1.split(x) 以'x'为界限分割字符串 x可以是空格,单字符,多字符
2.‘x’.join(y) y中的字符串,以x为分隔,拼接成一个大字符串


1.split(x) 以'x'为界限分割字符串 x可以是空格,单字符,多字符
2.‘x’.join(y) y中的字符串,以x为分隔,拼接成一个大字符串
使用【:】取字符串的片段
[:]:取全部
[2:]从第三个位置到最后
[2:5]从第三个位置到第五个位置 注:包头不包尾
[1:5:x] 在位置1:5之间每隔x取一个
也可以用'-'号进行反向取值,同样包头不包尾
[::-1],反向排
1.str() 注:转化数据为字符串
2.通过[]提取字符串 注:第一个字符为0,最后一个字符为len(str)-1,既可以正向提取,也可以反向向提取
3.replace在字符串中的应用
例:a = 'xy'
a.replace('x','y')
print(a)
输出: 'yy'
1.转义符号的使用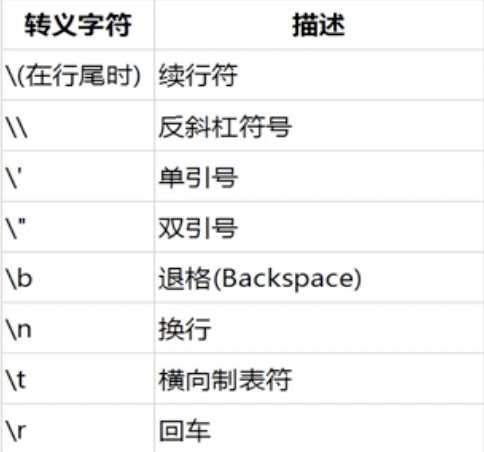
2.字符串可通过+进行拼接操作(需两个为字符串)
3.字符串可通过*号进行复制
4.通过end=“”,来避免换行
使用 input()从控制台读取键盘输入内容
myname = input('请输入名字:')
请输入名字:x
print(myname)
输出 'x'
1.同一运算符:is ,is not
区别:is判断的是地址
==判断的是值
注:在-5,256之间数值会缓存,所以id是相同的,不同解释器不同
1.布尔值本质是1和0
2.布尔值的比较运算符:等于,不等于,大于,小于,大于等于,小于等于
返回:True和False
3.逻辑运算符:或or,与and,非not
https://cloud.189.cn/t/EBF
### sys.path和模块搜索路径
按下面的顺序从上往下搜索
1.内置模块
2.当前目录
3.程序的主目录
4.Pythonpath目录(如果已经设置Pythonpath环境变量)
5.标准链接库目录
6.第三方库目录
7..pth文件的内容(如果存在的话)
8.sys.path.append()临时添加的目录
### 包的本质和init文件——批量导入
__init__.py的三个核心作用:
1.作为包的标识,不能删除
2.用来实现模糊导入
3.导入包实质是执行__init__.py文件,可以在__init__.py文件中做这个包的初始化,以及需要统一执行代码,以及批量导入
### 用*导入包
import*会把子模块全部导入,生产中不建议使用
### 包内引用
from..importmodule_a #..表示上级目录
from.import module_A2 #.表示同级目录
##包的内容
### 导入包操作
导入和使用时要写上包名
#import my01.aa.module.A #from my01.aa.module.A import fun_aa
### __import__()函数的动态导入
import importlib用于动态导入
## 模块的导入
### import 语句
import 模块名
import 模块1,模块2...
import 模块名 as 模块别名
## 模块
### 模块化程序思维
### 递归的目录树结构
## 递归
### 递归算法原理(阶乘计算)
#### ziopfile模块 压缩和解压缩
shutil模块(拷贝和压缩)
#### os模块 使用walk遍历
os.path模块——常用方法
#### os模块——文件和目录操作
常用操作文件的方法:
1.remove(path)删除指定文件
2..rename(src,dest)重命名
3.stat(path)返回文件所有属性
4.listdir(path) 返回path目录下的文件和目录列表
关于目录操作的相关方法:
1.madir(path) 创建目录
2.makedirs(path1/path2..)创建多级目录
3.rmdir(path)删除目录
4.removedirs(path1/path2...)删除多级目录
5.getcwd()返回当前工作目录:current work dir
6.chdir(path) 把path设为当前目录
7.walk()遍历目录树
8.sep当前操作系统所使用的路径分隔符