多分支选择结构
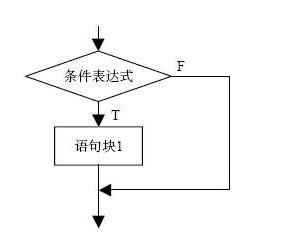
if 条件表达式1 :
语句1/语句块1
elif 条件表达式2:
语句2/语句块2
.
.
elif 条件表达式n :
语句n/语句块n
[else:
语句n+1/语句块n+1
]
score = int(input("请输入分数"))
grade = ''
if(score<60):
grade = "不及格"
elif(score<80): #按逻辑写 别写反
grade = "及格"
elif(score<90):
grade = "良好"
else:
grade = "优秀"
print("分数{0},等级{1}".format(score,grade))