】是一类实现了算法的API
1. 用于分类的估计器:
-- sklearn.neighbors
-- sklearn.naive_bayes
-- sklearn.linear_model.LogiscRegression
-- sklearn.tree
2. 用于回归的估计器
-- sklearn.linear_model.LinearRegression
-- sklearn.linear_model.Ridge
估计器流程
1、调用训练集:fit(x_train, y_train)
2、输入待预测的测试集数据:
2.1、y_predict = predict( x_test)
2.2、验证预测的准确率:score( x_test, y_test)
【sklearn 数据集】
- 数据集的划分:将数据集划分为训练集(建立模型)和测试集(评估模型)
- sklearn数据集划分API:sklearn.model_selection.train_test_split
--sklearn.datasets:加载获取流行数据集
1. datasets.load_*():获取小规模数据集,数据包含在datasets中
2. datasets.fetch_*(data_home=None):获取大规模数据集
--获取数据集返回的类型为datasets.base.Bunch(字典格式)
---data:特征数据数组,是 [n_samples*n_features] 的二维 numpy.ndarray 数组
---target:标签数组
---DESCR:数据描述
---feature_names:特征名
---target_names:标签名
-
-数据类型
1. 离散数据类型(计数数据):区间内不可分,整数,不能进一步提高精确度
2. 连续性数据:区间内可分,通常为非整数。变量可以在某个范围内任取数。
- 机器学习算法分类
1. 监督学习(预测):特征值+目标值
1.1 分类(目标值为离散型):k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
1.2 回归(目标值为连续型):线性回归、岭回归
1.3 标注:隐马尔科夫模型
2. 非监督学习:特征值
2.1 聚类 k-means
- 特征抽取:将文本等原始数据转化为特征向量的形式
- 常用数据集数据的结构组成:特征值 + 目标值(有些数据集可以没有目标值)
- 样本:一组数据也可以称为一个样本。
- 数据中对于特征的处理:
1. pandas:工具。数据读取非常方便,可以处理数据的基本格式
2. sklearn:可以对特征进行处理——这类处理被称为特征工程。
# 机器学习不需要对样本进行去重
【特征工程】
- 特征工程是将原始数据转换为能更好地代表预测模型的潜在问题的特征的过程,从而提高对未知数据的预测准确性
- 安装scikit-learn